Planos - Cllama (llama.cpp) (obsoleto)
Obsoleto
Cllama ha sido marcado como obsoleto y ya no recibe mantenimiento.
Las funciones originales de Cllama son proporcionadas por CllamaServerPara soportar.
Modelo sin conexión
Cllama está basado en llama.cpp y admite el uso fuera de línea de modelos de inferencia de IA.
Como está sin conexión, necesitamos preparar primero los archivos del modelo, como descargar el modelo fuera de línea desde el sitio web de HuggingFace: Qwen1.5-1.8B-Chat-Q8_0.gguf
Coloca el modelo en alguna carpeta, por ejemplo, en el directorio del proyecto del juego Content/LLAMA.
Una vez que tenemos el archivo del modelo fuera de línea, podemos utilizar Cllama para chatear con IA.
Chat de texto
Chatear con texto usando Cllama
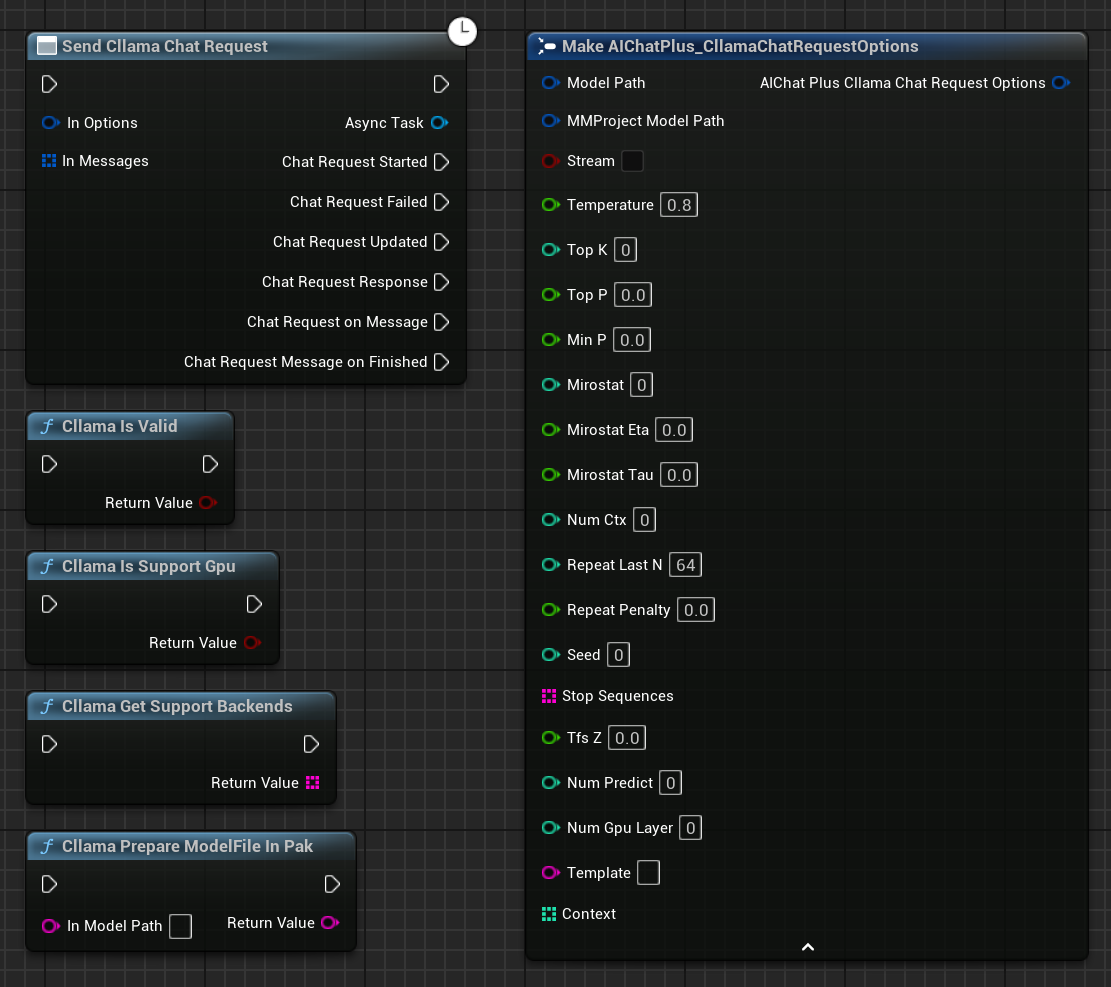
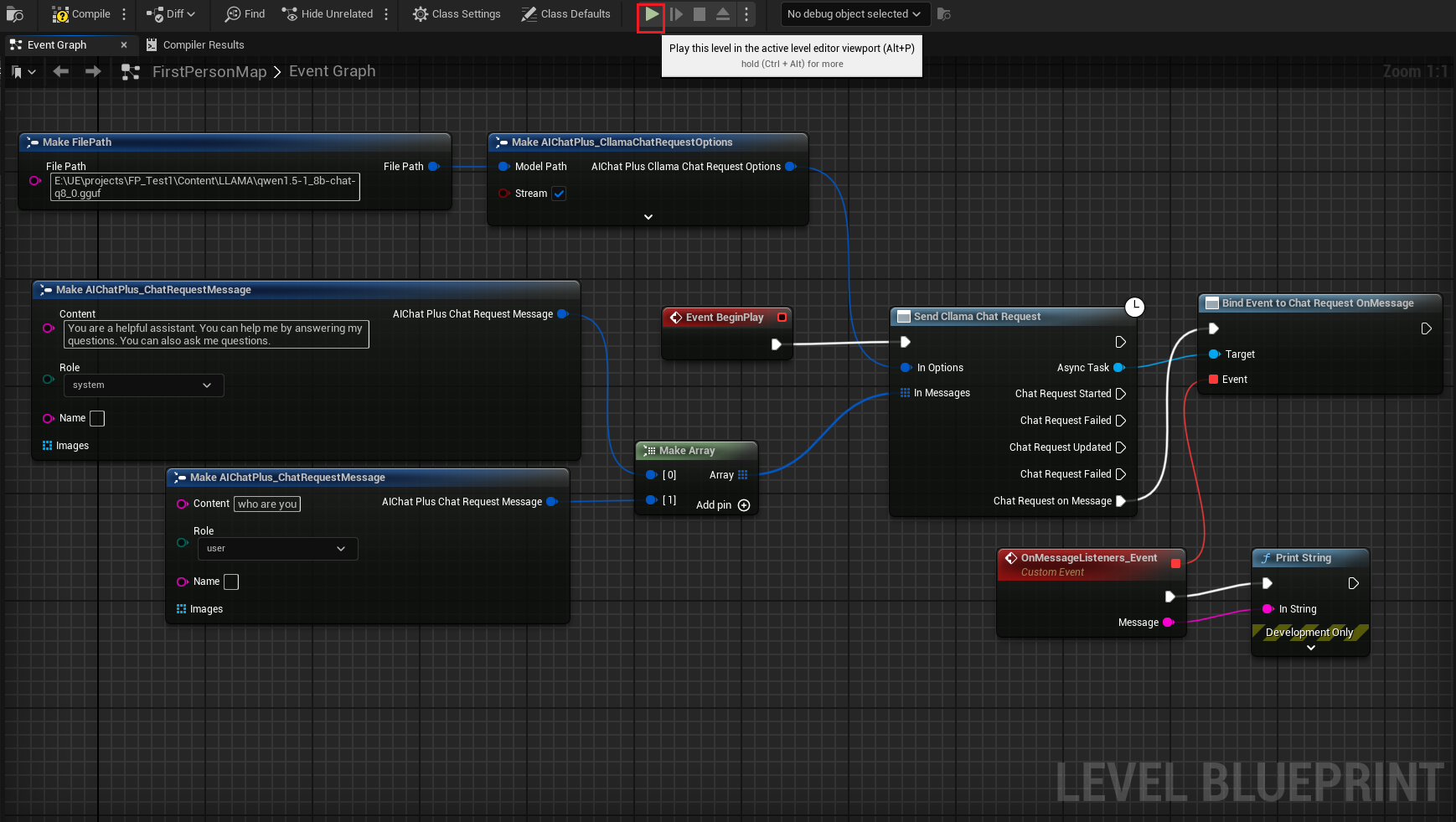
Haz clic derecho en el plano para crear un nodo Send Cllama Chat Request
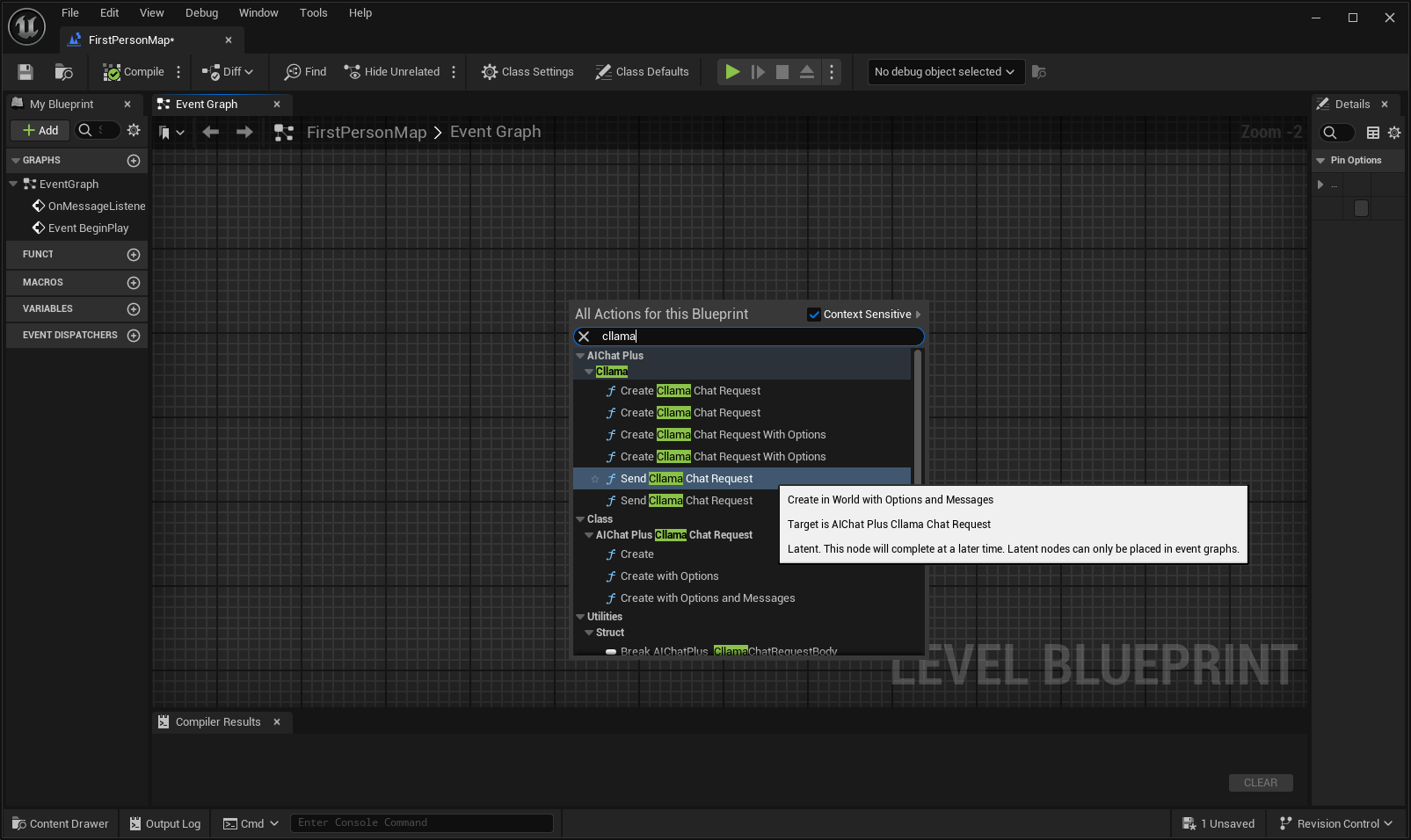
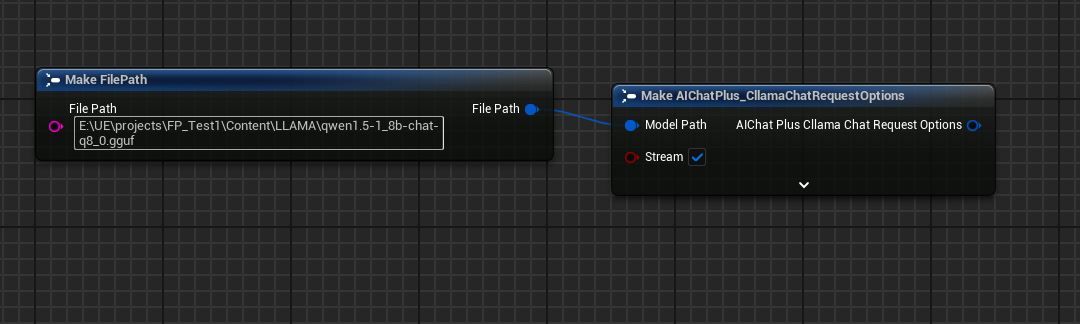
Crear el nodo Options y establecer Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
Crear Messages, agregando respectivamente un System Message y un User Message
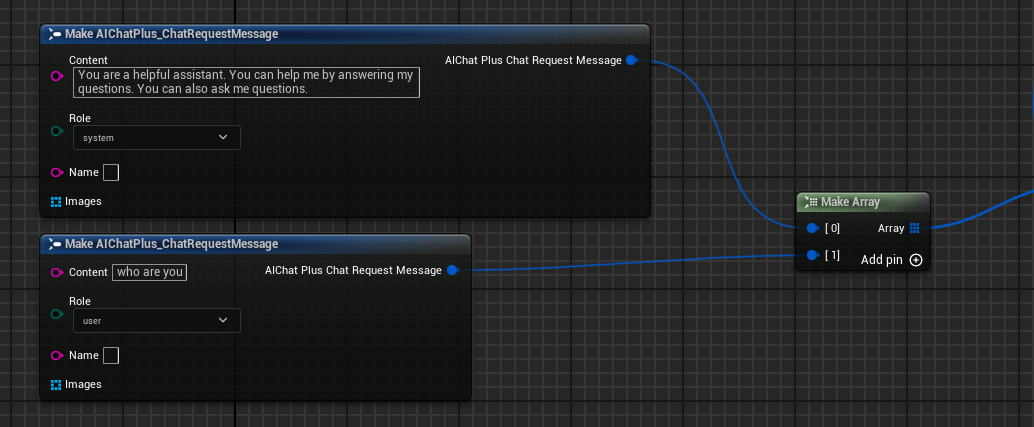
Crear un Delegate que reciba la información de salida del modelo y la imprima en pantalla
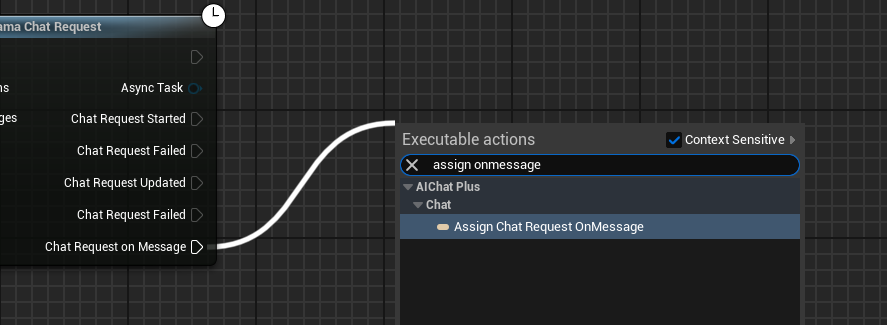
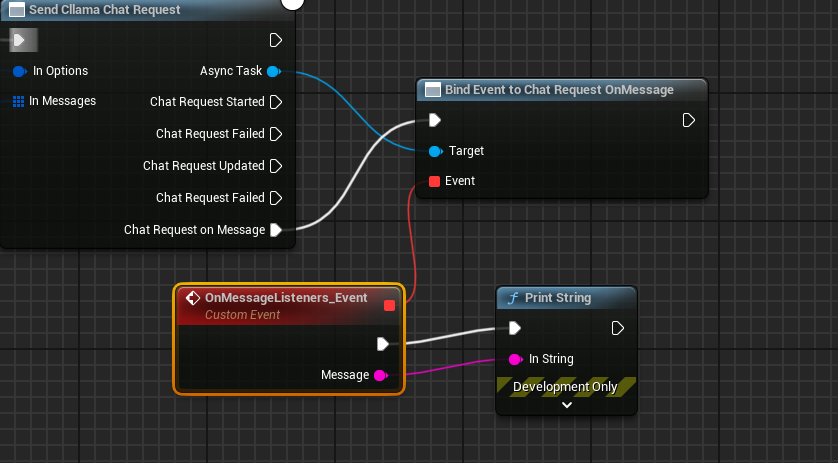
El esquema completo se ve así, ejecuta el esquema y podrás ver en la pantalla del juego los mensajes impresos que devuelve el modelo grande.
Generación de texto a partir de imágenes Llava
Cllama también admite experimentalmente la biblioteca llava, proporcionando capacidades de visión.
Primero, prepara los archivos del modelo multimodal sin conexión, como Moondream (moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf)o Qwen2-VL (Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf) u otros modelos multimodales compatibles con llama.cpp.
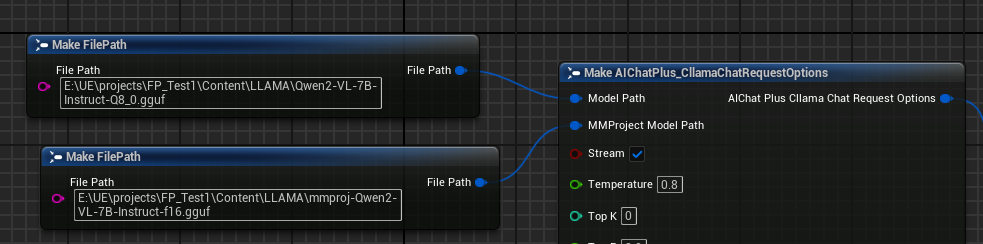
Crear el nodo Options y establecer los parámetros "Model Path" y "MMProject Model Path" a sus correspondientes archivos de modelo Multimodal.
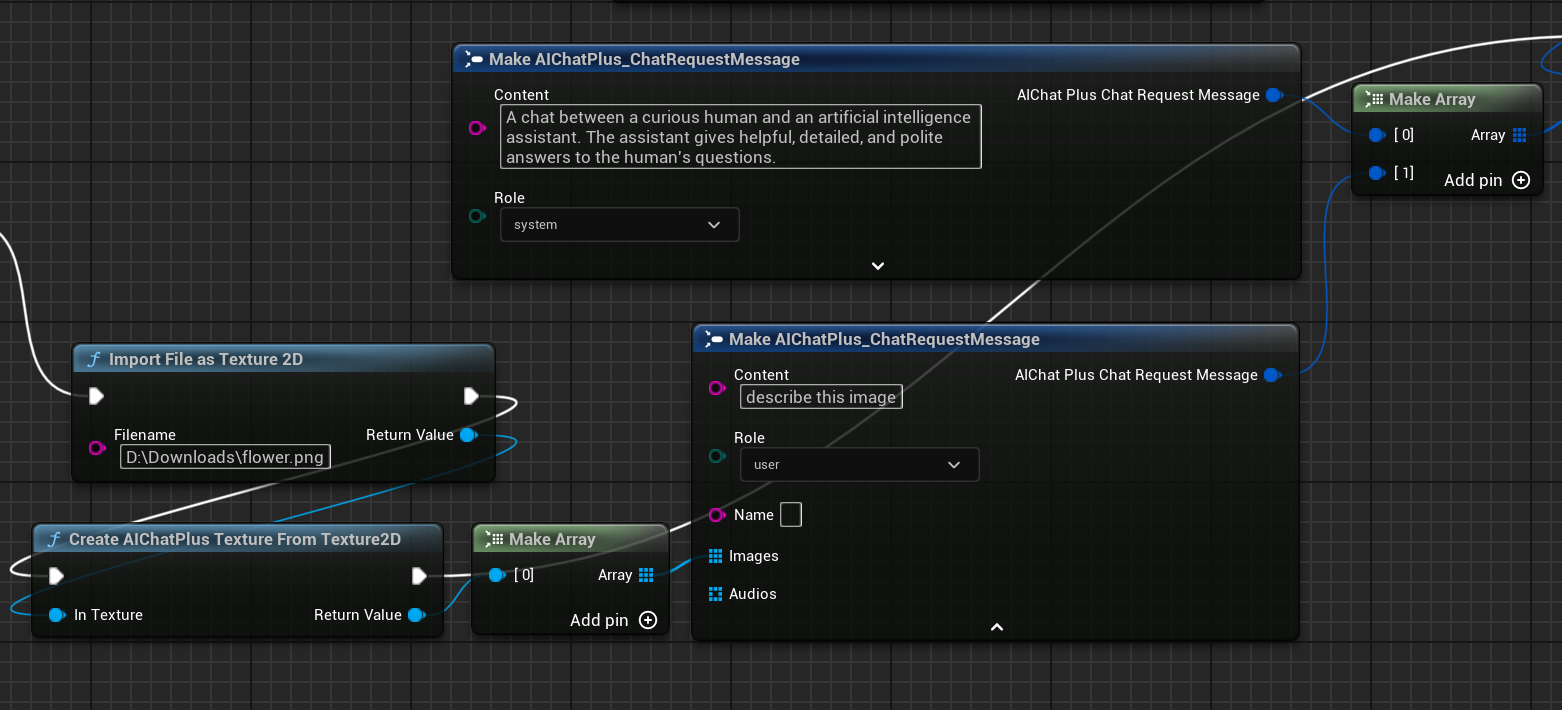
Crear un nodo para leer el archivo de imagen flower.png y configurar los mensajes.

El nodo final recibe la información devuelta y la imprime en la pantalla, el esquema completo se ve así:
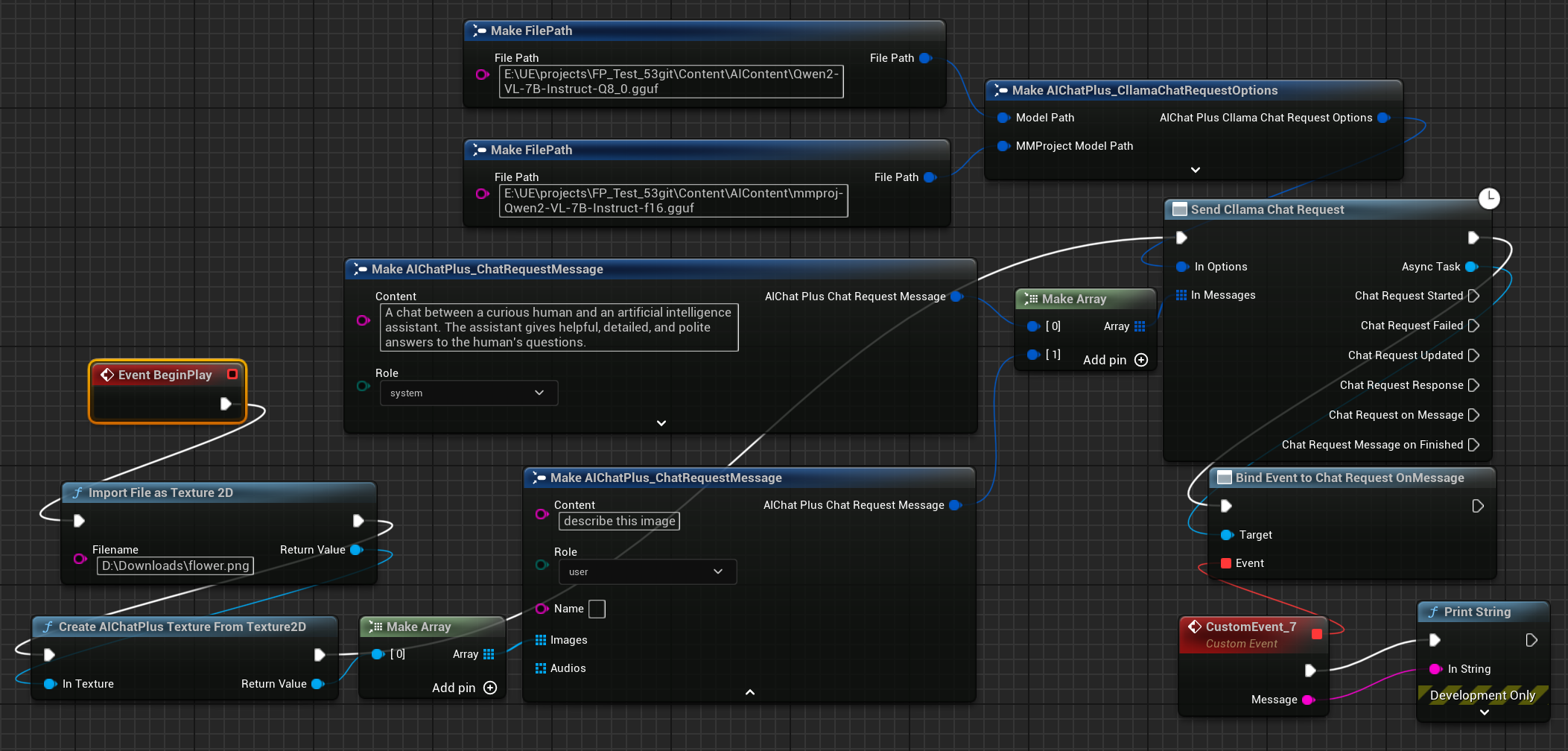
Ejecuta el plano para ver el texto devuelto.

llama.cpp usa GPU
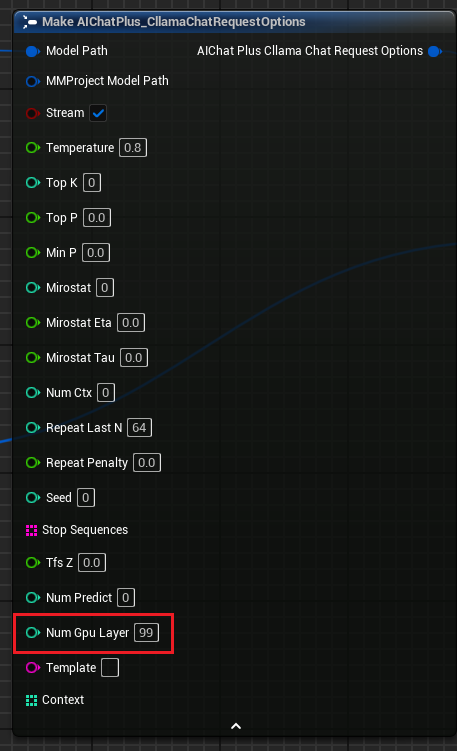
Opciones de Solicitud de Chat Cllama" aumenta el parámetro "Num Gpu Layer", que permite configurar la carga útil de GPU de llama.cpp y controlar el número de capas que deben calcularse en la GPU. Como se muestra en la imagen.
KeepAlive
Opciones de Solicitud de Chat Cllama
Se ha añadido el parámetro "KeepAlive", que permite mantener el archivo del modelo cargado en la memoria después de su lectura, facilitando su uso directo en la próxima ocasión y reduciendo así la cantidad de veces que el modelo necesita ser leído.
- KeepAlive representa el tiempo que el modelo permanece en memoria:
- 0: No se retiene; se libera inmediatamente después de su uso.
- -1: Se retiene permanentemente.
Cada solicitud puede configurar un valor distinto de KeepAlive en las Options, sobrescribiendo el valor anterior. Por ejemplo:
- En las primeras solicitudes, puedes establecer KeepAlive=-1 para mantener el modelo en memoria.
- En la última solicitud, puedes configurar KeepAlive=0 para liberar el archivo del modelo.
Procesamiento de archivos de modelos en .Pak después del empaquetado
Después de activar el empaquetado Pak, todos los archivos de recursos del proyecto se guardarán en un archivo .Pak, que, por supuesto, incluye también el archivo de modelo offline gguf.
Como llama.cpp no admite la lectura directa de archivos .Pak, es necesario copiar los archivos del modelo offline del archivo .Pak al sistema de archivos.
AIChatPlus ofrece una función que permite copiar y gestionar automáticamente los archivos de modelo de .Pak, colocándolos en la carpeta Saved:
O también puedes manejar tú mismo los archivos de modelos en .Pak; la clave está en copiar los archivos fuera, ya que llama.cpp no puede leer correctamente los .Pak.
Nodo de funcionalidad
Cllama proporciona algunos nodos funcionales para facilitar la obtención del estado actual del entorno.
"Cllama Es Válido": Determina si Cllama llama.cpp está inicializado correctamente.

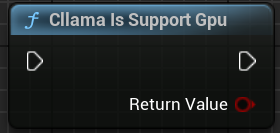
"Cllama Is Support Gpu": Determina si llama.cpp admite el backend GPU en el entorno actual.
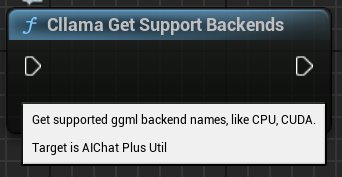
"Cllama Get Support Backends": Obtén todos los backends soportados actualmente por llama.cpp
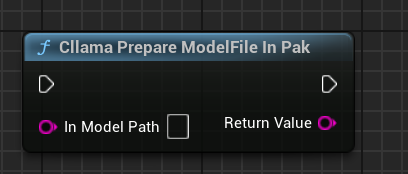
"Llama Prepare ModelFile In Pak": Copia automáticamente los archivos de modelo en Pak al sistema de archivos.

Original: https://wiki.disenone.site/es
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
Este post está traducido usando ChatGPT, por favor proporcione su retroalimentaciónSeñalar cualquier omisión en el texto.