Blaupausen-Teil - CllamaServer (llama.cpp Server)
Übersicht
CllamaServer basiert auf dem Server-Modus von llama.cpp und ermöglicht das Starten eines lokal laufenden Servers, der mit der OpenAI API kompatibel ist und zahlreiche Funktionen unterstützt:
- Lokale Inferenz-Services: Starten Sie den KI-Inferenzserver lokal, ohne auf externe APIs angewiesen zu sein.
- Kompatibel mit OpenAI API: Verwendet das OpenAI-kompatible API-Format für einfache Migration und Integration
- Mehrfach-Sitzungsunterstützung: Unterstützt mehrere gleichzeitige Anfragen
- Tool Calling: Unterstützt die Funktionsaufruffunktion
- Sprach-zu-Text: Unterstützt die Speech-to-Text-Funktionalität
- Visuelles Management: Der Editor verfügt über eine integrierte Server-Verwaltungsoberfläche.
Unterschiede zu Cllama: * Cllama: Lädt das Modell direkt innerhalb des Prozesses für die Inferenz, kann jedoch nur eine Anfrage gleichzeitig bearbeiten * CllamaServer: Startet einen eigenständigen HTTP-Server, der mehrere gleichzeitige Anfragen verarbeiten kann, mit API-Kompatibilität zum OpenAI-Format.
Vorbereitungen
Da es lokal ausgeführt wird, müssen Sie zuerst die Offline-Modelldateien vorbereiten, beispielsweise von HuggingFace herunterladen: Qwen1.5-1.8B-Chat-Q8_0.gguf
Platziere das Modell in einem bestimmten Ordner, zum Beispiel im Verzeichnis des Spielprojekts unter Content/LLAMA.
Erstellen Sie den CllamaServer
Erstellen eines Servers mit Blueprint
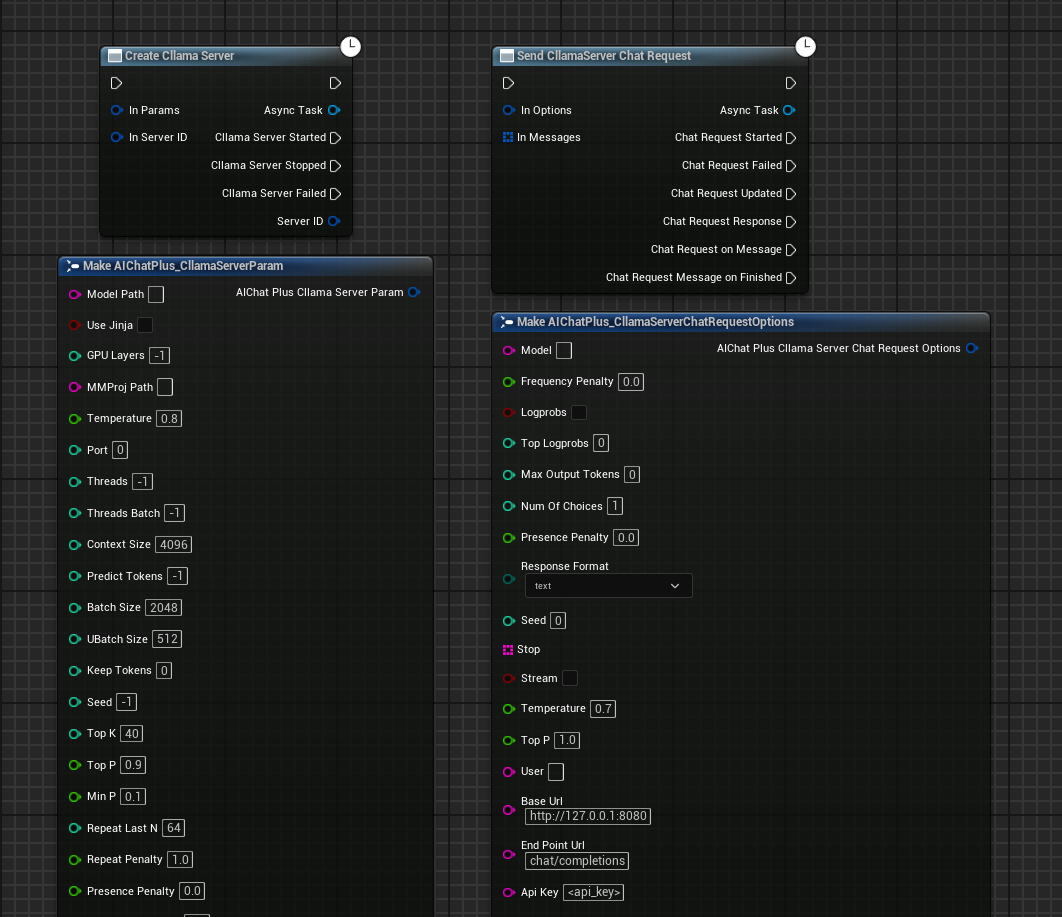
Erstellen Sie im Blueprint durch Rechtsklick den Knoten Create Cllama Server In World.
Server-Parameter konfigurieren
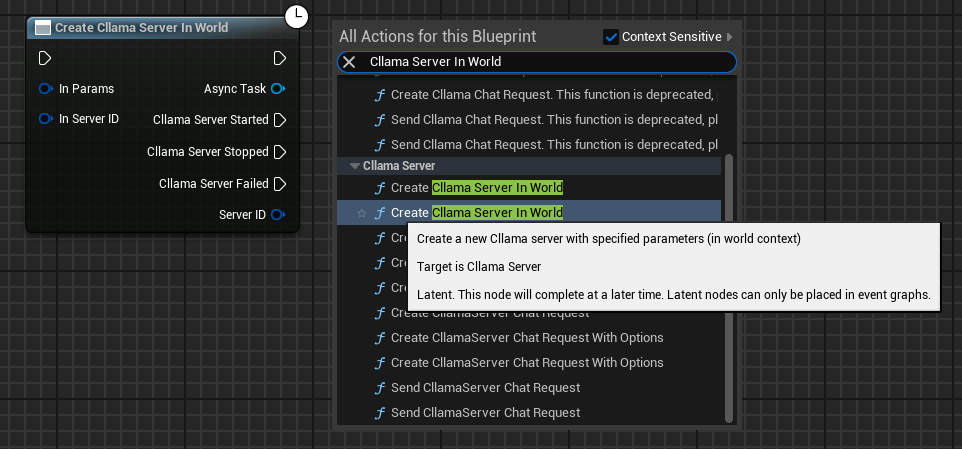
Erstelle den Cllama Server Param-Knoten und konfiguriere die Schlüsselparameter:
- Modell: Modell-Dateipfad (erforderlich)
- Port: Server-Port (0 bedeutet automatische Zuweisung)
- Host: Die Überwachungsadresse, standardmäßig
127.0.0.1 - NGpuLayers: Anzahl der GPU-Ebenen (-1 bedeutet, dass die gesamte GPU genutzt wird)
Rückrufereignisse binden
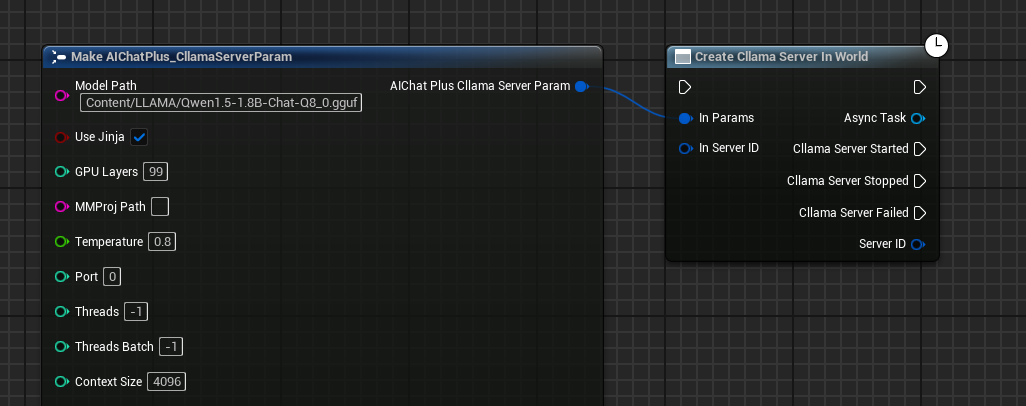
Server-Ereignisrückrufe binden:
- On Started: Wird ausgelöst, wenn der Server erfolgreich gestartet wurde
- Bei Stopp: Wird ausgelöst, wenn der Server angehalten wird
- Bei Fehlschlag: Wird ausgelöst, wenn der Server nicht startet.
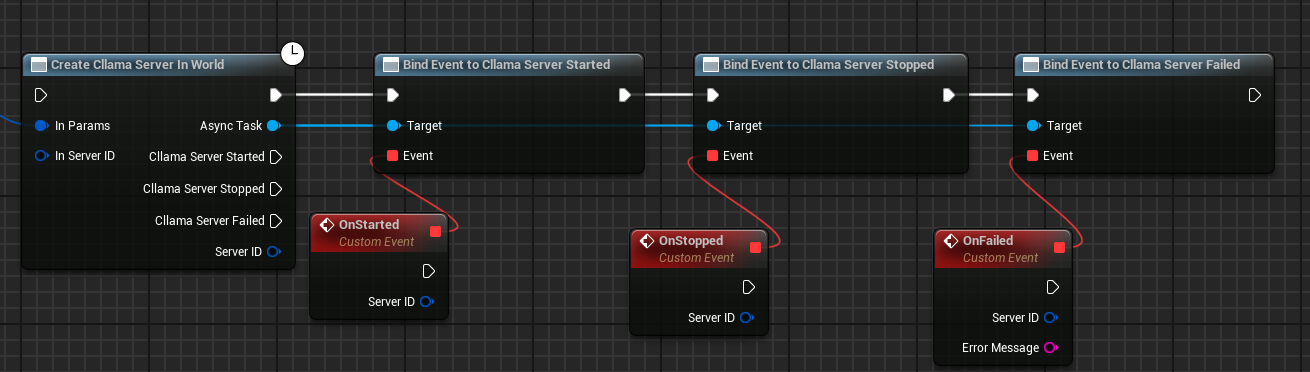
Kompletter Erstellungsplan
Das vollständige Blaupausen-Dokument zur Servererstellung ist wie folgt:
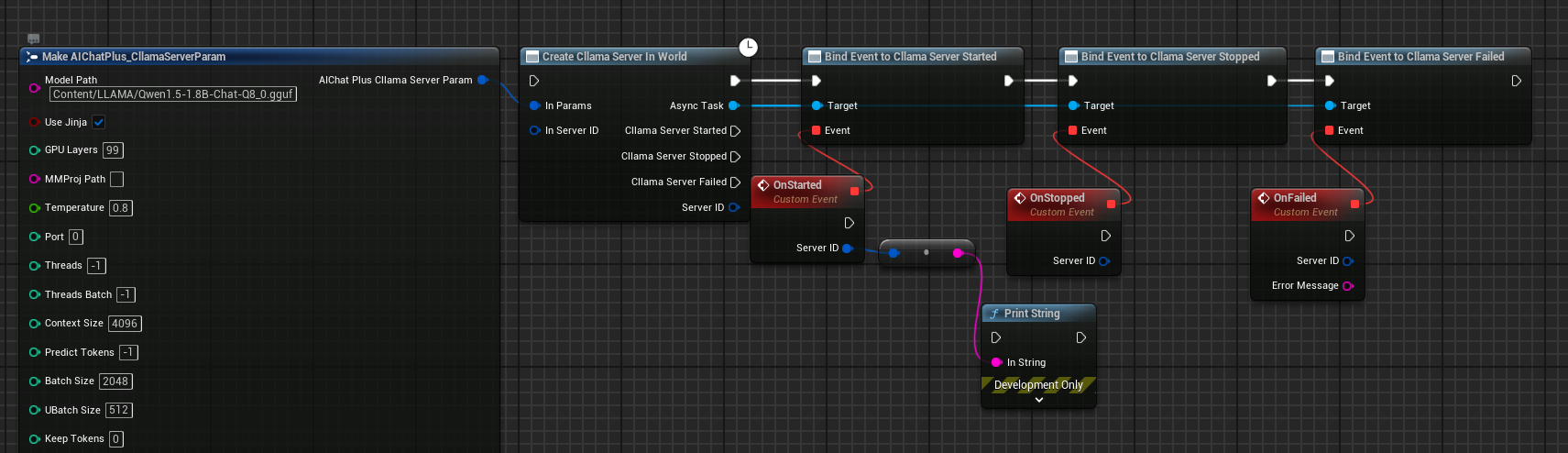
Nachdem der Blueprint ausgeführt wurde, löst der Server beim erfolgreichen Start das On Started-Ereignis aus.
Server-Parameter im Detail
Die FAIChatPlus_CllamaServerParam-Struktur umfasst die folgenden Parameter:
Häufig verwendete Parameter
| Parameter | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| Modell | FString | - | Pfad zur Modell-Datei (erforderlich) |
| Port | int32 | 0 | Überwachungsport, 0 bedeutet automatische Zuweisung |
| Host | FString | 127.0.0.1 | Überwachungsadresse |
| NGpuLayers | int32 | -1 | Anzahl der GPU-Schichten, -1 bedeutet alle |
| bUseJinja | bool | false | Jinja-Vorlagen verwenden |
| MMProj | FString | - | Multimodale Projektionsdateipfad |
| Temperatur | float | 0.8 | Abtasttemperatur |
Schlussfolgerungsparameter
| Parameter | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| CtxSize | int32 | 4096 | Größe des Kontextes |
| NPredict | int32 | -1 | Anzahl der vorhergesagten Tokens, -1 bedeutet unbegrenzt |
| Threads | int32 | -1 | Anzahl der CPU-Threads, -1 bedeutet automatisch |
| BatchSize | int32 | 2048 | Stapelverarbeitungsgröße |
Stichprobenparameter
| Parameter | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| TopK | int32 | 40 | Top-K-Sampling |
| TopP | float | 0.9 | Top-P-Sampling |
| MinP | float | 0.1 | Min-P-Stichprobenverfahren |
| RepeatPenalty | float | 1.0 | Wiederholungsstrafe |
Serverparameter
| Parameter | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| ApiKey | FString | - | API-Schlüssel (optional) |
| Timeout | int32 | 600 | Timeout in Sekunden |
| Parallel | int32 | 1 | Anzahl der parallelen Sequenzen |
| bNoWebUI | bool | false | Deaktiviert die Web-Oberfläche |
| bVerbose | bool | false | Detailliertes Protokoll |
Chatten mit CllamaServer
Chat-Anfrage erstellen
Nach erfolgreichem Start des Servers kann mit dem Knoten Send CllamaServer Chat Request eine Chat-Anfrage gesendet werden.
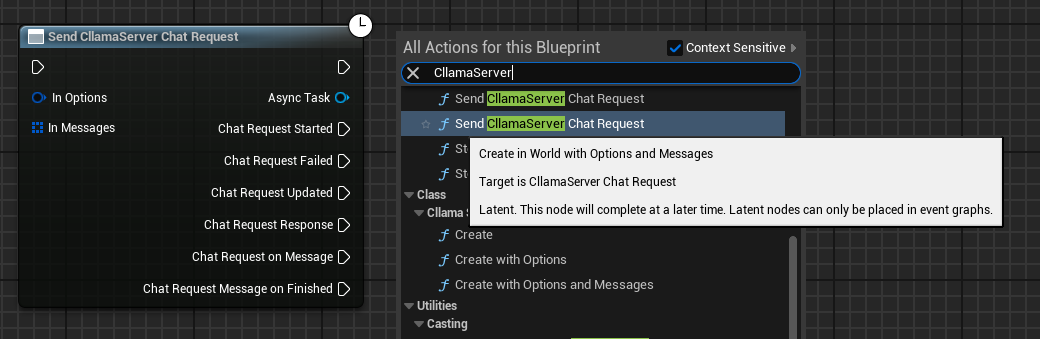
Chat-Optionen konfigurieren
Erstelle den Knoten CllamaServer Chat Request Options und setze die BaseUrl auf die Server-Adresse.
Sie können Server-Informationen über den Knoten Get Server Info By ID abrufen.
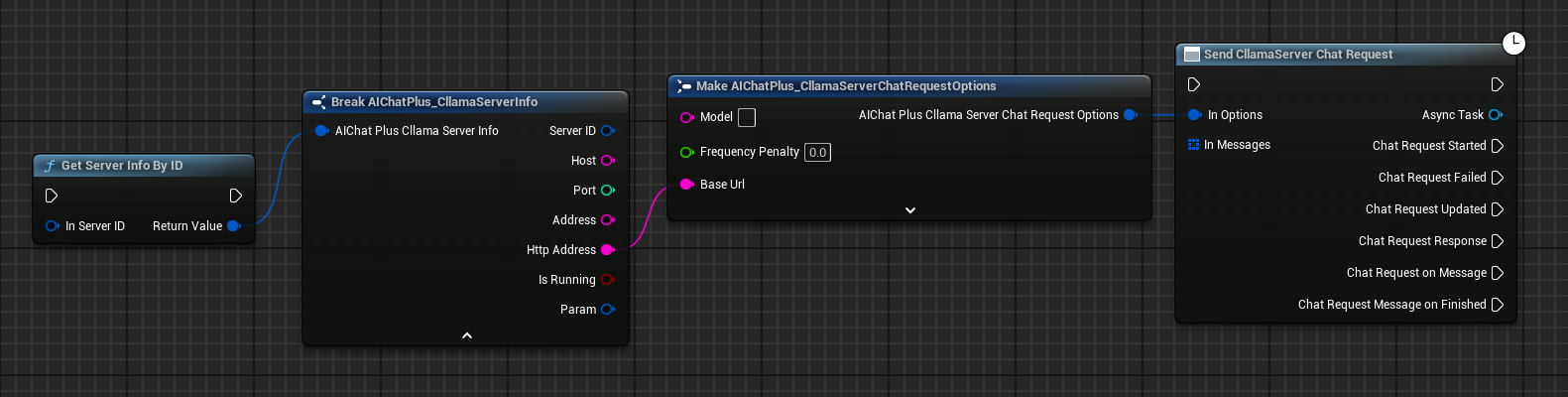
Nachrichten erstellen
Erstelle ein Messages-Array, füge eine System-Nachricht und eine Benutzernachricht hinzu.
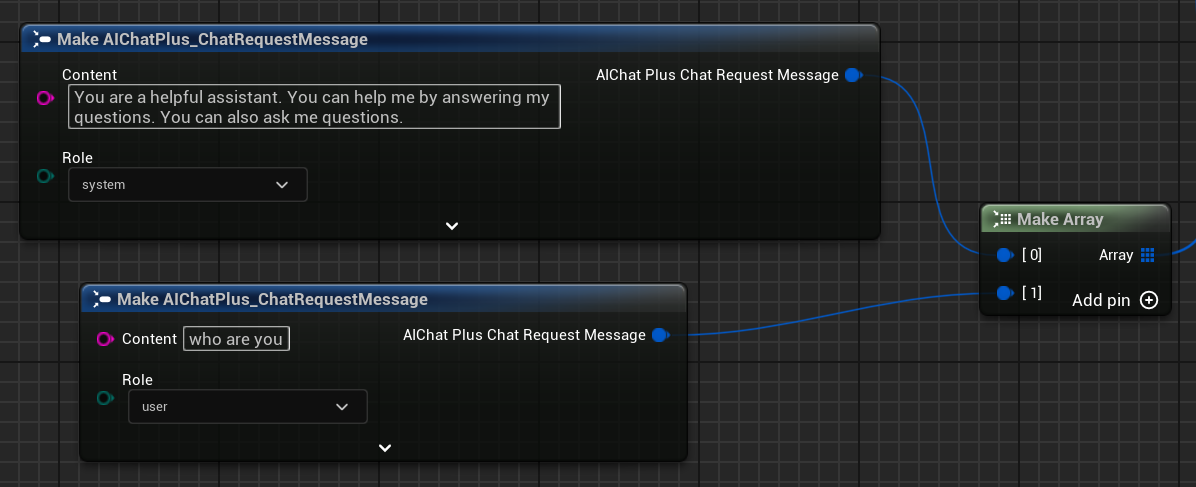
Rückruf für die Antwortverarbeitung binden
Binden Sie das On Message- oder On Message Finished-Ereignis, um die Modellantworten zu empfangen.
Hier ist die Übersetzung des Textes ins Deutsche:
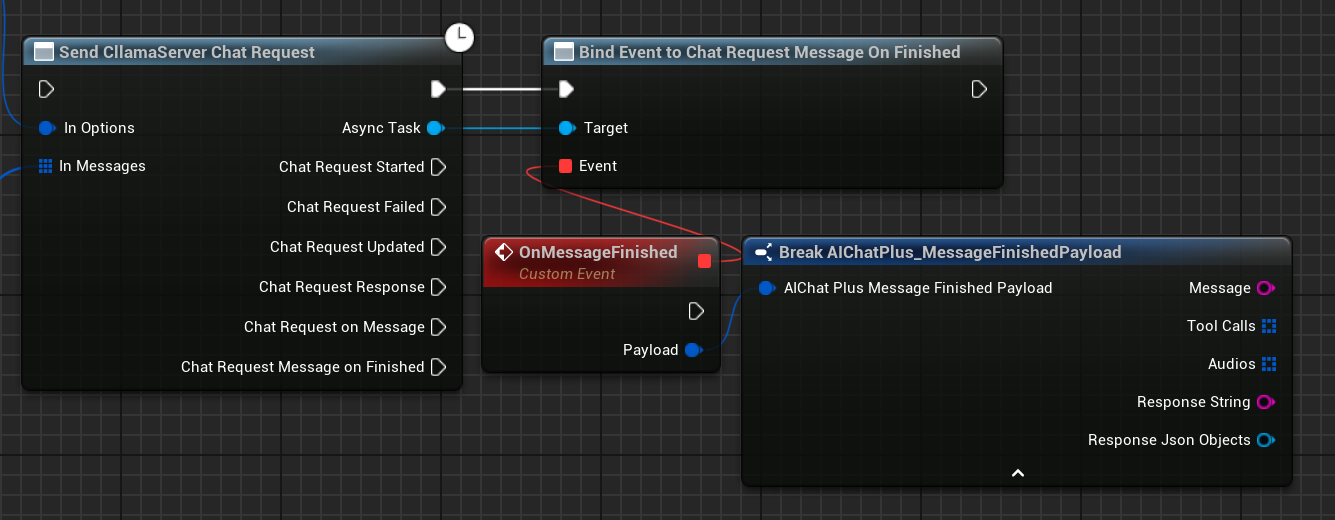
Vollständiger Chat-Blueprint
Die vollständige Chat-Blueprint sieht wie folgt aus:
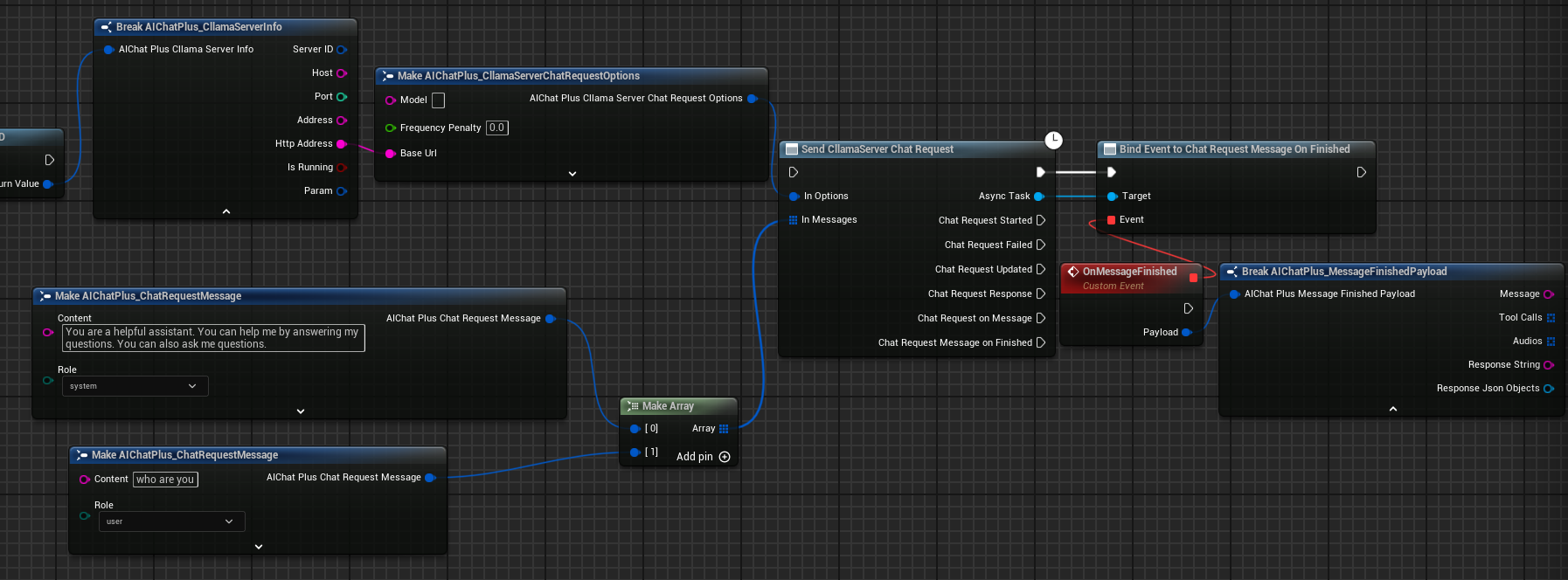
Laufzeitergebnis
Führen Sie den Blueprint aus, um zu sehen, wie die vom Modell zurückgegebenen Nachrichten auf dem Bildschirm angezeigt werden.
Server-Verwaltung
Server-Informationen abrufen
Verwenden Sie den Knoten Get Server Info, um detaillierte Informationen über den Server zu erhalten.
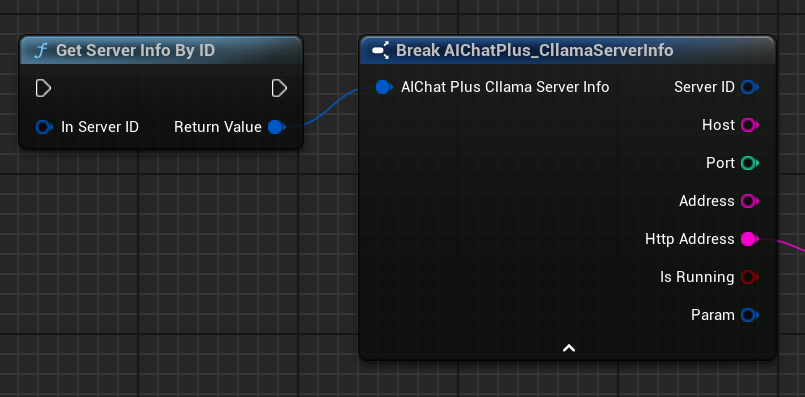
Server Info enthält die folgenden Informationen: * ServerID: Eindeutige Server-ID * Host: Überwachungsadresse * Port: Abhörport * Adresse: Vollständige Adresse (host:port) * HttpAddress: HTTP-Adresse (http://host:port) * bIsRunning: Wird ausgeführt * Param: Serverparameter
Stoppen des Servers
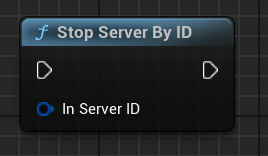
Verwenden Sie den Knoten Stop Server By ID, um den aktuellen Server zu stoppen.
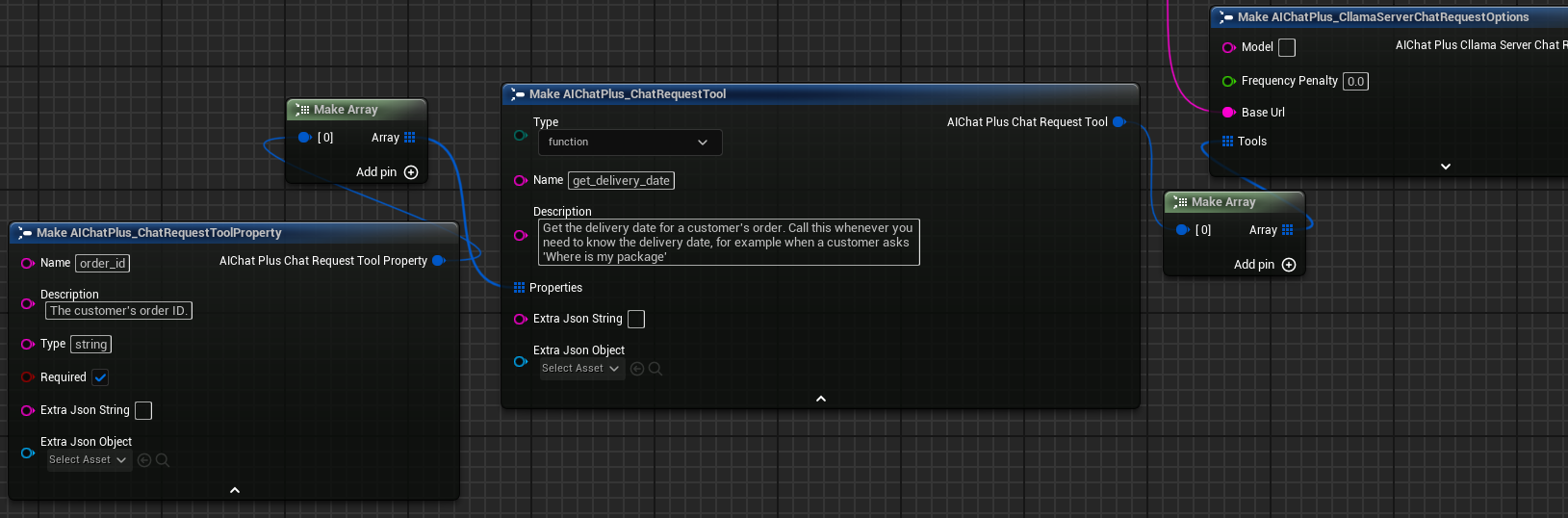
Statische Managementfunktionen
AIChatPlus bietet eine Reihe von statischen Funktionen zur Verwaltung aller Server:
| Funktion | Beschreibung |
|---|---|
Is Server Valid (Static) |
Prüft, ob der Server gültig ist |
Läuft der Server (statisch) |
Prüft, ob der Server läuft |
Stop Server By ID |
Server anhand der ID stoppen |
Stop All Servers |
Alle Server anhalten |
Get Server Info By ID |
Server-Informationen nach ID abrufen |
Get All Server IDs |
Alle Server-IDs abrufen |
Get Server By ID |
Holen Sie die Server-Instanz anhand der ID |
Multimodale Unterstützung
CllamaServer unterstützt multimodale Modelle (wie Moondream, Qwen2-VL usw.).
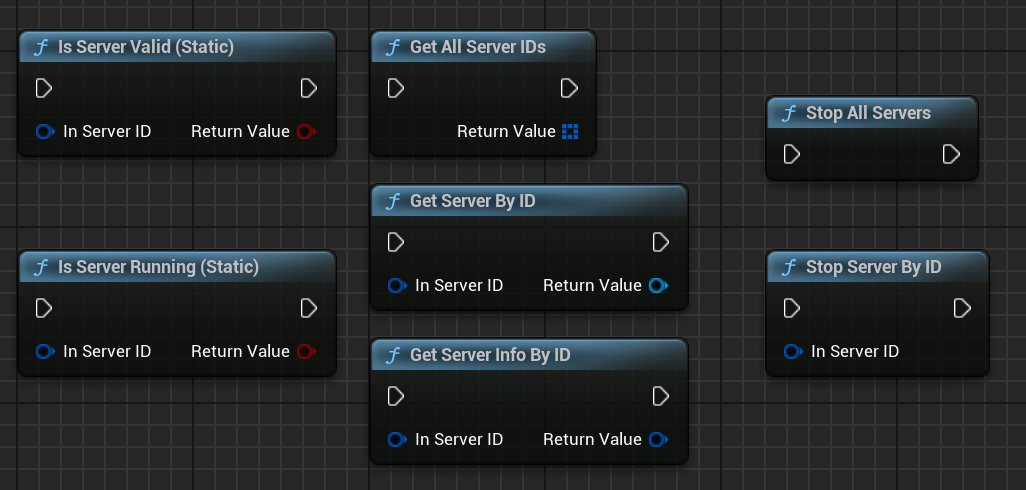
Multimodale Parameter konfigurieren
Im Server-Parameter wird MMProj (der Pfad zur Multimodal-Projektionsdatei) festgelegt:
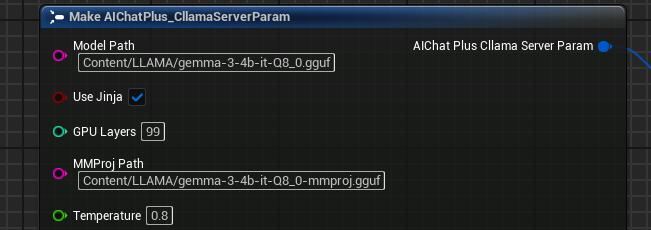
Bildnachricht senden
Bilder in Nachrichten hinzufügen:
Ausführungsergebnis
Benötige Bild: Zeigt das Ergebnis der Bilderkennung, der Bildschirm zeigt die Beschreibung des Bildinhalts durch das Modell an
Tool Calling
CllamaServer unterstützt die Tool-Calling-Funktion (Funktionsaufruf), deren Verwendung ähnlich wie bei OpenAI ist.
Eine detaillierte Beschreibung der Verwendung finden Sie unter Tool CallDokument.
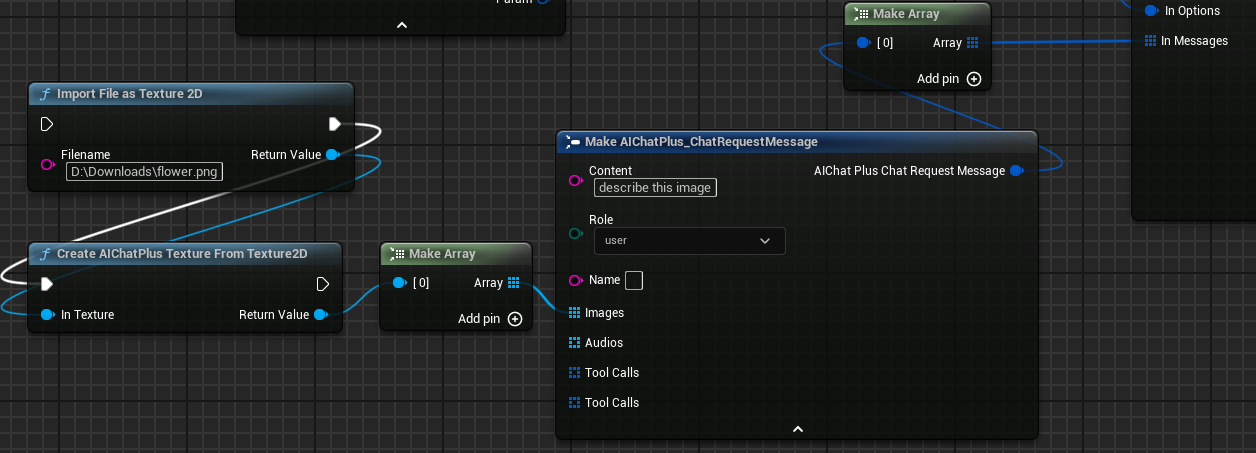
Bei der Verwendung von CllamaServer für Tool Calls ist Folgendes erforderlich:
1. Setzen Sie im Server-Parameter bUseJinja = true
2. Definieren Sie Werkzeuge im Feld "Tools" der Chat-Optionen
Editor Server-Verwaltung
AIChatPlus bietet in den Editor-Tools eine visuelle Management-Oberfläche für CllamaServer, die das Erstellen, Überwachen und Verwalten mehrerer Server erleichtert.
Editor-Tool öffnen: Tools -> AIChatPlus -> AIChat, öffnen Sie den Reiter Cllama Server Manager.
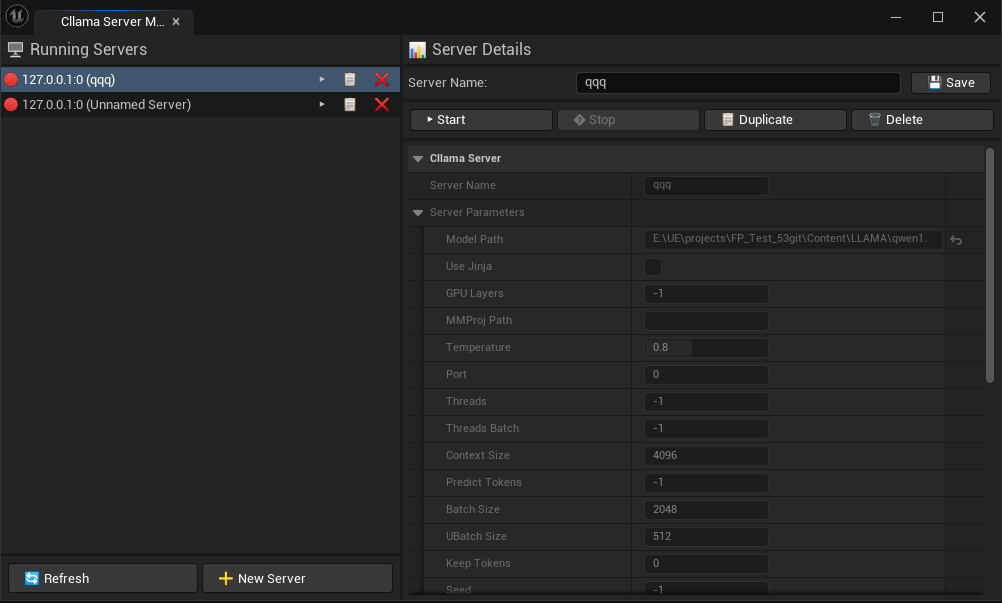
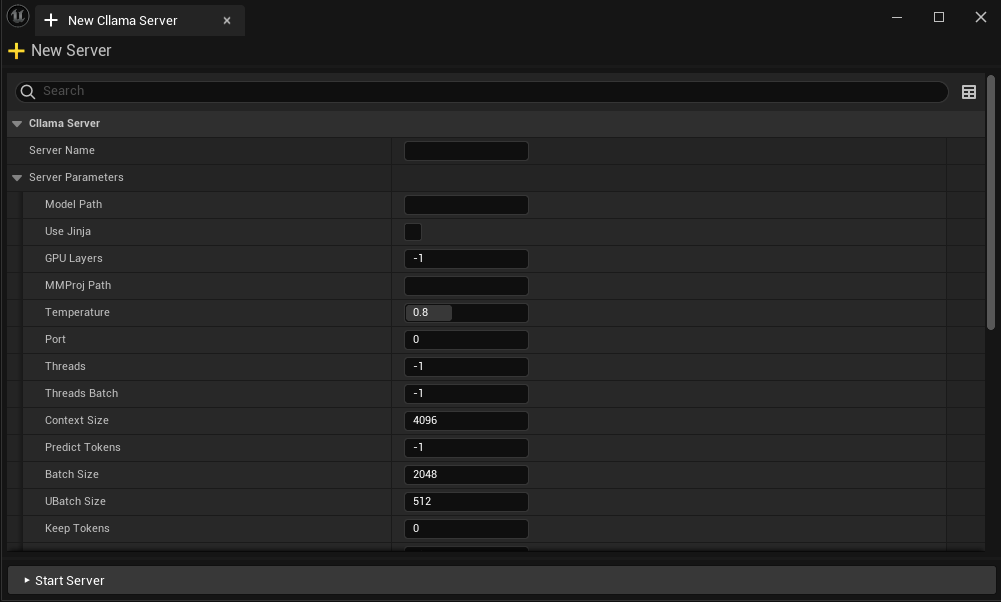
Im Editor können Sie: * Neuen Server erstellen * Status des laufenden Servers prüfen * Angegebenen Server beenden * Server-Parameter konfigurieren * Die Server-Konfiguration wird automatisch gespeichert
Hinweis: Der deutsche Text behält die technische und direkte Tonart des Originals bei, wie für Anleitungen oder Dokumentationen üblich, und vermittelt klar die Anforderung eines Bildes mit spezifischen Details zur Benutzeroberfläche. Die Übersetzung ist präzise, natürlich formuliert und verzichtet auf maschinelle Klischees.
Beziehungen zu anderen APIs
Da CllamaServer mit dem OpenAI-API-Format kompatibel ist, können Sie auch den Chat-Request-Knoten von OpenAI verwenden, um mit CllamaServer zu kommunizieren. Setzen Sie einfach die BaseUrl auf die Adresse des CllamaServers.
Original: https://wiki.disenone.site/de
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
Dieser Beitrag wurde mit ChatGPT übersetzt, bitte geben Sie Ihr FeedbackHinweis auf etwaige Fehlstellen.