Blueprints Chapter - Cllama (llama.cpp) (Deprecated)
Obsolete
Cllama has been marked as deprecated and is no longer maintained.
The original functionalities of Cllama are provided by CllamaServerTo carry.
Offline Model
Cllama is built upon llama.cpp and supports offline usage of AI inference models.
Since it's offline, we need to prepare the model files beforehand, such as downloading the offline model from the HuggingFace website: Qwen1.5-1.8B-Chat-Q8_0.gguf
Place the model under a certain folder, for example, within your game project directory at Content/LLAMA.
With the offline model files in place, we can now engage in AI chat using Cllama.
Text Chat
Text Chat Using Cllama
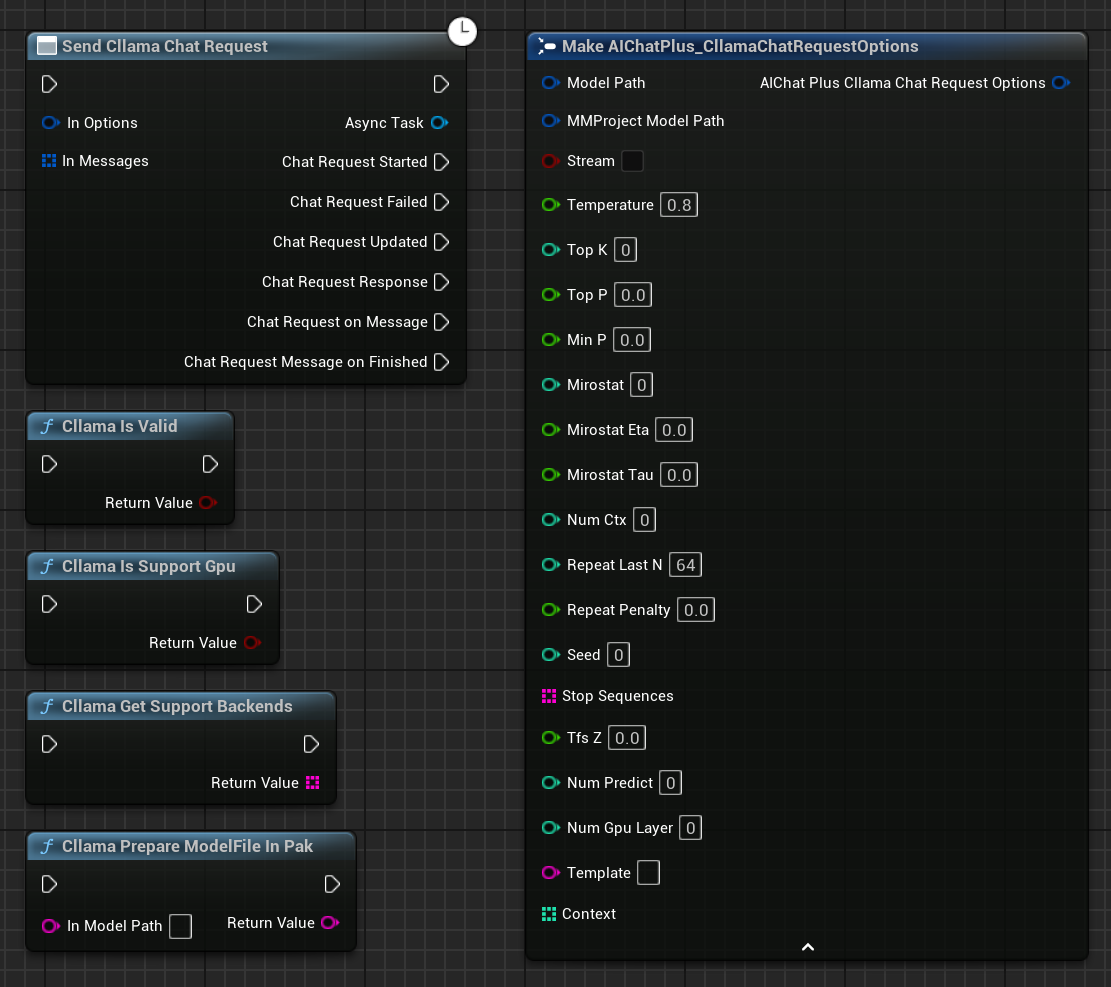
Right-click in the blueprint to create a node Send Cllama Chat Request.
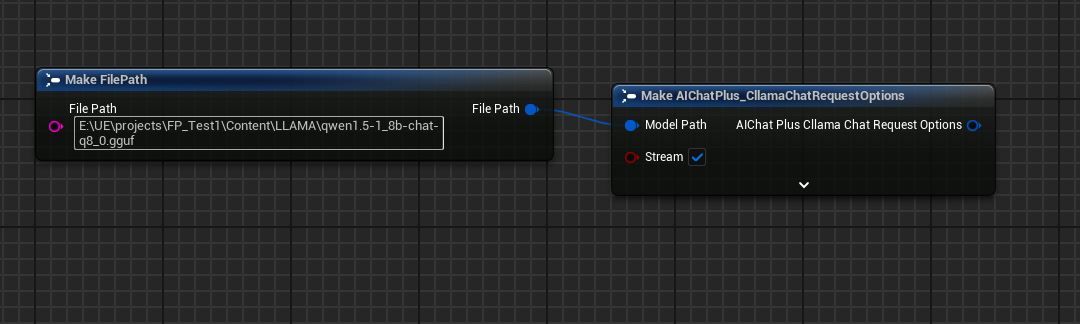
Create an Options node and set Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
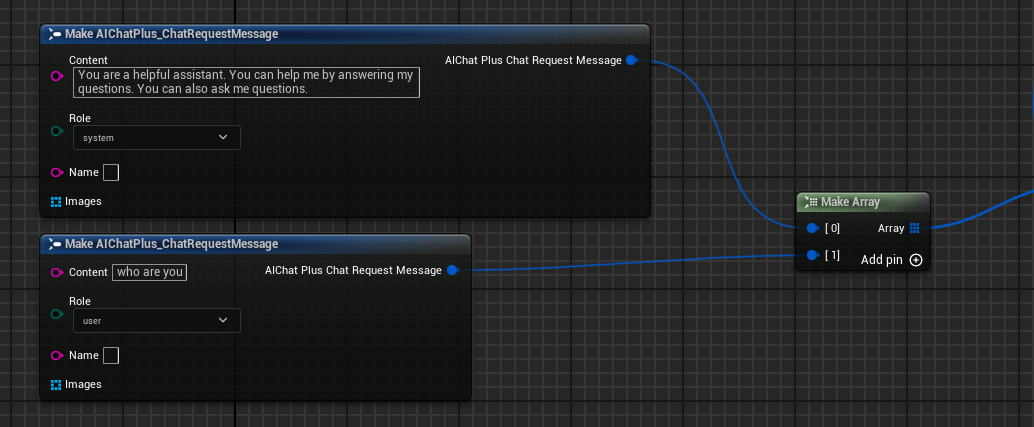
Create Messages, add a System Message and a User Message respectively.
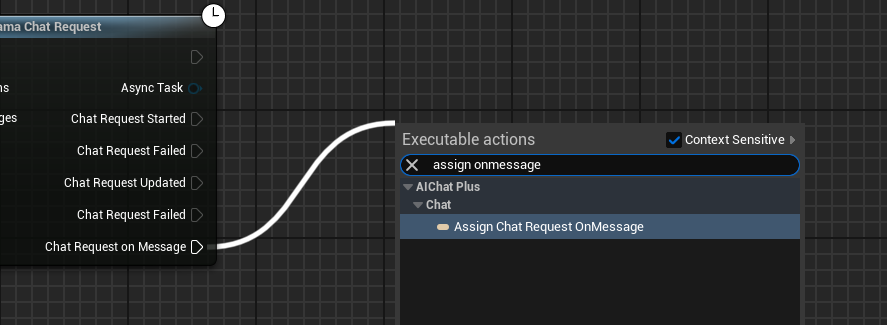
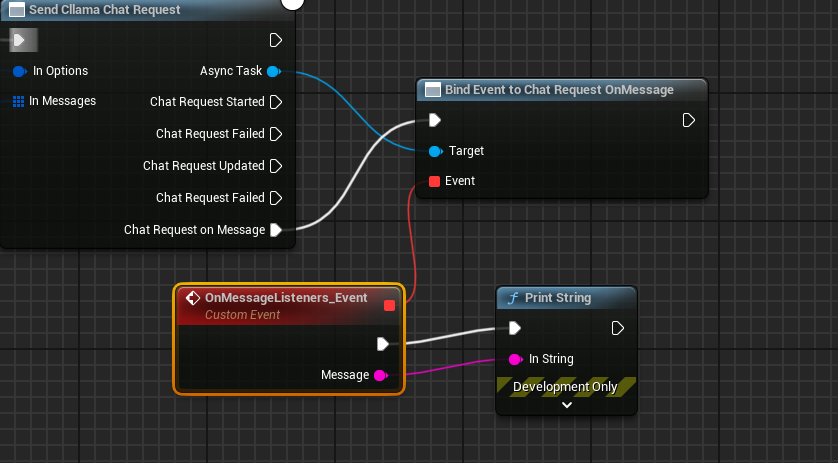
Create a Delegate to receive the model's output and print it on the screen
The complete blueprint looks like this: Run the blueprint, and you'll see the game screen printing messages returned by the large model.
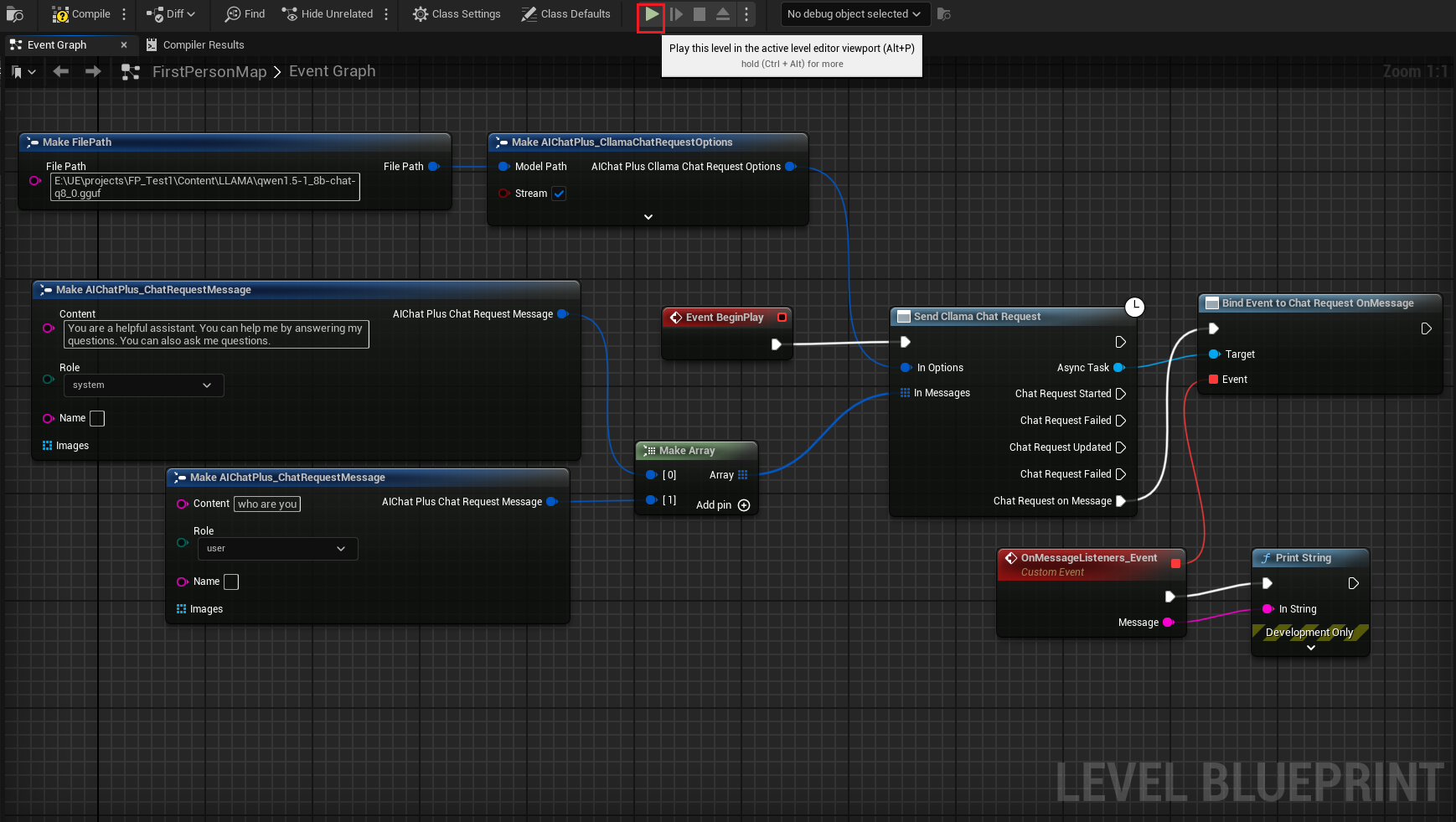
Image captioning llava
Cllama also experimentally supports the llava library, offering Vision capabilities.
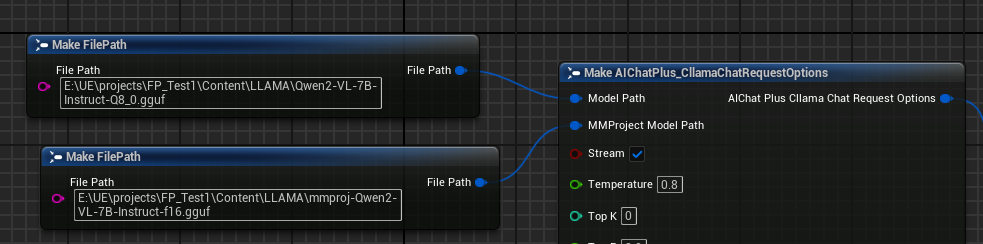
First, prepare the Multimodal offline model files, such as Moondream (moondream2-text-model-f16.gguf, moondream2-mmproj-f16.ggufor Qwen2-VL (Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.ggufor other Multimodal models supported by llama.cpp.
Create an Options node and set the parameters "Model Path" and "MMProject Model Path" to the corresponding Multimodal model files respectively.
Create a node to read the image file flower.png and configure Messages.

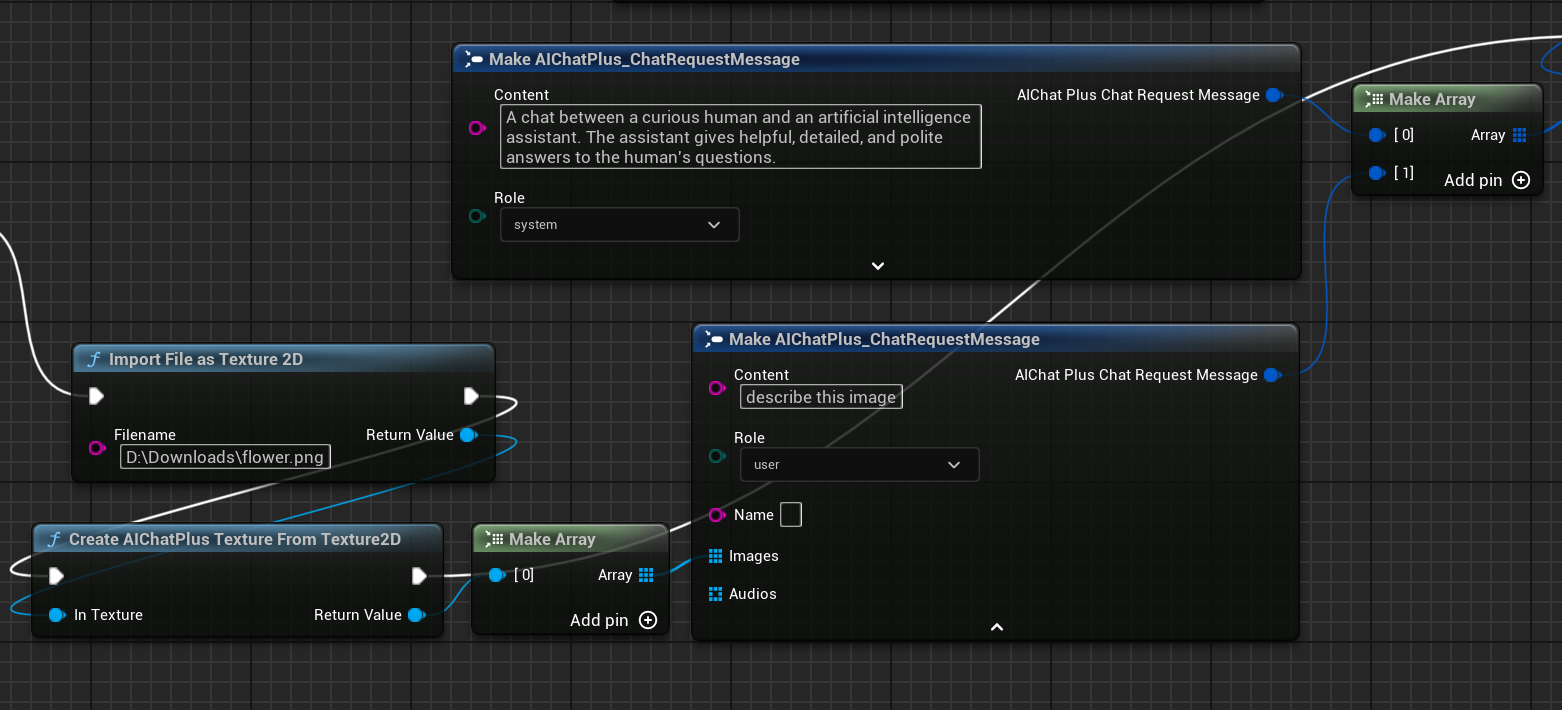
Finally, the node that accepts the returned information is created and printed to the screen. The complete blueprint will look like this:
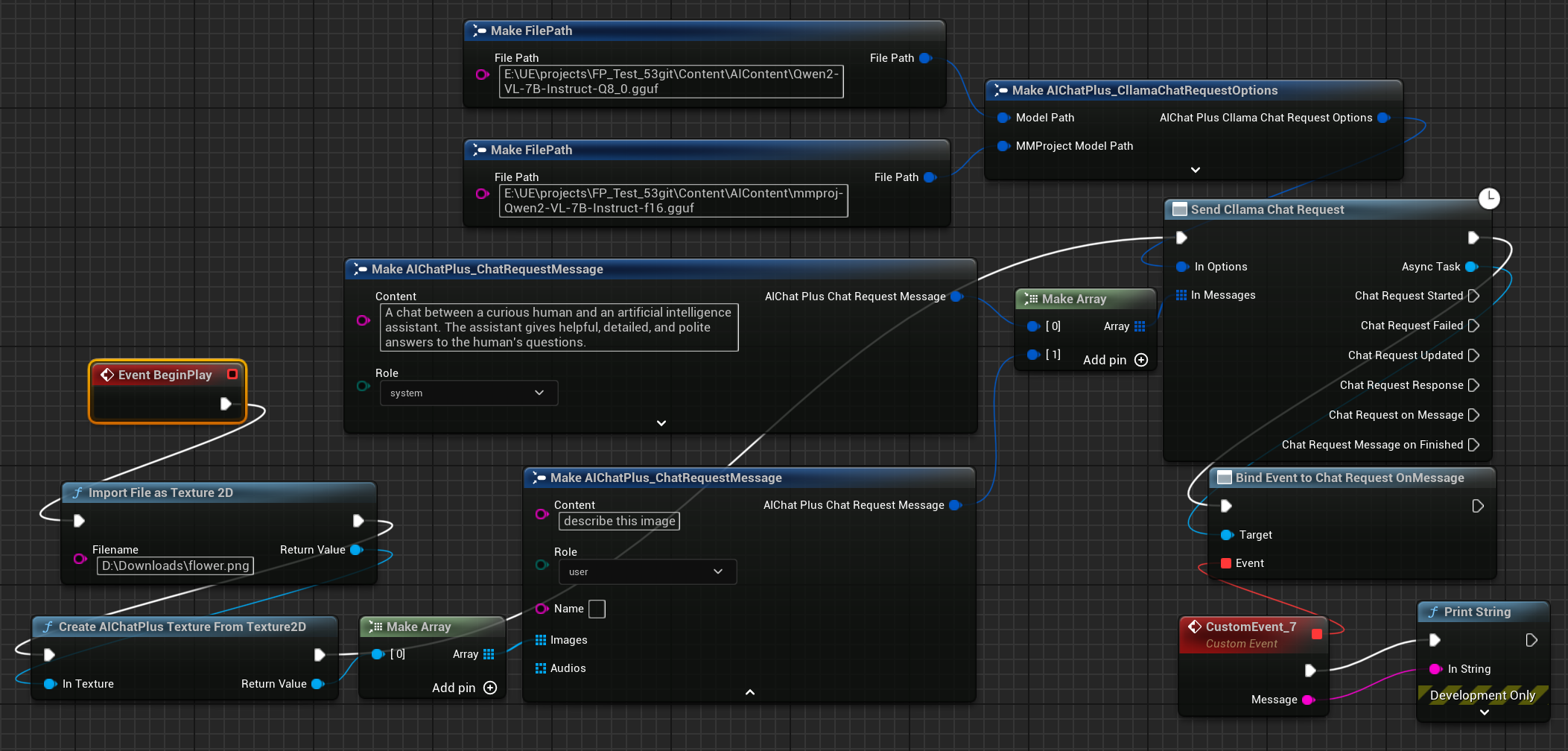
Run the blueprint to see the returned text

llama.cpp with GPU support
"ClLama Chat Request Options" Added parameter "Num Gpu Layer," allows setting llama.cpp's GPU payload to control the number of layers computed on the GPU. As shown in the figure.
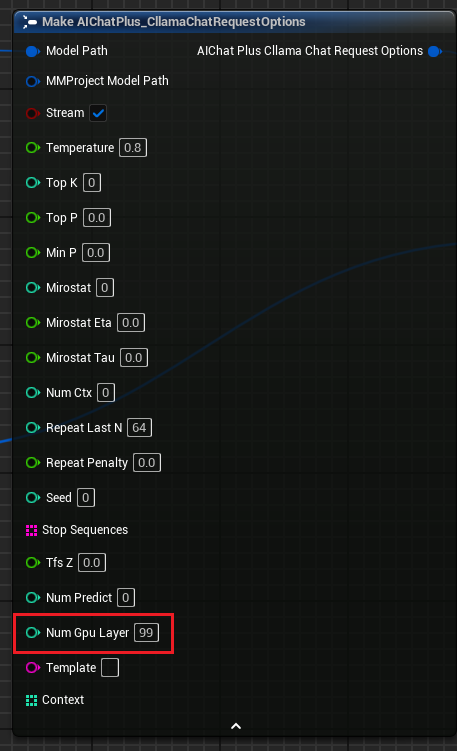
KeepAlive
"Cllama Chat Request Options" adds a parameter "KeepAlive" that allows the loaded model file to remain in memory after use, enabling direct utilization for subsequent requests and reducing the frequency of model loads. KeepAlive specifies the duration for which the model is retained; 0 means it is not retained and gets released immediately after use, while -1 indicates permanent retention. Each request's Options can assign a different KeepAlive value, with new settings overriding previous ones. For example, initial requests might set KeepAlive=-1 to keep the model in memory, then the final request could set KeepAlive=0 to release the model file.
Handling model files within the packed .Pak
After enabling Pak packaging, all the project's resource files will be placed in the .Pak file, including the offline model gguf files as well.
Since llama.cpp cannot directly read .Pak files, it is necessary to extract the offline model files from the .Pak files and place them into the file system.
AIChatPlus provides a utility function that automatically copies and processes model files from .Pak archives, placing them in the Saved folder:
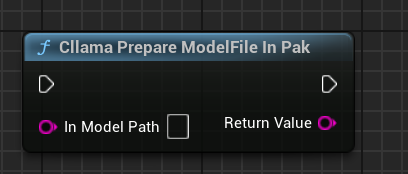
Alternatively, you can handle the model files within the .Pak yourself. The key is to extract the files, as llama.cpp cannot properly read the .Pak format.
Functional Nodes
Cllama provides several functional nodes for easily retrieving the current environment status.
"Cllama Is Valid": Determine if Cllama llama.cpp is properly initialized

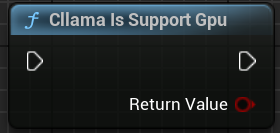
"Cllama Is Support Gpu": Determines whether llama.cpp supports GPU backend in the current environment
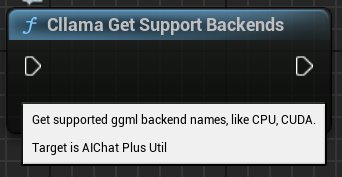
"Cllama Get Support Backends": Retrieves all currently supported backends by llama.cpp
"Cllama Prepare ModelFile In Pak": Automatically copies model files from Pak to the file system.

Original: https://wiki.disenone.site/en
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
This post is translated using ChatGPT. Please provide feedback herePointing out any omissions therein.