Blaupausen-Kapitel - Cllama (llama.cpp) (veraltet)
Verworfen
Cllama ist als veraltet markiert und wird nicht mehr gewartet.
Die ursprünglichen Funktionen von Cllama wurden von CllamaServerzu tragen.
Offline-Modell
Cllama basiert auf llama.cpp und ermöglicht die offline Nutzung von KI-Inferenzmodellen.
Da es sich um eine Offline-Version handelt, müssen wir zuerst die Modell-Datei vorbereiten, zum Beispiel durch Herunterladen des Offline-Modells von der HuggingFace-Website: Qwen1.5-1.8B-Chat-Q8_0.gguf
Platziere das Modell in einem bestimmten Ordner, zum Beispiel unter dem Verzeichnis des Spielprojekts unter Content/LLAMA.
Nachdem wir die Offline-Modelldateien haben, können wir mit Cllama KI-Chats durchführen.
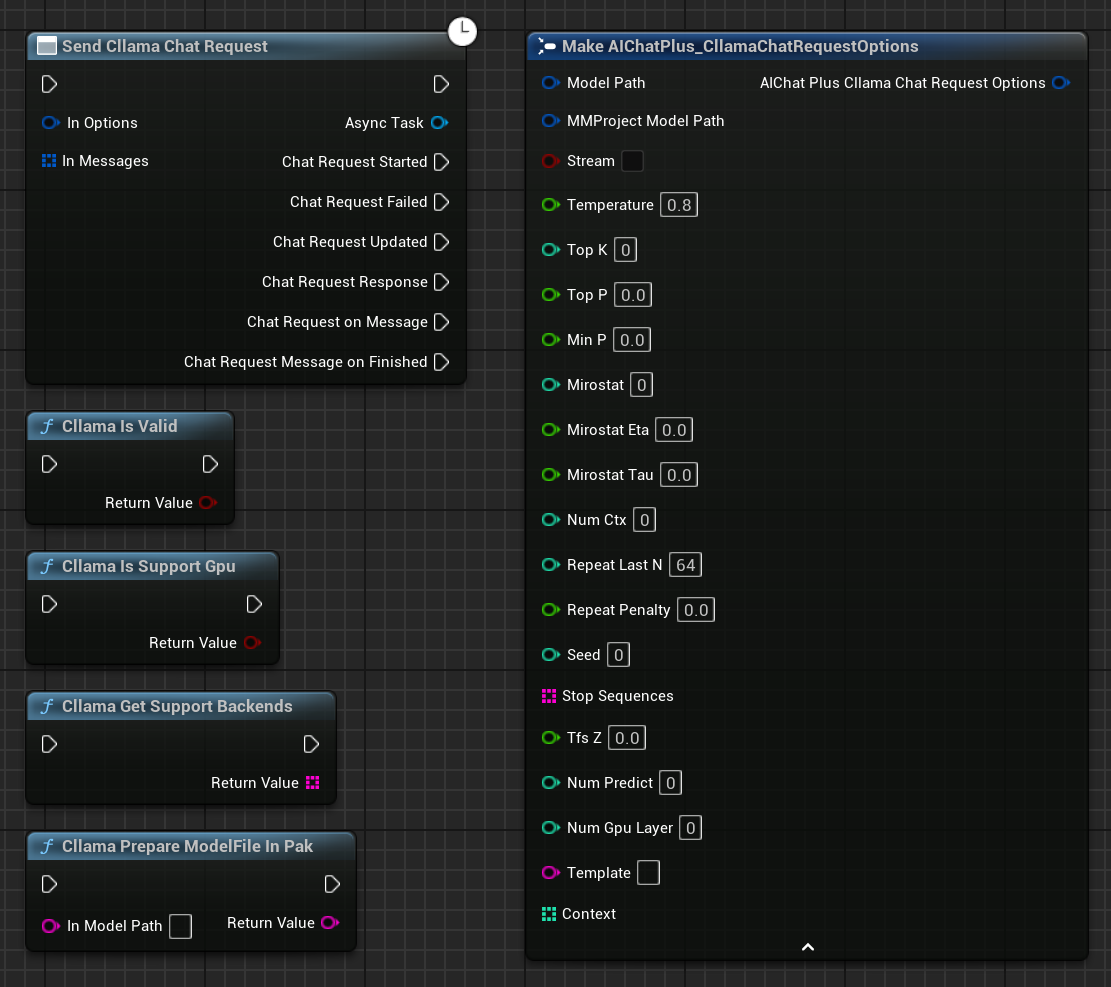
Text-Chat
Texterstellung mit Cllama
Erstelle einen Knoten mit Rechtsklick im Blueprint Send Cllama Chat Request.
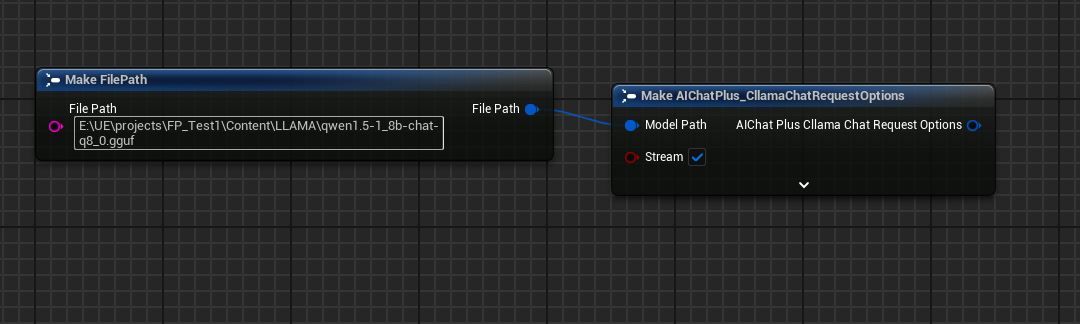
Erstelle einen Options-Knoten und setze Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
Erstellen Sie Messages, fügen Sie jeweils eine System Message und eine User Message hinzu
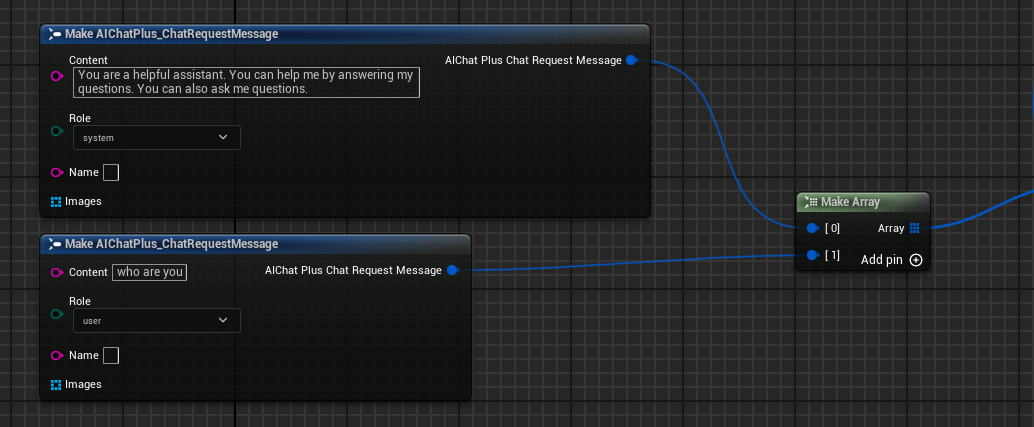
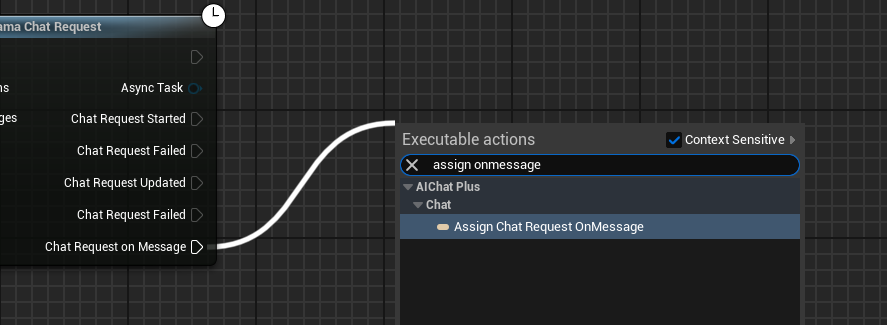
Erstelle einen Delegate, der die vom Modell ausgegebenen Informationen empfängt und auf dem Bildschirm ausgibt
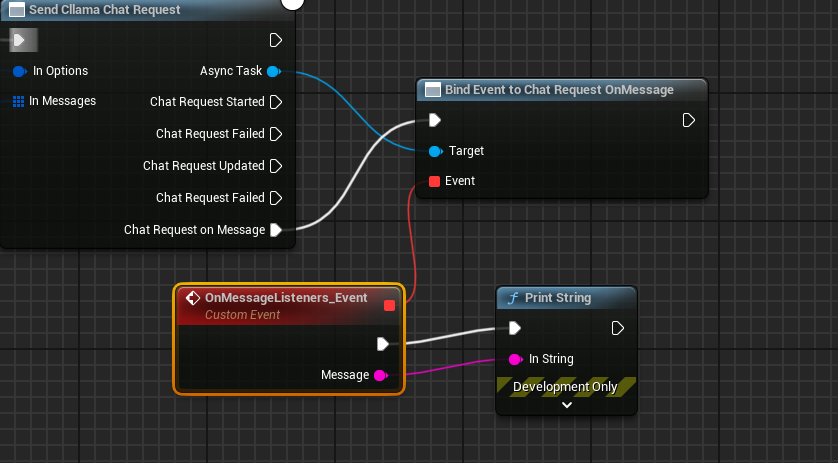
Die vollständige Blaupause sieht so aus. Führe die Blaupause aus, und du siehst den Spielbildschirm, der die vom großen Modell zurückgegebenen Nachrichten ausgibt.
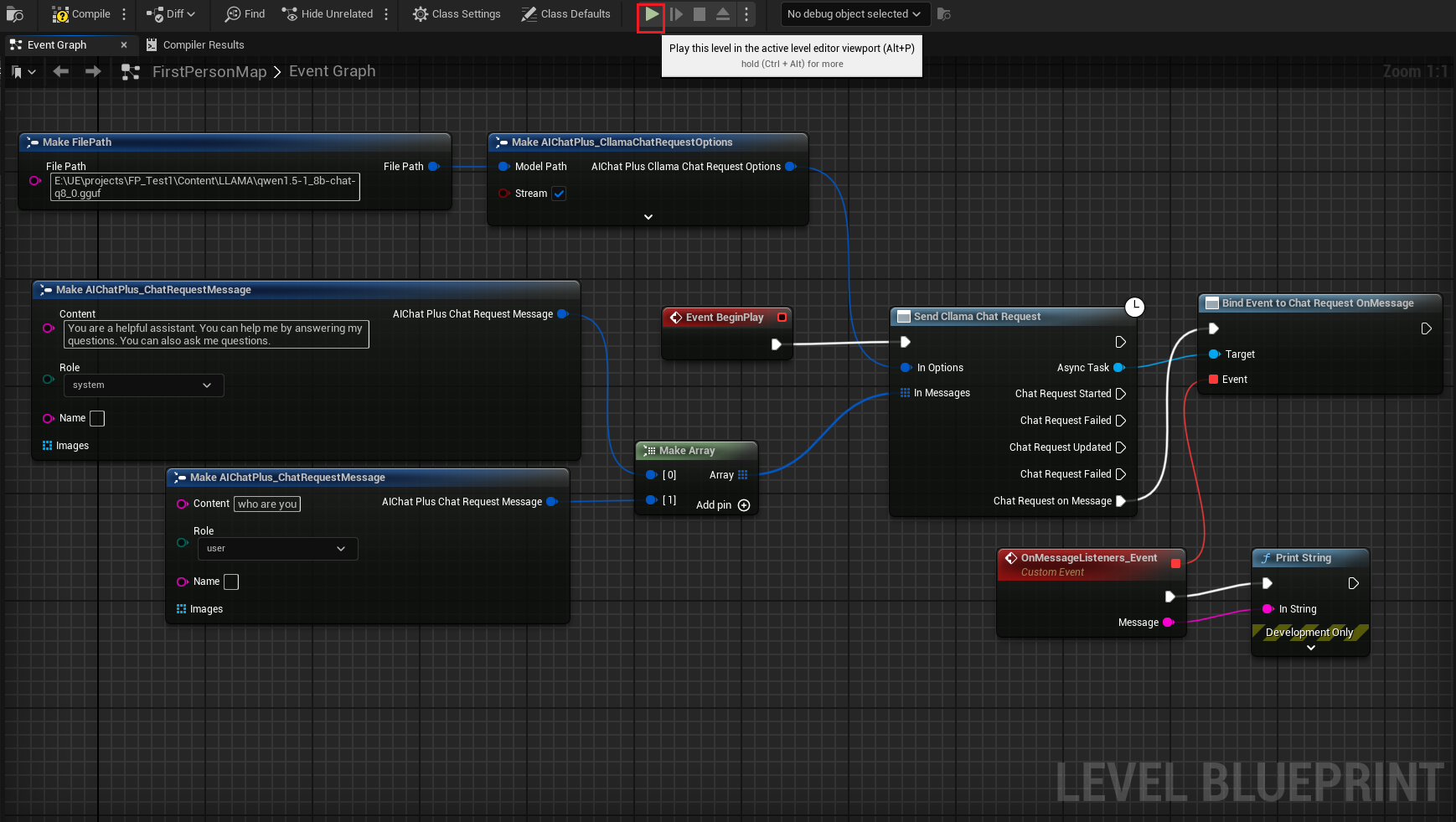
Bild zu Text llava
Cllama unterstützt auch experimentell die llava-Bibliothek und bietet damit Vision-Funktionen.
Zuerst bereiten Sie die Multimodal-Offline-Modelldatei vor, zum Beispiel Moondream (moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf) oder Qwen2-VL (Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf)oder ein anderes von llama.cpp unterstütztes Multimodales Modell.
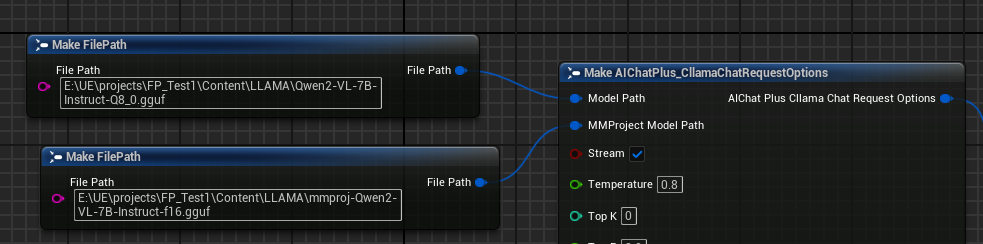
Erstellen Sie den Options-Knoten und setzen Sie die Parameter "Model Path" und "MMProject Model Path" jeweils auf die entsprechenden Multimodal-Modelldateien.
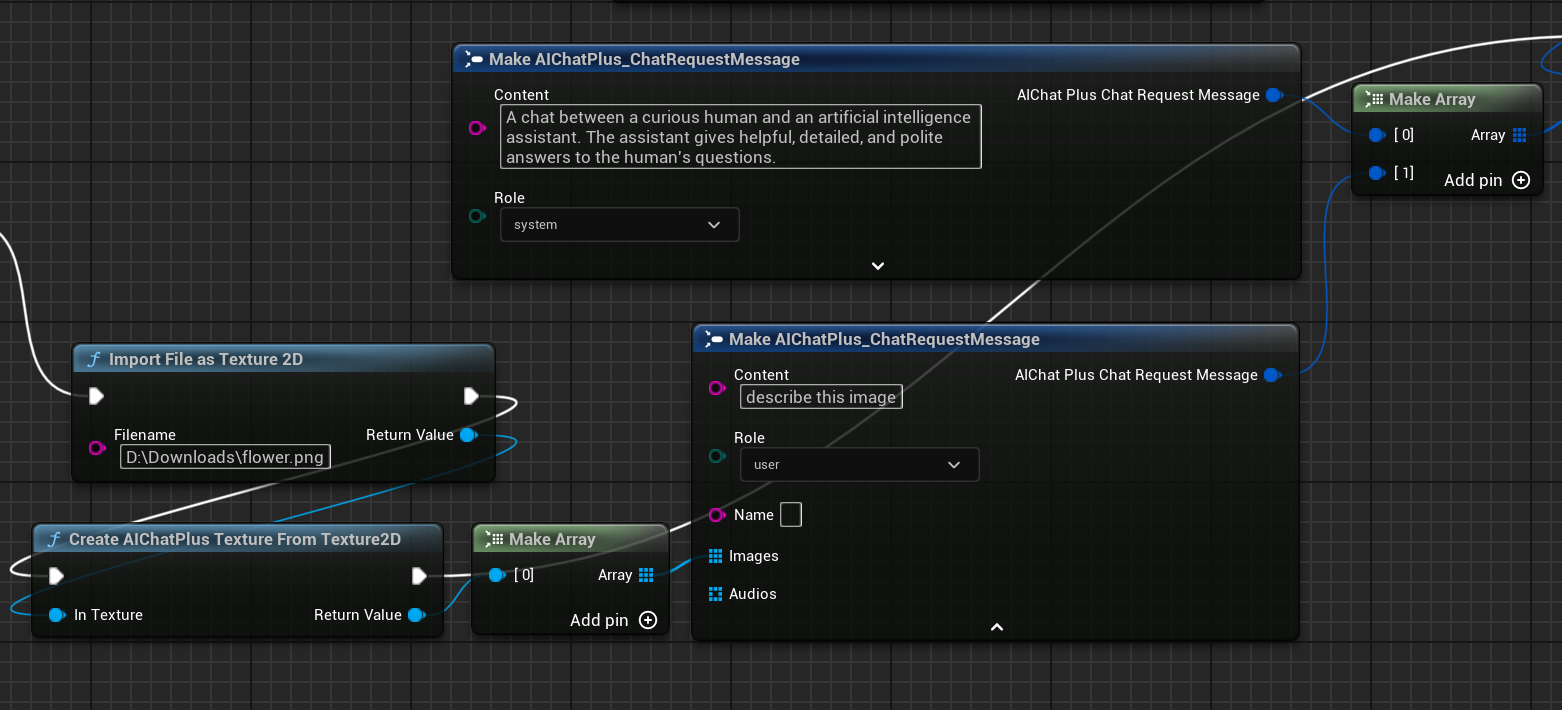
Erstellen Sie einen Knoten zum Lesen der Bilddatei flower.png und legen Sie die Messages fest.

Abschließend empfängt der letzte Knoten die zurückgegebenen Informationen und gibt sie auf dem Bildschirm aus. Die vollständige Blaupause sieht dann so aus:
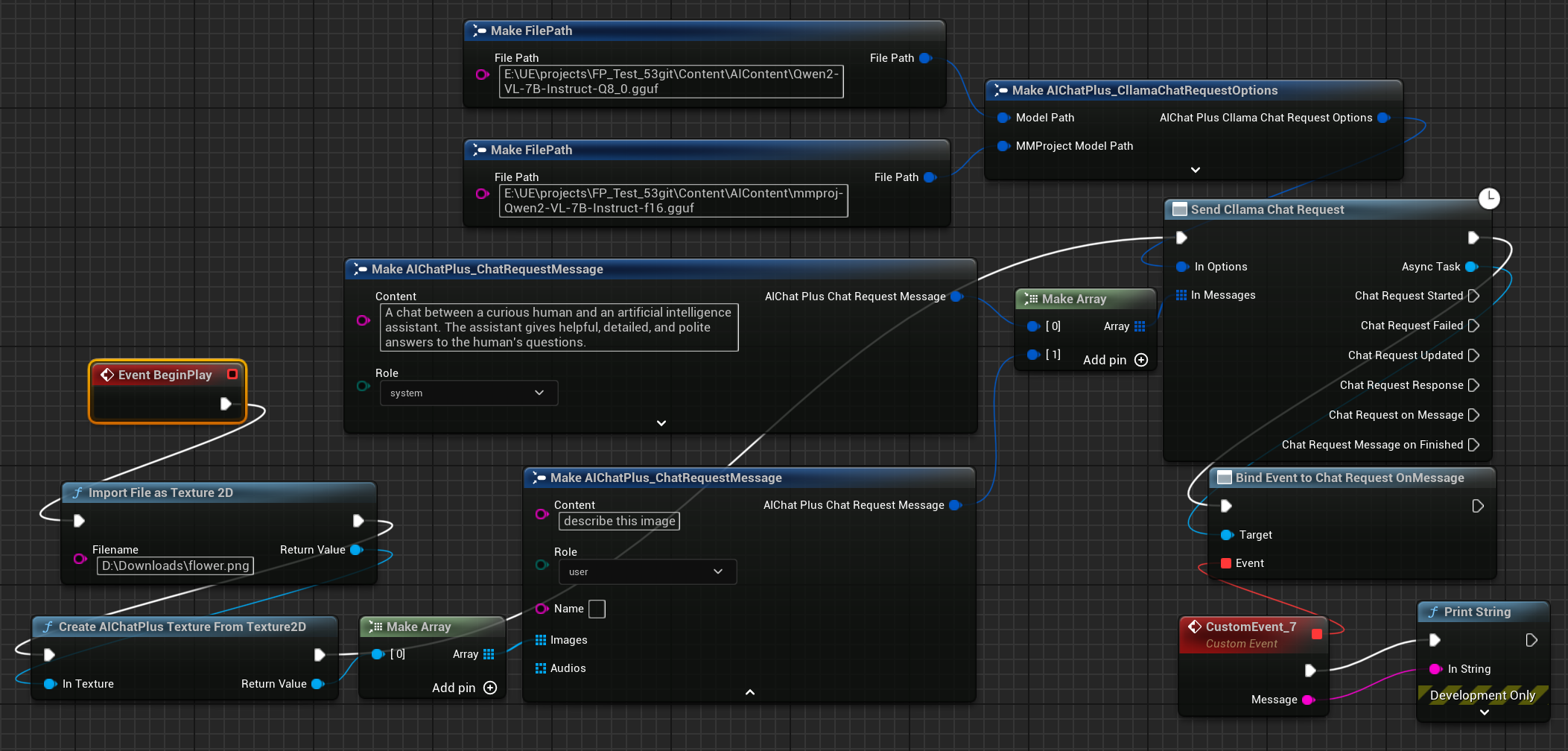
Führen Sie die Blaupause aus, um den zurückgegebenen Text zu sehen.

llama.cpp mit GPU-Unterstützung
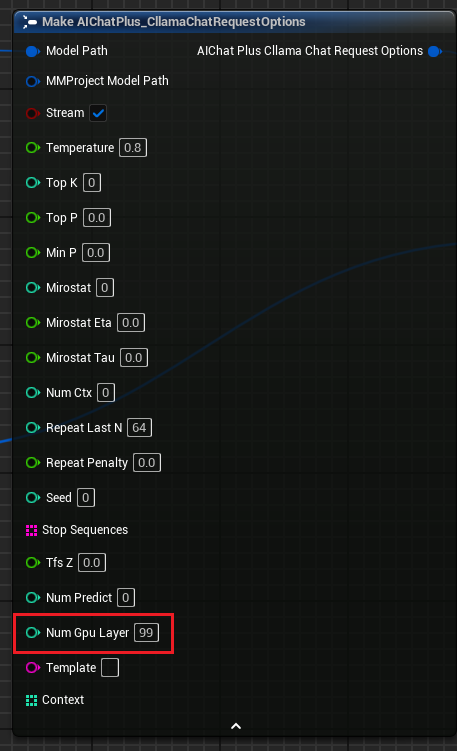
"Llama Chat-Anfrageoptionen" fügen den Parameter "Num Gpu Layer" hinzu, mit dem die GPU-Nutzlast von llama.cpp eingestellt werden kann, um die Anzahl der auf der GPU zu berechnenden Schichten zu steuern. Siehe Abbildung.
KeepAlive
"Cllama Chat Request Options" Fügt den Parameter "KeepAlive" hinzu, welcher ermöglicht, dass die eingelesene Modelldatei im Speicher behalten wird, um sie bei der nächsten Verwendung direkt nutzen zu können und so die Anzahl der Modell-Ladevorgänge zu reduzieren. KeepAlive gibt die Dauer an, für die das Modell im Speicher bleibt. 0 bedeutet keine Beibehaltung – das Modell wird nach der Verwendung sofort freigegeben; -1 bedeutet permanente Beibehaltung. Jede Anfrage mit gesetzten Options kann einen anderen KeepAlive-Wert haben, wobei der neue Wert den alten ersetzt. Beispielsweise können Sie für die ersten Anfragen KeepAlive=-1 setzen, um das Modell im Speicher zu behalten, bis Sie mit der letzten Anfrage KeepAlive=0 setzen, um die Modelldatei freizugeben.
Verarbeitung von Modell-Dateien in gepackten .Pak-Dateien
Nachdem die Pak-Packung aktiviert wurde, werden alle Ressourcendateien des Projekts in der .Pak-Datei gespeichert, selbstverständlich inklusive der Offline-Modelldatei gguf.
Da llama.cpp keine direkte Unterstützung für das Lesen von .Pak-Dateien bietet, müssen die Offline-Modelldateien aus der .Pak-Datei in das Dateisystem kopiert werden.
AIChatPlus stellt eine Funktionsfunktion bereit, die automatisch Modelldateien aus .Pak-Dateien kopiert und im Saved-Ordner ablegt:
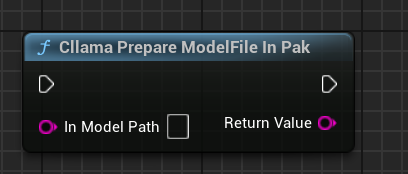
Oder Sie können die Modelldateien in der .Pak-Datei selbst verarbeiten. Der Schlüssel liegt darin, die Dateien herauszukopieren, da llama.cpp nicht in der Lage ist, .Pak-Dateien korrekt zu lesen.
Funktionsknoten
Cllama bietet einige Funktionsknoten zur einfachen Abfrage des aktuellen Umgebungsstatus.
"Cllama Is Valid": Prüft, ob Cllama llama.cpp korrekt initialisiert wurde

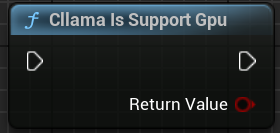
"Cllama Is Support Gpu": Prüft, ob llama.cpp im aktuellen Umgebung GPU-Backend unterstützt
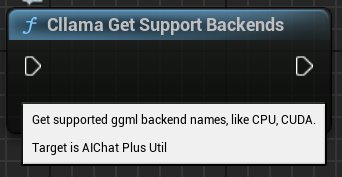
"Cllama Get Support Backends": Ermittelt alle aktuell unterstützten Backends von llama.cpp
"Cllama Prepare ModelFile In Pak": Kopiert automatisch die Modell-Dateien aus dem Pak in das Dateisystem.

Original: https://wiki.disenone.site/de
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
Dieser Beitrag wurde mit ChatGPT übersetzt. Bitte geben Sie Ihr Feedback unter FeedbackWeist auf etwaige Unvollständigkeiten hin.