الرؤية المستقبلية - سي لاما (لاما.cpp) (متقادم)
مهمل
تم تحديد Cllama على أنها مهجورة ولن يتم صيانتها بعد الآن.
تم توفير الوظائف الأصلية لـ Cllama بواسطة CllamaServerلتحمل.
نموذج غير متصل
Clama مبنية على llama.cpp، وتدعم استخدام نماذج استنتاج الذكاء الاصطناعي دون اتصال بالإنترنت.
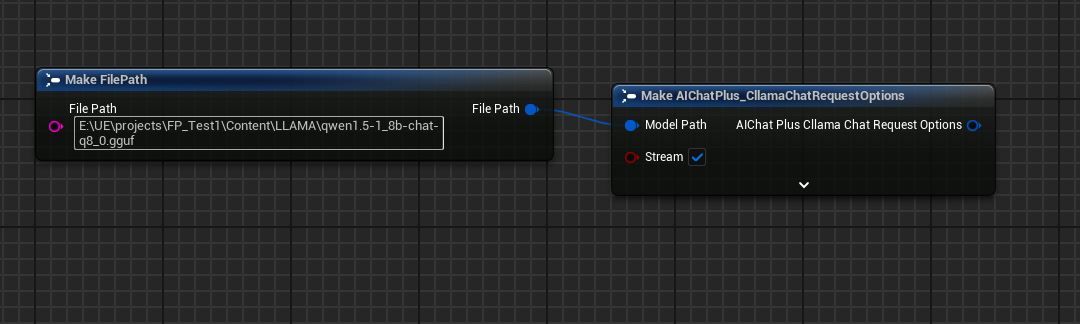
نظرًا لأن العملية بدون اتصال، نحتاج إلى تحضير ملف النموذج مسبقًا، مثل تنزيل نموذج غير متصل من موقع HuggingFace: Qwen1.5-1.8B-Chat-Q8_0.gguf
ضع النموذج في مجلد معين، على سبيل المثال تحت دليل مشروع اللعبة في مسار Content/LLAMA
بعد الحصول على ملفات النموذج بدون اتصال، يمكننا استخدام Cllama لإجراء محادثات الذكاء الاصطناعي
المحادثة النصية
استخدام Cllama للدردشة النصية
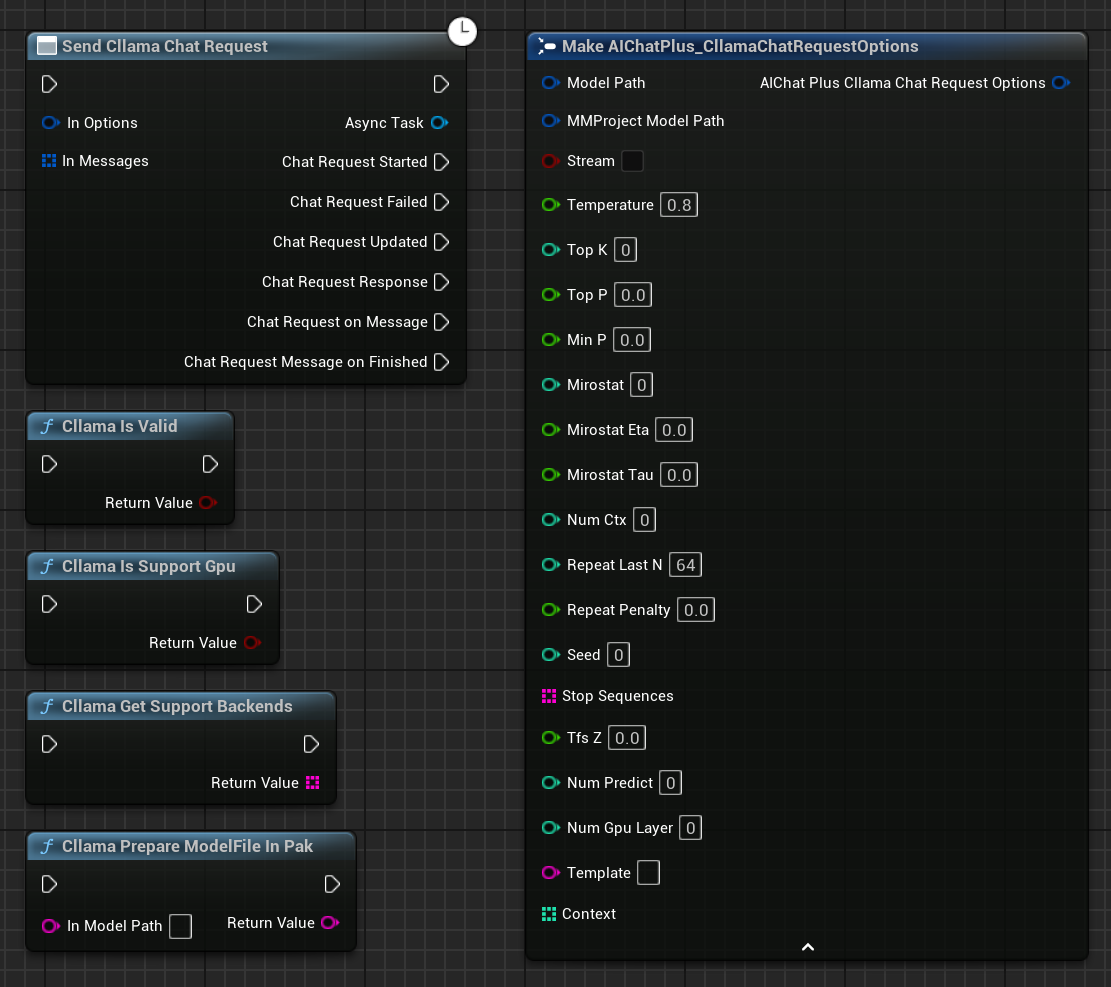
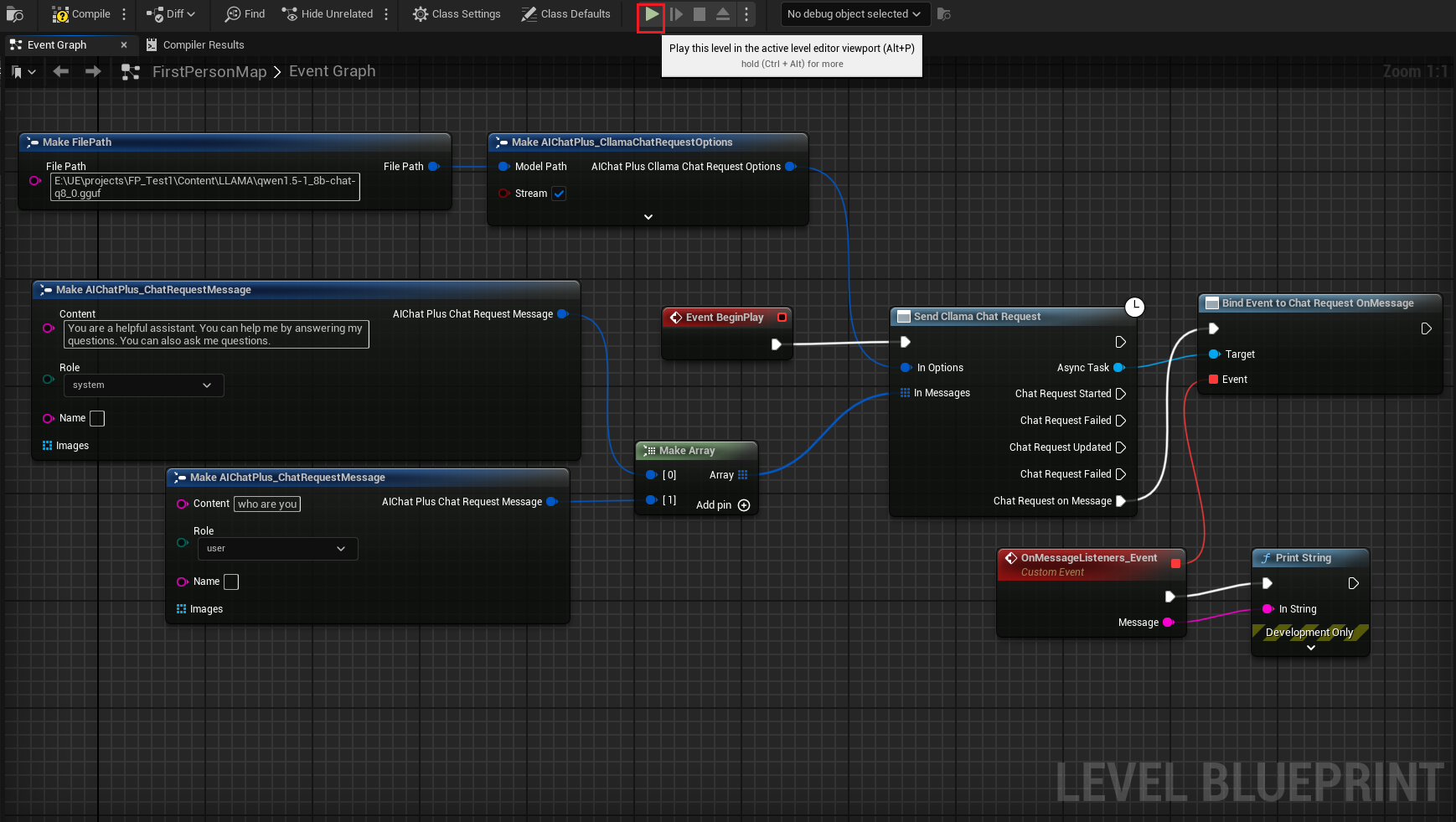
انقر بزر الماوس الأيمن في المخطط لإنشاء عقدة تُسمى Send Cllama Chat Request
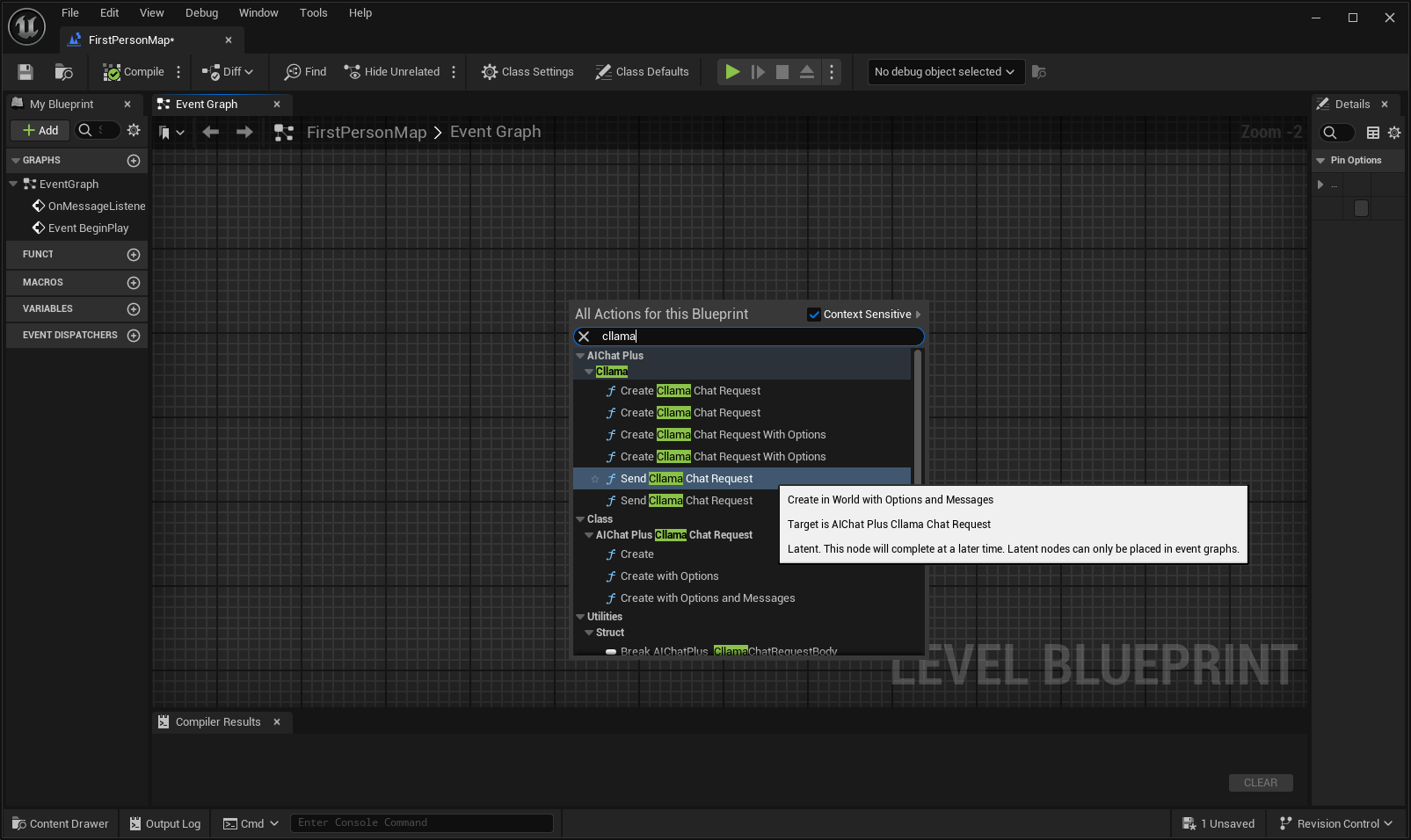
إنشاء عقدة Options وتعيين Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
إنشاء رسائل، إضافة رسالة نظام ورسالة مستخدم بشكل منفصل
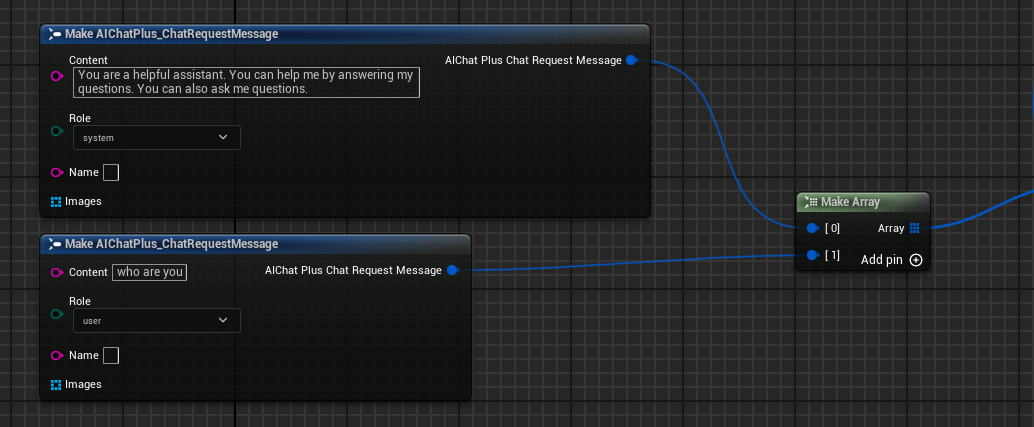
إنشاء مُفوّض يَتلَقّى مُخرَجات النموذج ويُطبعها على الشاشة
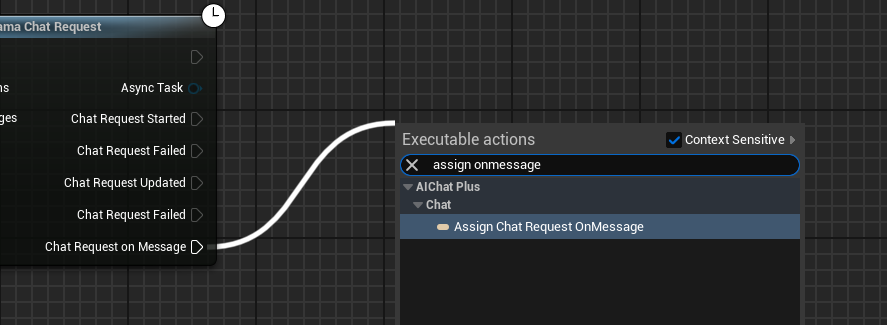
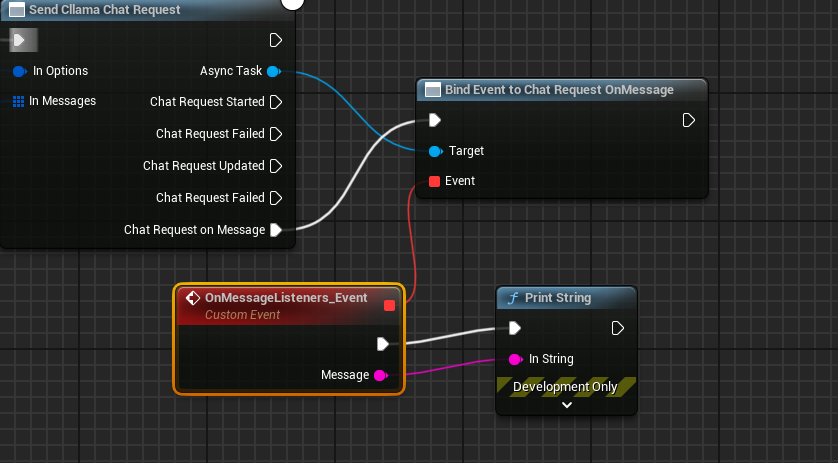
تبدو الخريطة الكاملة هكذا، قم بتشغيل الخريطة وسوف ترى شاشة اللعبة وهي تطبع الرسالة التي يعيدها النموذج الكبير
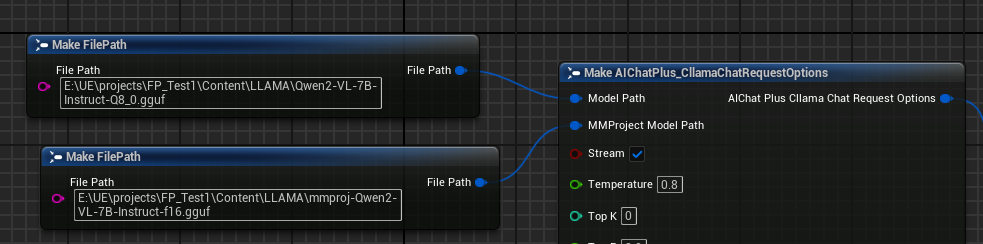
إنشاء النصوص من الصور ليافا
يدعم Cllama أيضًا مكتبة llava تجريبيًا، مما يوفر قدرات Vision.
أولاً، قم بإعداد ملفات نموذج Multimodal دون اتصال، مثل Moondream (moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf) أو Qwen2-VL (Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf) أو أي نموذج متعدد الوسائط آخر تدعمه llama.cpp.
إنشاء عقدة Options، وتعيين المعلمات "Model Path" و"MMProject Model Path" إلى ملفات النموذج متعدد الوسائط المقابلة.
إنشاء عقدة لقراءة ملف الصورة flower.png، وتحديد الرسائل

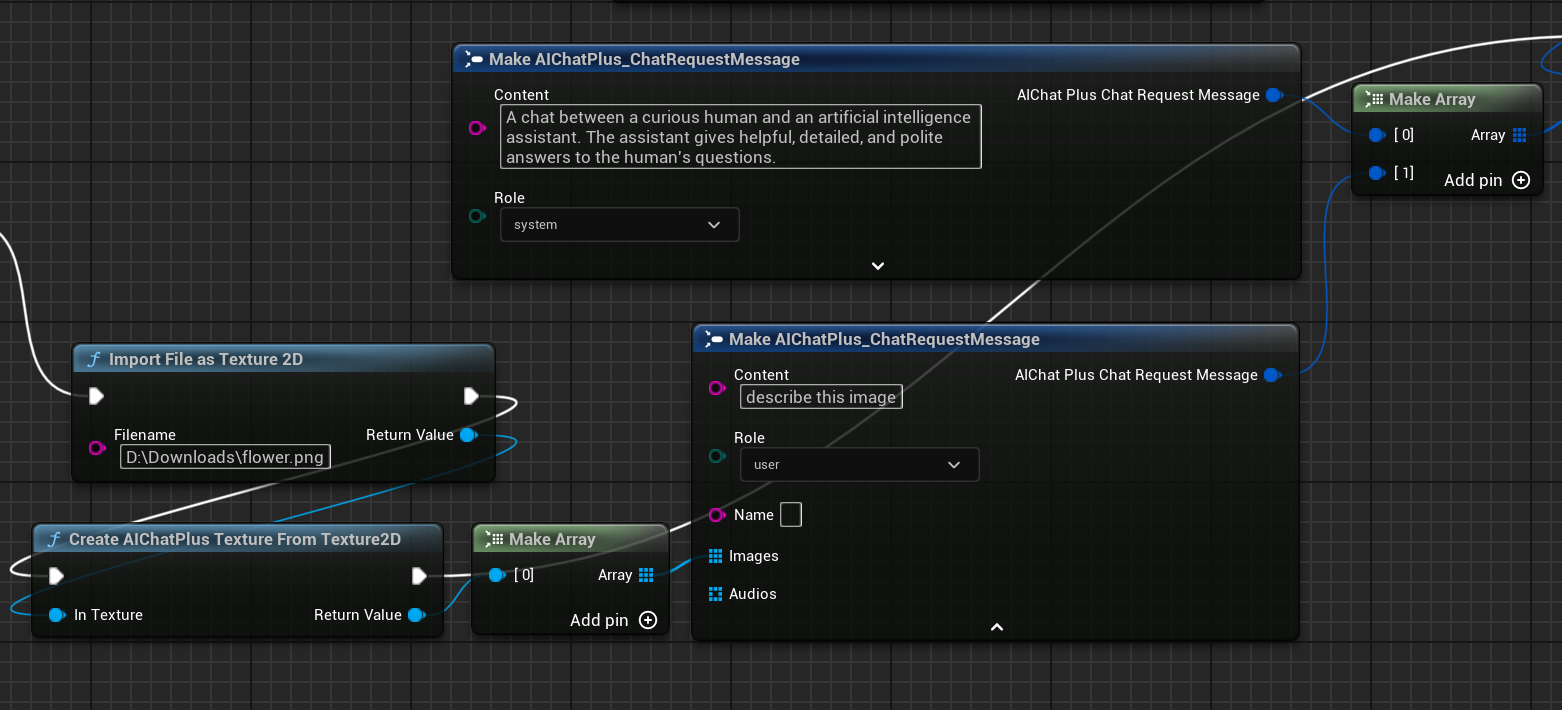
أخيرًا يأخذ العقدة المُنشأة المعلومات المرتجَعة ويطبعها على الشاشة، تبدو الخطة الكاملة هكذا
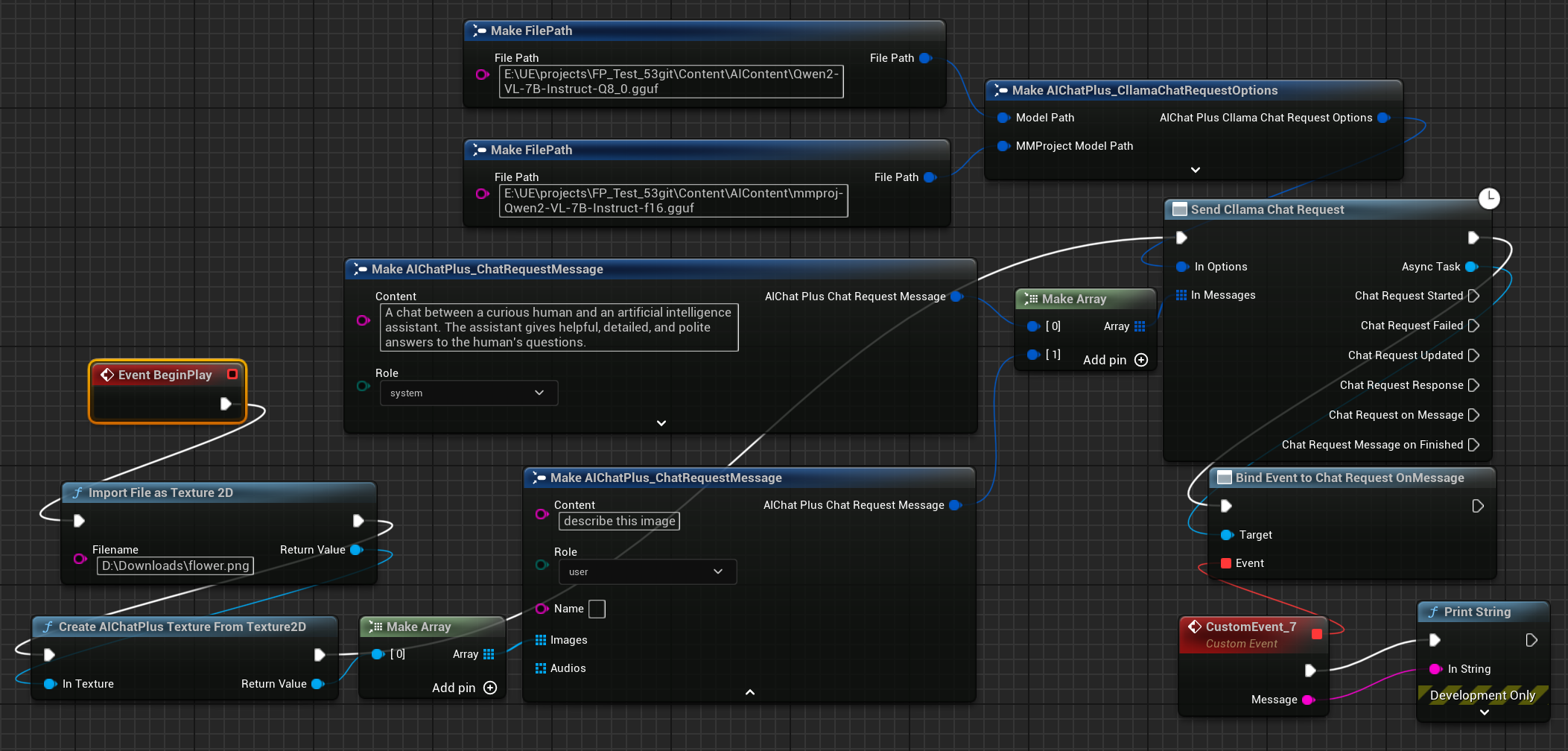
شغّل المخطط لرؤية النص المعاد

llama.cpp يستخدم وحدة معالجة الرسومات (GPU)
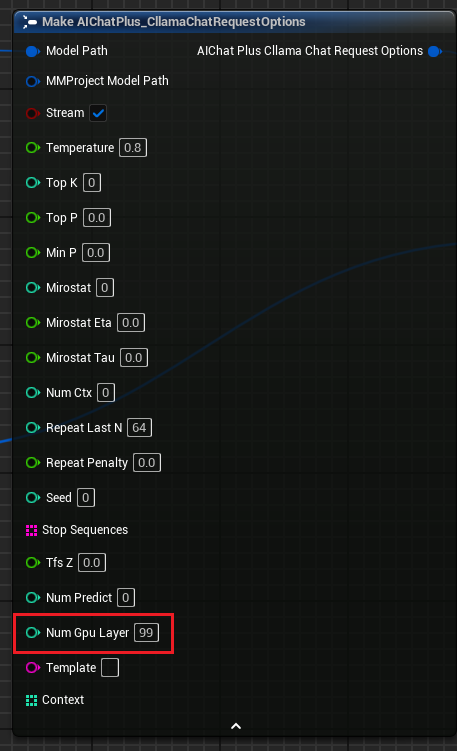
"خيارات طلب الدردشة في Cllama" تمت إضافة معلمة "Num Gpu Layer"، التي تتيح ضبط حمل وحدة معالجة الرسوميات في llama.cpp، مما يسمح بالتحكم في عدد الطبقات المطلوب حسابها على وحدة معالجة الرسوميات. كما هو موضح في الصورة.
KeepAlive
مُخصَّصات طلب الدردشة Cllama
تمت إضافة المعلمة "KeepAlive" التي تتيح إبقاء ملف النموذج محملًا في الذاكرة بعد قراءته، مما يُسهل استخدامه مباشرةً في المرة التالية ويقلل من عدد مرات إعادة قراءة النموذج.
القيمة KeepAlive تمثل المدة التي يظل فيها النموذج محتفظًا به:
- 0 تعني عدم الاحتفاظ به، وسيتم تحريره فور الاستخدام.
- -1 تعني الاحتفاظ به بشكل دائم.
يمكنك تعيين قيمة KeepAlive مختلفة في كل طلب Options، حيث ستستبدل القيمة الجديدة القيمة القديمة. على سبيل المثال:
- يُمكنك ضبط الطلبات الأولى على KeepAlive=-1 للاحتفاظ بالنموذج في الذاكرة.
- ثم ضبط الطلب الأخير على KeepAlive=0 لتحرير ملف النموذج.
معالجة ملفات النماذج داخل حزمة .Pak بعد التعبئة
بعد تفعيل حزمة Pak، سيتم وضع جميع ملفات موارد المشروع في ملف .Pak، بما في ذلك ملف نموذج غير المتصل gguf.
بما أن llama.cpp لا يدعم القراءة المباشرة لملفات .Pak، لذا يجب نسخ ملفات النموذج دون اتصال من ملف .Pak إلى نظام الملفات.
يوفر AIChatPlus وظيفة تعمل تلقائيًا على نسخ ومعالجة ملفات النماذج من ملفات .Pak، ثم وضعها في مجلد Saved:
أو يمكنك التعامل مع ملفات النماذج في .Pak بنفسك، الأمر الأساسي هو أنك بحاجة إلى نسخ الملفات خارجها، لأن llama.cpp لا يمكنه قراءة ملفات .Pak بشكل صحيح.
العقدة الوظيفية
يقدم Cllama بعض العُقَد الوظيفية لتسهيل الحصول على حالة البيئة الحالية.
"كللاما صالح": للتحقق مما إذا كان Cllama llama.cpp مهيأ بشكل صحيح

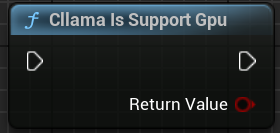
"كلاما يدعم جي بي يو": يحدد ما إذا كان llama.cpp يدعم واجهة جي بي يو الخلفية في البيئة الحالية.
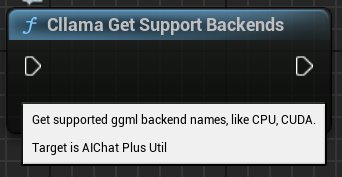
"الحصول على دعم خلفيات cllama": استرجاع جميع الخلفيات المدعومة حاليًا في llama.cpp
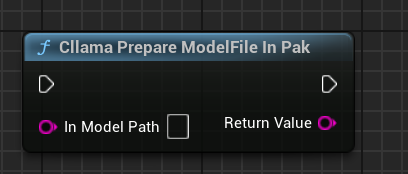
"كلاما تحضير ملف النموذج في باك": نسخ ملفات النموذج من باك إلى نظام الملفات تلقائيًا

Original: https://wiki.disenone.site/ar
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
هذا المنشور مترجم باستخدام ChatGPT، يُرجى تقديم ملاحظاتالإشارة إلى أي أوجه قصور في النص.