Chapitre du Plan Bleu - Cllama (llama.cpp) (obsolète)
Obsolète
Cllama est marqué comme obsolète et n'est plus maintenu.
Les fonctionnalités originales de Cllama sont fournies par CllamaServerPour porter.
Modèle hors ligne
Cllama est basé sur llama.cpp et prend en charge l'utilisation hors ligne de modèles d'inférence d'IA.
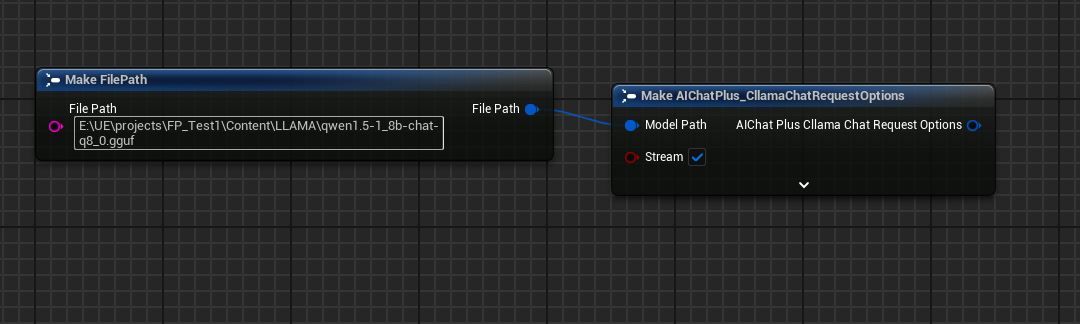
Étant donné qu'il s'agit d'une utilisation hors ligne, nous devons d'abord préparer les fichiers du modèle, par exemple en téléchargeant le modèle hors ligne depuis le site HuggingFace : Qwen1.5-1.8B-Chat-Q8_0.gguf
Placez le modèle dans un dossier spécifique, par exemple sous le répertoire Content/LLAMA du projet de jeu.
Une fois que nous avons les fichiers du modèle hors ligne, nous pouvons utiliser Cllama pour discuter avec l'IA.
Chat textuel
Utiliser Cllama pour discuter en texte
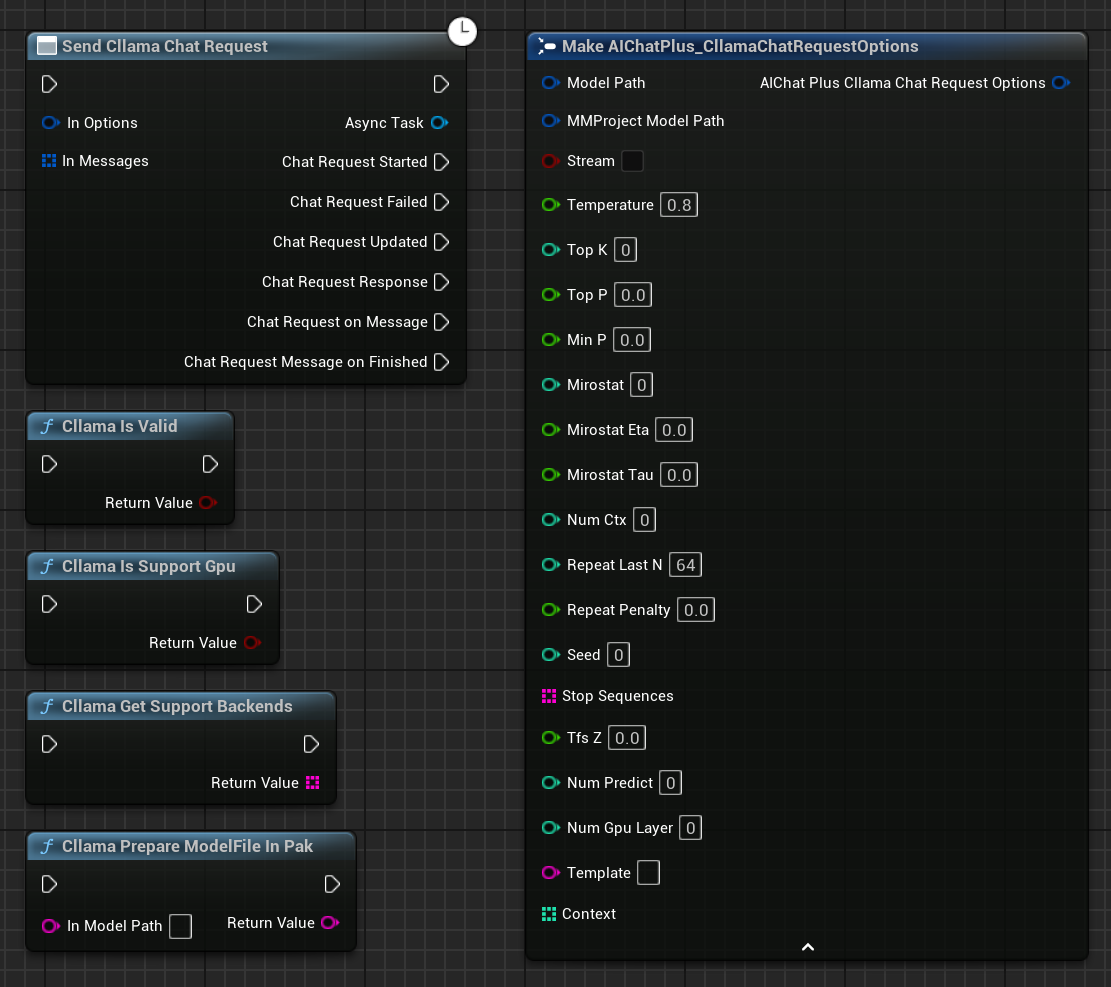
Cliquez avec le bouton droit dans le schéma pour créer un nœud Envoyer une demande de chat Cllama.
Créez un nœud Options et configurez Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
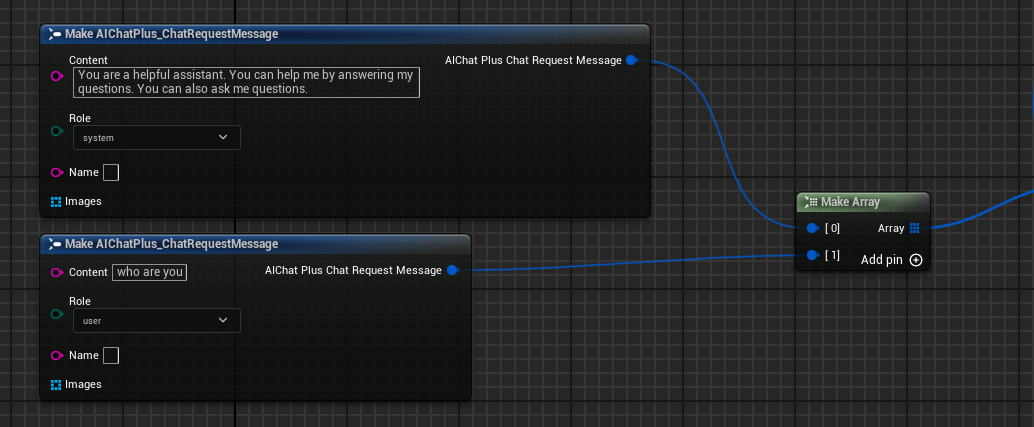
Créer Messages, ajouter respectivement un System Message et un User Message
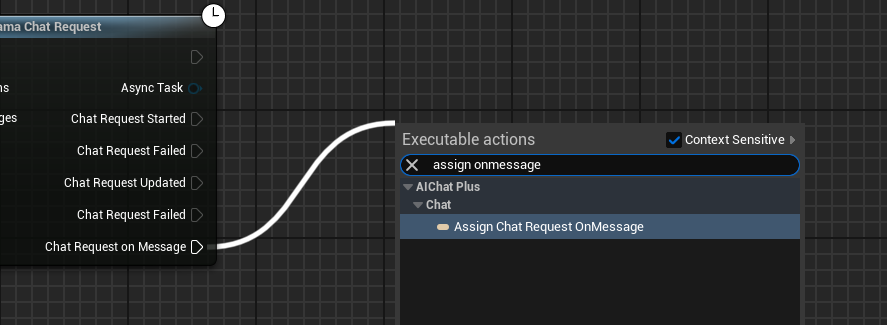
Créer un délégué pour recevoir les informations de sortie du modèle et les afficher à l'écran
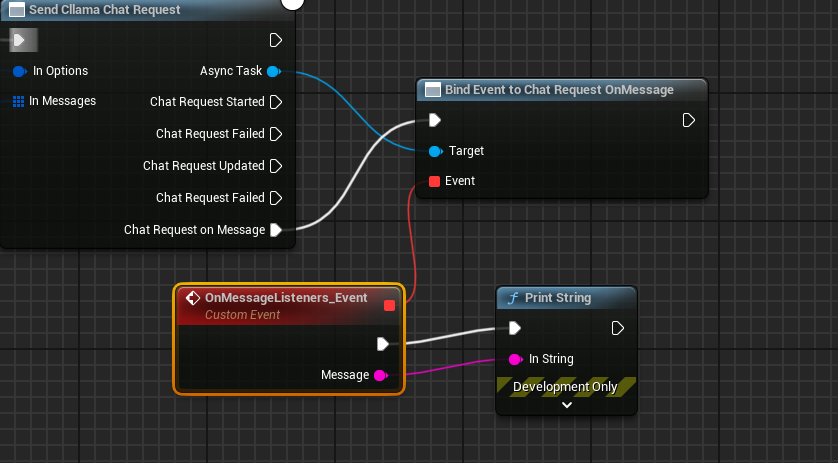
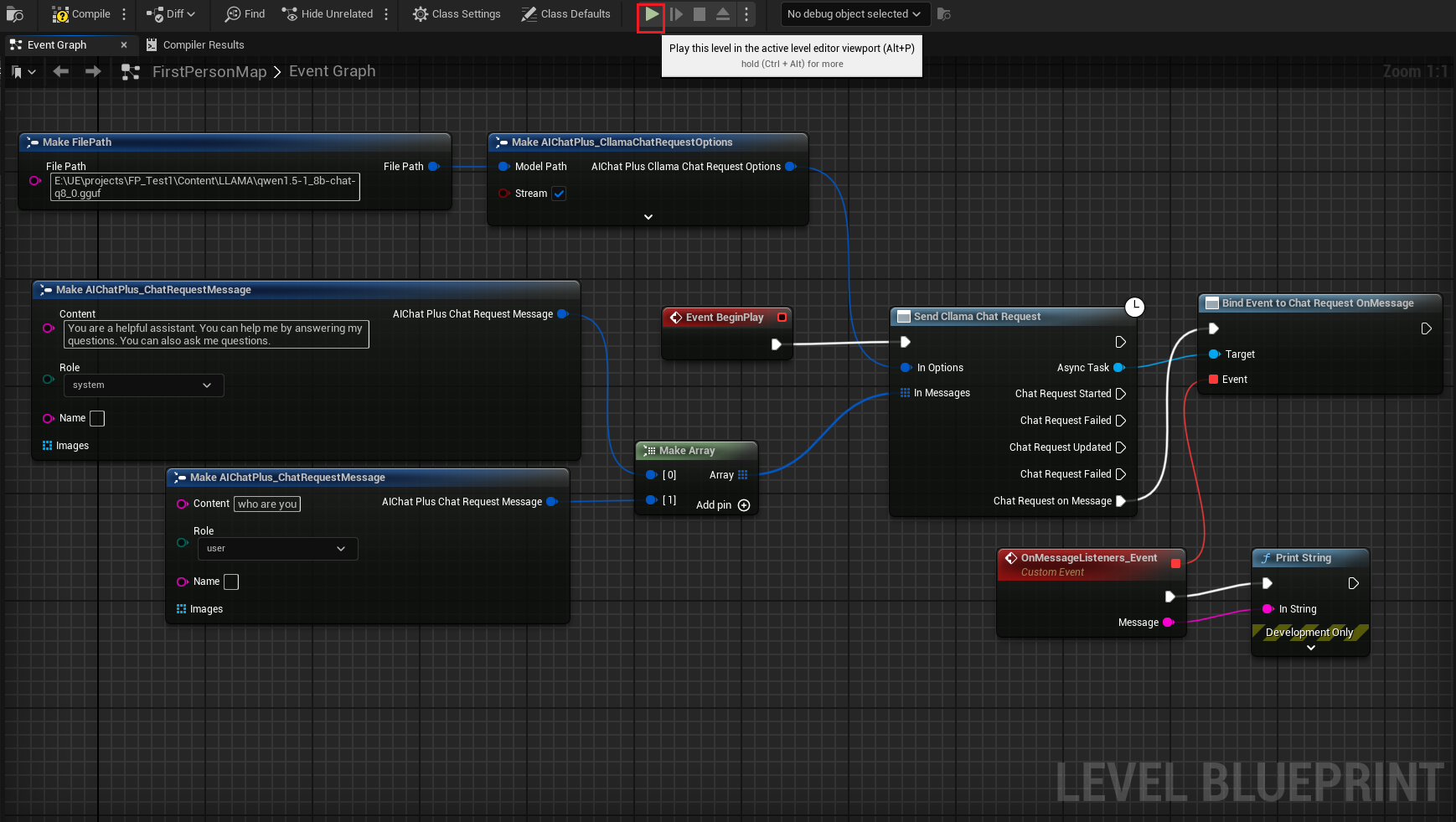
Le schéma complet ressemble à ceci. Exécutez-le et vous verrez l'écran du jeu afficher les messages renvoyés par le grand modèle.
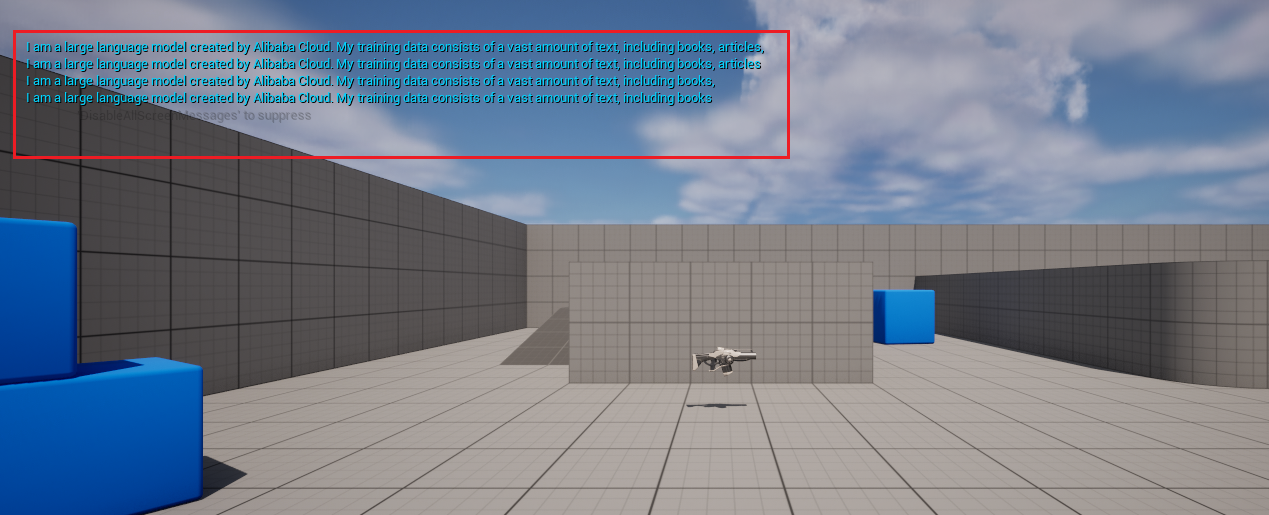
Génération de texte à partir d'images llava
Cllama supporte également de manière expérimentale la bibliothèque llava, offrant ainsi des capacités Vision.
Préparez d'abord les fichiers du modèle hors ligne Multimodal, par exemple Moondream (moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf) ou Qwen2-VL(Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf)ou tout autre modèle Multimodal pris en charge par llama.cpp.
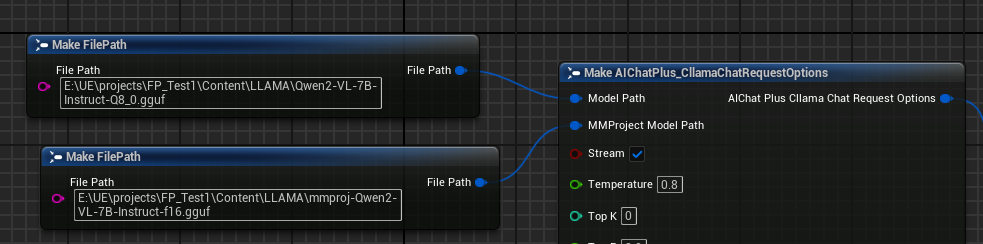
Créez un nœud Options et définissez respectivement les paramètres "Model Path" et "MMProject Model Path" sur les fichiers de modèle Multimodal correspondants.
Créer un nœud pour lire le fichier image flower.png et configurer les Messages

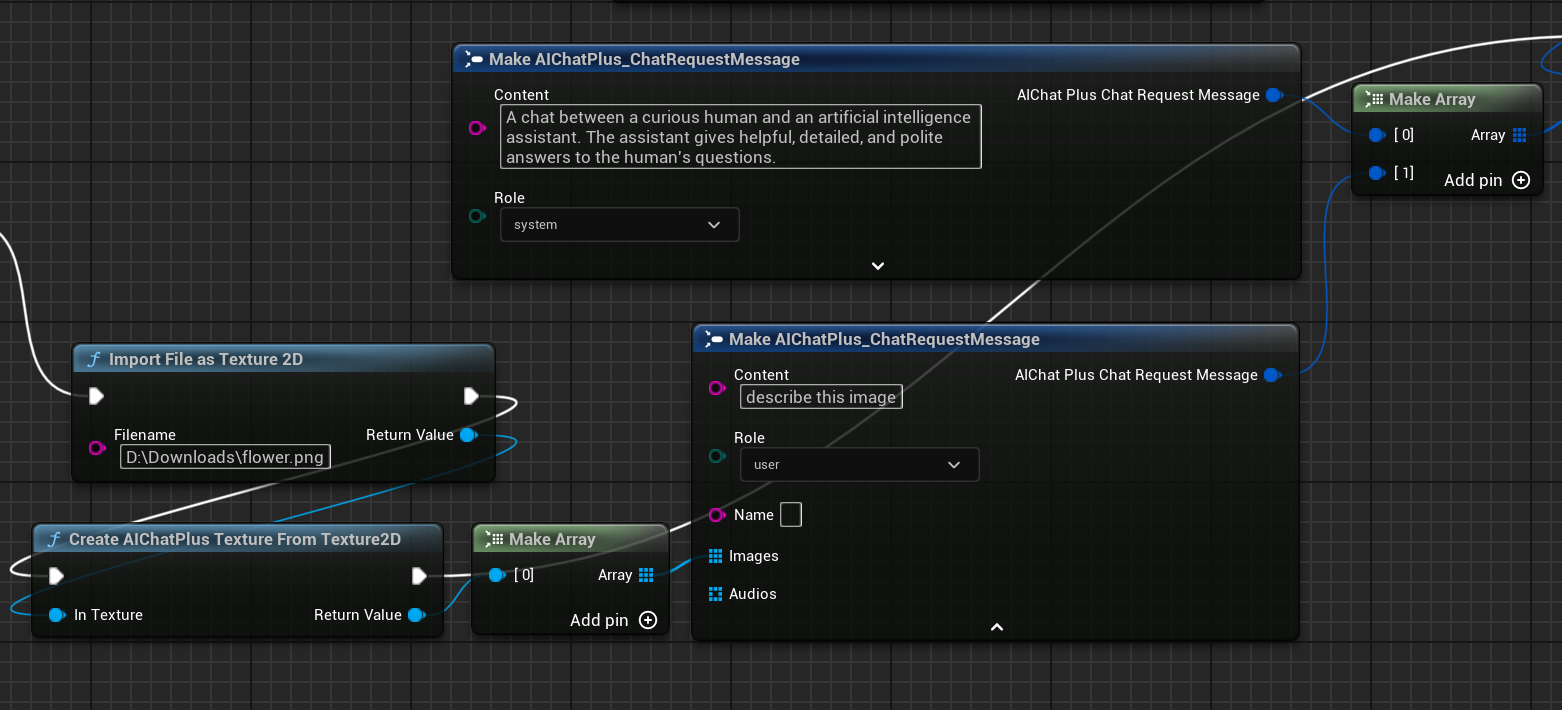
Enfin, le nœud de création final reçoit les informations retournées et les affiche à l'écran. Le schéma complet ressemble à cela.
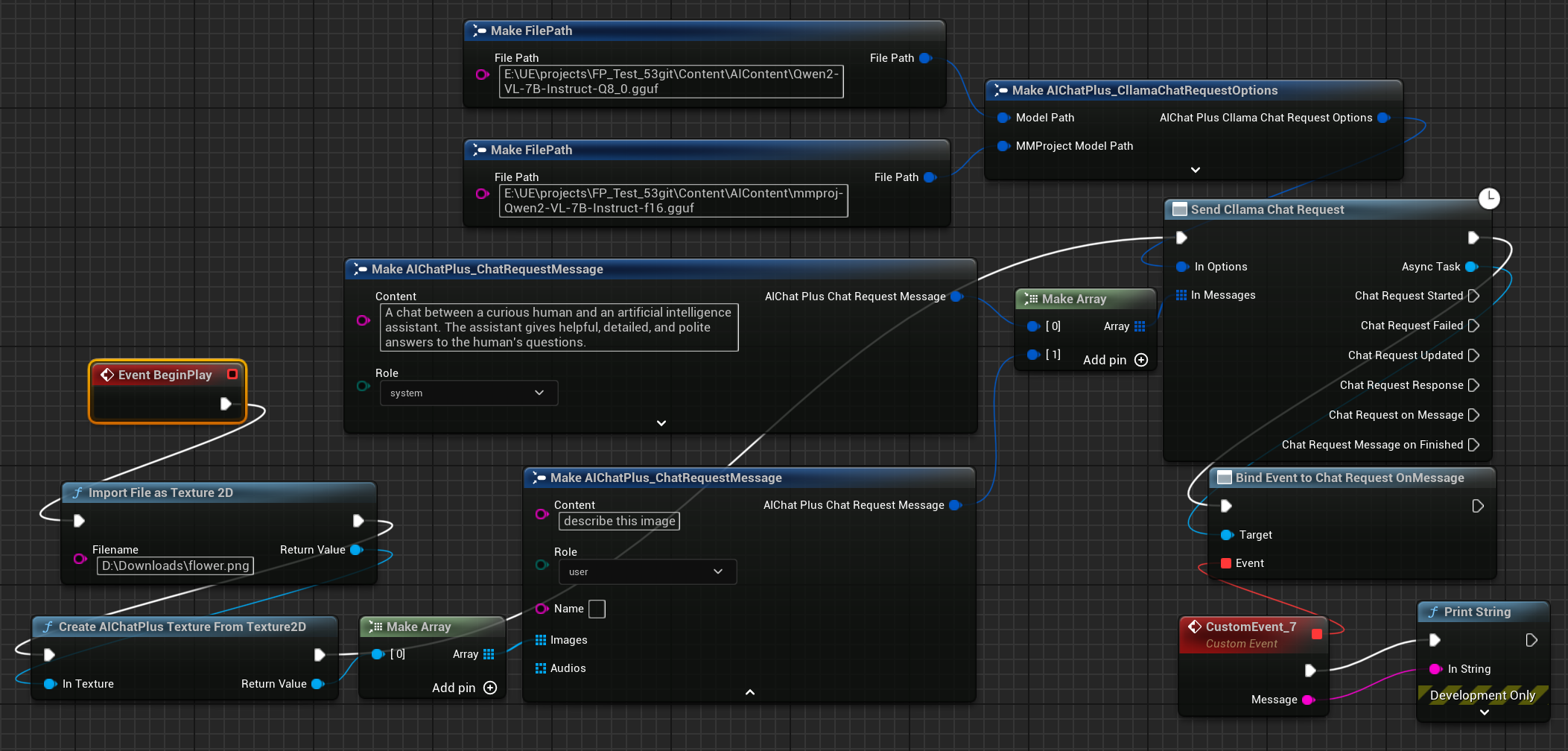
Lancer le plan pour voir le texte retourné

llama.cpp utilise le GPU
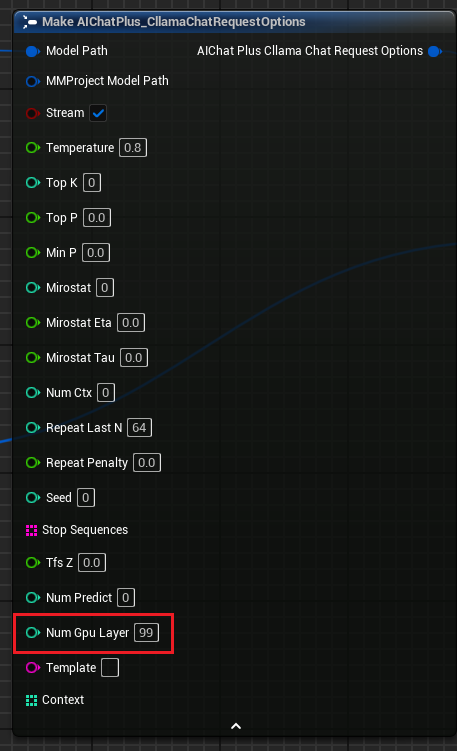
"Options de requête de chat Cllama" ajout du paramètre "Num Gpu Layer", permettant de configurer le payload GPU de llama.cpp et de contrôler le nombre de couches à calculer sur le GPU. Comme illustré.
KeepAlive
"Cllama Chat Options de Demande" Ajoute le paramètre "KeepAlive", qui permet de conserver le fichier de modèle en mémoire après sa lecture, facilitant ainsi son utilisation ultérieure sans avoir à le recharger, réduisant ainsi le nombre de lectures du modèle. KeepAlive définit la durée de conservation du modèle en mémoire : 0 signifie aucune conservation, libérant immédiatement le modèle après utilisation ; -1 signifie une conservation permanente. Chaque demande peut définir un KeepAlive différent dans ses Options, la nouvelle valeur remplaçant l’ancienne. Par exemple, les premières demandes peuvent être configurées avec KeepAlive=-1 pour maintenir le modèle en mémoire, jusqu’à ce qu’une demande finale définisse KeepAlive=0, libérant ainsi le fichier de modèle.
Traiter les fichiers de modèle dans le .Pak après l'empaquetage
Lorsque l'emballage Pak est activé, tous les fichiers de ressources du projet seront placés dans un fichier .Pak, y compris bien sûr le fichier de modèle hors ligne gguf.
Comme llama.cpp ne prend pas en charge la lecture directe des fichiers .Pak, il est nécessaire de copier les fichiers du modèle hors ligne depuis le fichier .Pak vers le système de fichiers.
AIChatPlus propose une fonctionnalité permettant de copier automatiquement les fichiers de modèle depuis le .Pak et de les placer dans le dossier Saved :
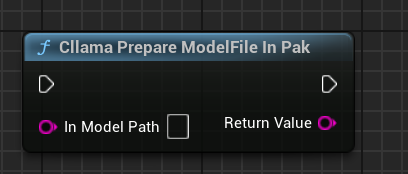
Ou bien vous pouvez manipuler vous-mêmes les fichiers de modèle contenus dans le .Pak, l'essentiel est d'en extraire les fichiers car llama.cpp ne peut pas les lire correctement depuis le .Pak.
Nœud fonctionnel
Cllama propose des nœuds fonctionnels pour faciliter l'obtention de l'état dans l'environnement actuel
"Cllama Est Valide":Vérifie si Cllama llama.cpp est correctement initialisé.

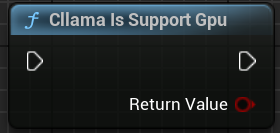
"Cllama Is Support Gpu" : Détermine si llama.cpp prend en charge le backend GPU dans l'environnement actuel
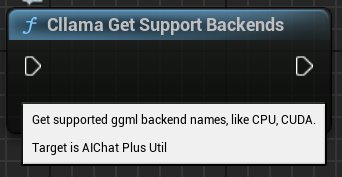
"Cllama Get Support Backends": Obtenir tous les backends actuellement pris en charge par llama.cpp
"Copier automatiquement le fichier modèle depuis Pak vers le système de fichiers"

Original: https://wiki.disenone.site/fr
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
Ce message a été traduit avec ChatGPT, veuillez donner votre retourSignalisez toute omission éventuelle.