Plan directeur - CllamaServer (serveur llama.cpp)
Aperçu
CllamaServer est une implémentation basée sur le mode Serveur de llama.cpp, permettant de démarrer localement un serveur compatible avec l'API OpenAI et prenant en charge diverses fonctionnalités :
- Service d'inférence locale : Lancez un serveur d'inférence IA en local, sans dépendre d'API externes
- Compatibilité avec l'API OpenAI : Utilisation d'un format d'API compatible avec OpenAI pour faciliter la migration et l'intégration
- Prise en charge multi-session : Prise en charge de plusieurs requêtes simultanées
- Appel d'outil : Prend en charge la fonction d'appel de fonction
- Reconnaissance vocale: Prend en charge la fonctionnalité Speech-to-Text
- Gestion visuelle: L'éditeur intègre une interface de gestion du serveur.
Différences avec Cllama : * Cllama : Charge directement le modèle dans le processus pour l'inférence, ne peut traiter qu'une seule requête à la fois. * CllamaServer : Démarrer un serveur HTTP autonome capable de gérer plusieurs requêtes simultanées, avec une API compatible au format OpenAI
Préparatifs
Puisqu'il s'agit d'une exécution locale, il faut d'abord préparer le fichier de modèle hors ligne, par exemple en le téléchargeant depuis HuggingFace : Qwen1.5-1.8B-Chat-Q8_0.gguf
Placez le modèle dans un dossier spécifique, par exemple dans le répertoire du projet de jeu Content/LLAMA.
Création de CllamaServer
Créer un serveur à l'aide d'un blueprint
Cliquez avec le bouton droit dans le blueprint pour créer un nœud Create Cllama Server In World.
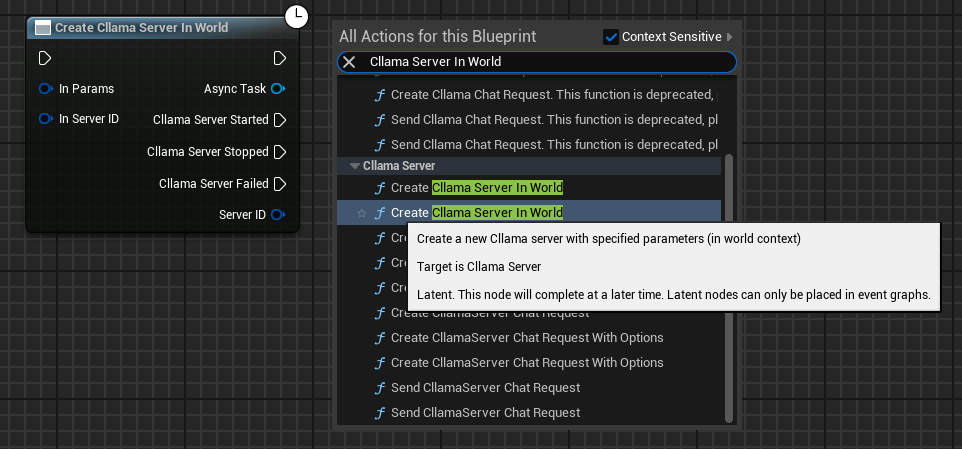
Configurer les paramètres du serveur
Créer le nœud Cllama Server Param et configurer les paramètres clés :
- Modèle : Chemin du fichier modèle (requis)
- Port : Port du serveur (0 signifie une allocation automatique)
- Hôte : adresse d'écoute, par défaut
127.0.0.1 - NGpuLayers : Nombre de couches GPU (-1 signifie utiliser toutes les GPU)
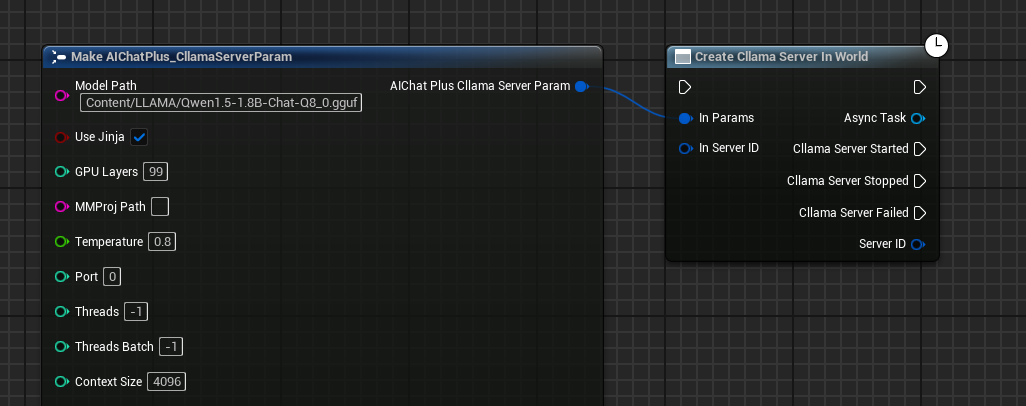
Associer les événements de rappel
Liaison des événements de rappel du serveur :
- On Started : Déclenché lorsque le serveur démarre avec succès
- On Stopped : Déclenché lorsque le serveur s'arrête
- On Failed : Se déclenche lorsque le démarrage du serveur échoue
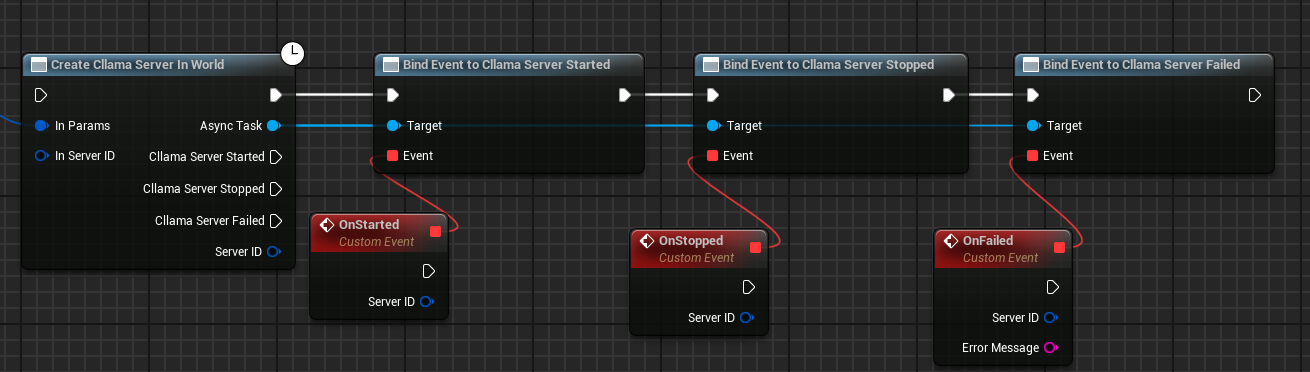
Plan complet de création
Le plan complet de création du serveur est le suivant :
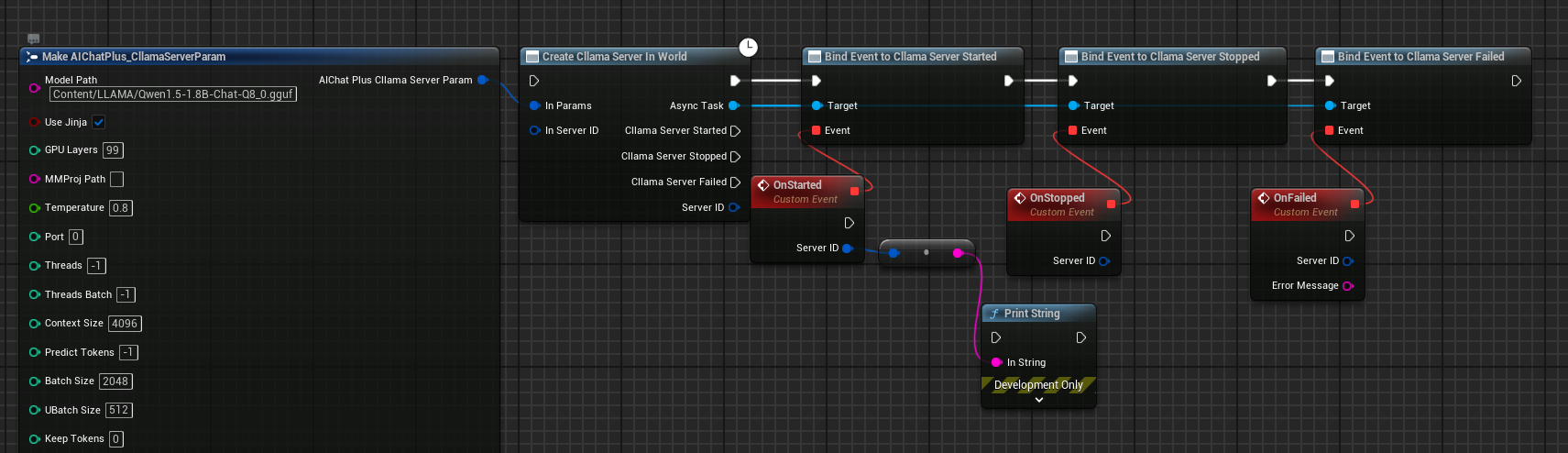
Après avoir exécuté le plan directeur, le démarrage réussi du serveur déclenchera l'événement On Started.
Détails des paramètres du serveur
FAIChatPlus_CllamaServerParam est une structure qui contient les paramètres suivants :
Paramètres courants
| Paramètre | Type | Valeur par défaut | Description |
|---|---|---|---|
| Modèle | FString | - | Chemin du fichier modèle (obligatoire) |
| Port | int32 | 0 | Port d'écoute, 0 signifie allocation automatique |
| Hôte | ChaîneF | 127.0.0.1 | Adresse d'écoute |
| NGpuLayers | int32 | -1 | Nombre de couches GPU, -1 signifie toutes |
| bUseJinja | bool | false | Utiliser le modèle Jinja |
| MMProj | FString | - | Chemin du fichier de projection multimodale |
| Température | float | 0.8 | Température d'échantillonnage |
Argument de raisonnement
| Paramètre | Type | Valeur par défaut | Description |
|---|---|---|---|
| CtxSize | int32 | 4096 | Taille du contexte |
| NPredict | int32 | -1 | Nombre de Tokens à prédire, -1 signifie illimité |
| Threads | int32 | -1 | Nombre de threads CPU, -1 signifie automatique |
| BatchSize | int32 | 2048 | Taille du lot (batch) |
Paramètres d'échantillonnage
| Paramètre | Type | Valeur par défaut | Description |
|---|---|---|---|
| TopK | int32 | 40 | Échantillonnage Top-K |
| TopP | float | 0.9 | Échantillonnage Top-P |
| MinP | float | 0.1 | Échantillonnage Min-P |
| RepeatPenalty | float | 1.0 | Pénalité de répétition |
Paramètres du serveur
| Paramètre | Type | Valeur par défaut | Description |
|---|---|---|---|
| ApiKey | FString | - | Clé API (optionnelle) |
| Timeout | int32 | 600 | Durée d'expiration (secondes) |
| Parallèle | int32 | 1 | Nombre de séquences parallèles |
| bNoWebUI | bool | false | Désactiver l'interface Web |
| bVerbose | bool | false | Journal détaillé |
Utiliser CllamaServer pour discuter
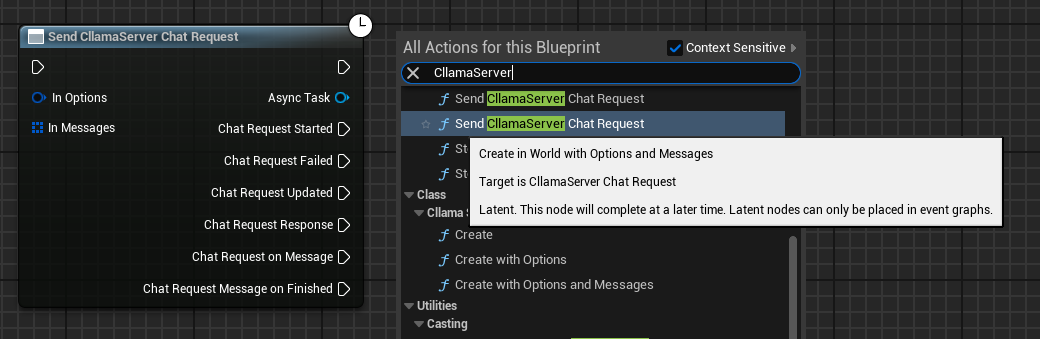
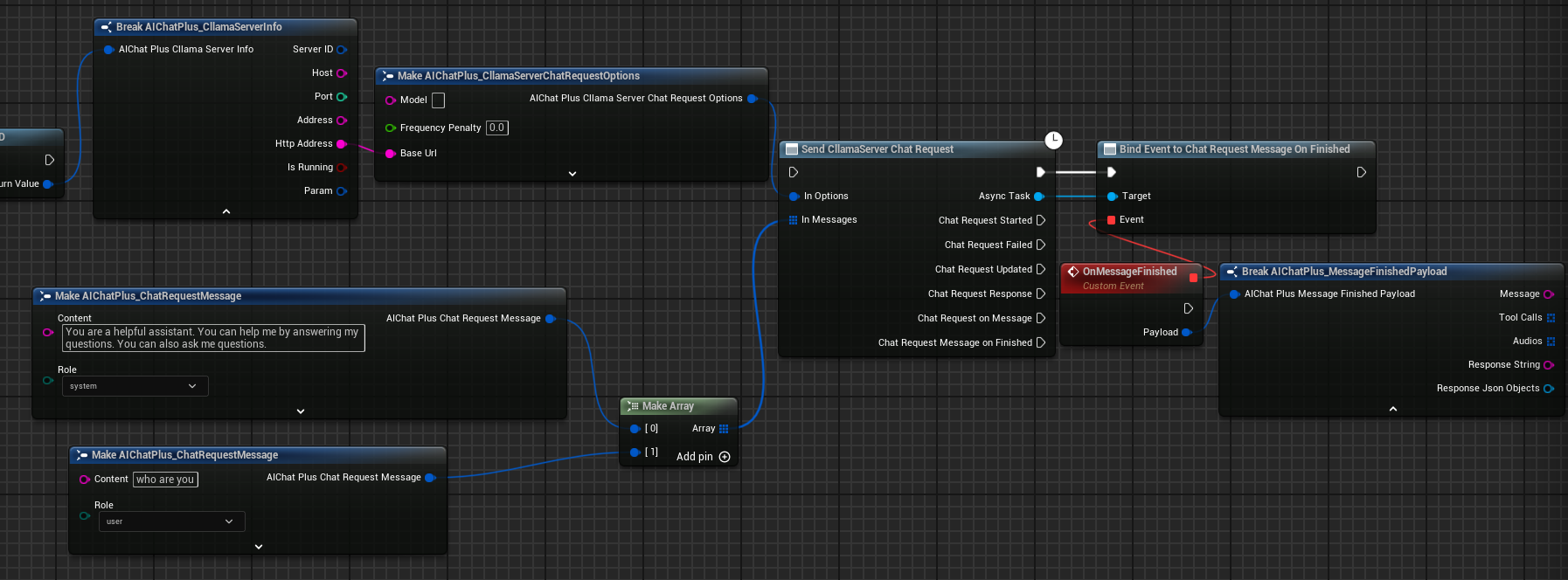
Créer une demande de chat
Une fois le serveur démarré avec succès, vous pouvez utiliser le nœud Send CllamaServer Chat Request pour envoyer une demande de chat.
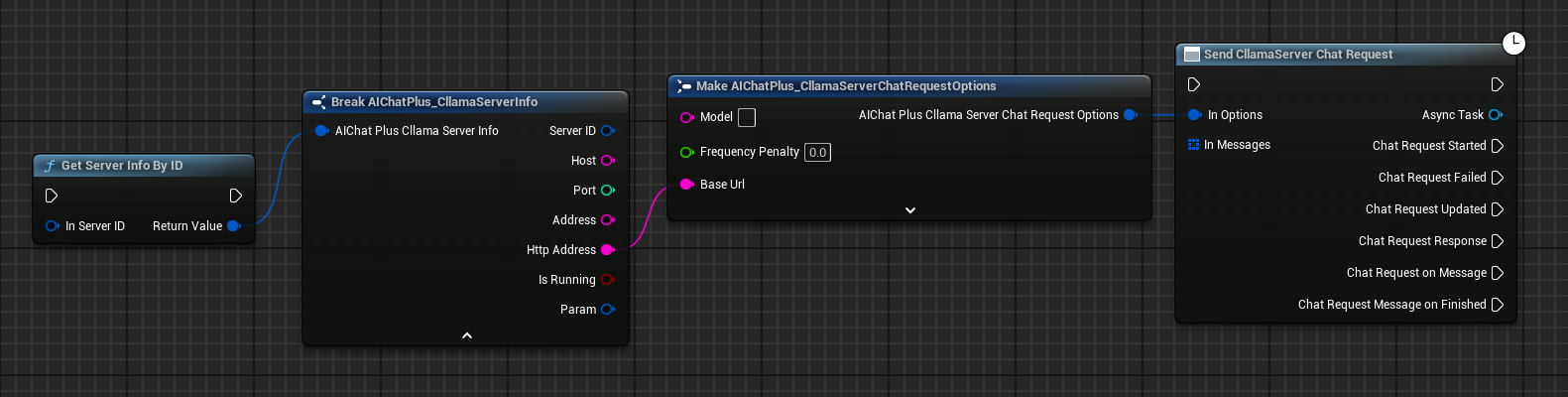
Configurer les Options de Chat
Créer le nœud CllamaServer Chat Request Options, définissez BaseUrl comme l'adresse du serveur.
Vous pouvez obtenir les informations du serveur via le nœud Get Server Info By ID.
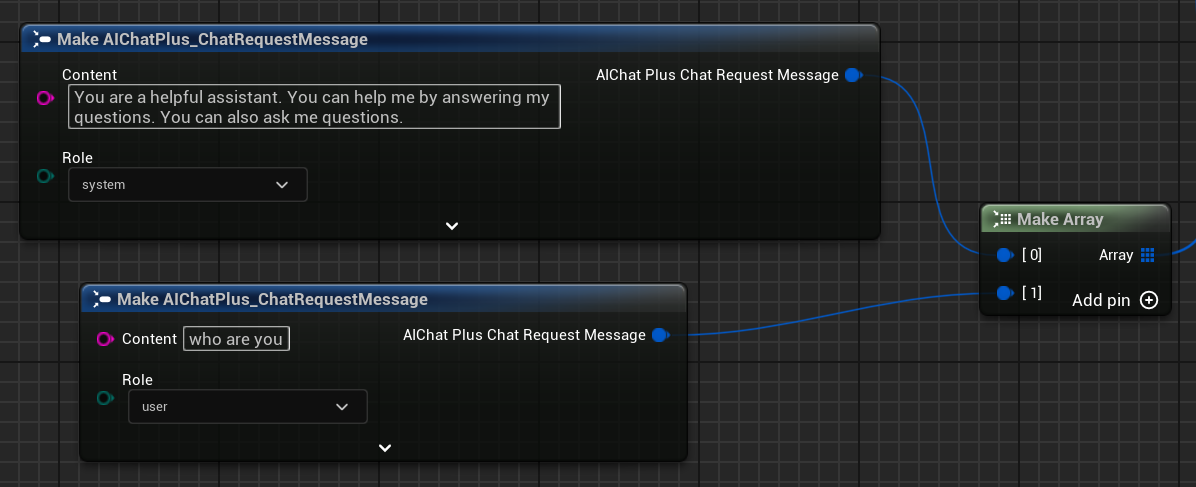
Créer des Messages
Créez un tableau Messages, ajoutez un Message Système et un Message Utilisateur.
Associer des rappels pour traiter les réponses
Lieez l'événement On Message ou On Message Finished pour recevoir les réponses du modèle.
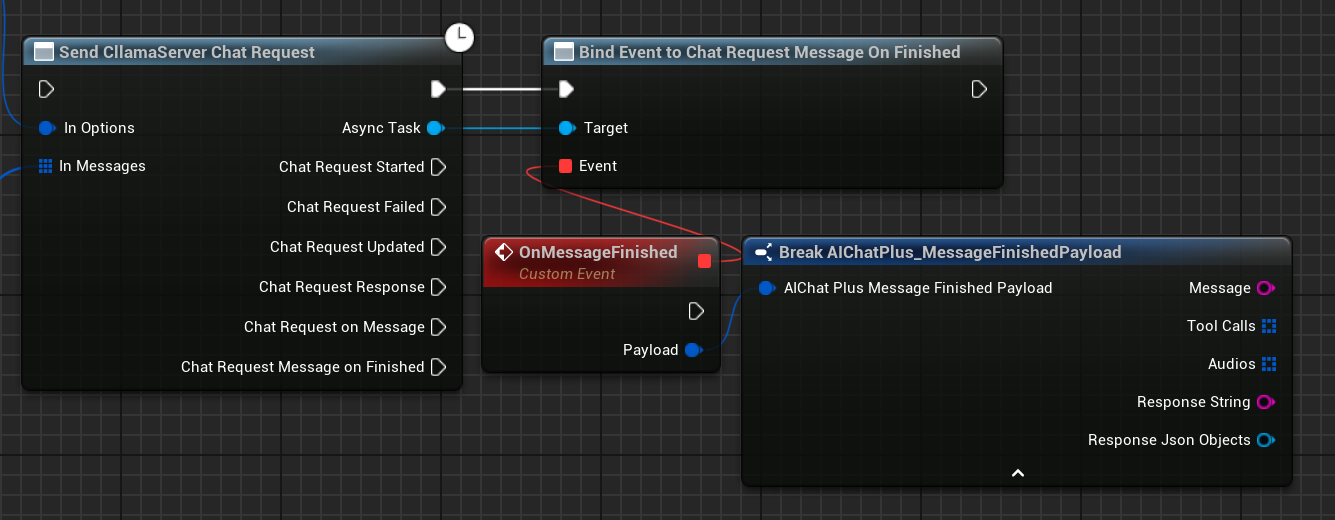
Plan complet de discussion
Le plan complet de conversation est le suivant :
Résultat de l'exécution
Exécutez le modèle et vous verrez le message renvoyé par le modèle s'afficher à l'écran.
Gestion des serveurs
Obtenir les informations du Serveur
Utilisez le nœud Get Server Info pour obtenir les détails du serveur.
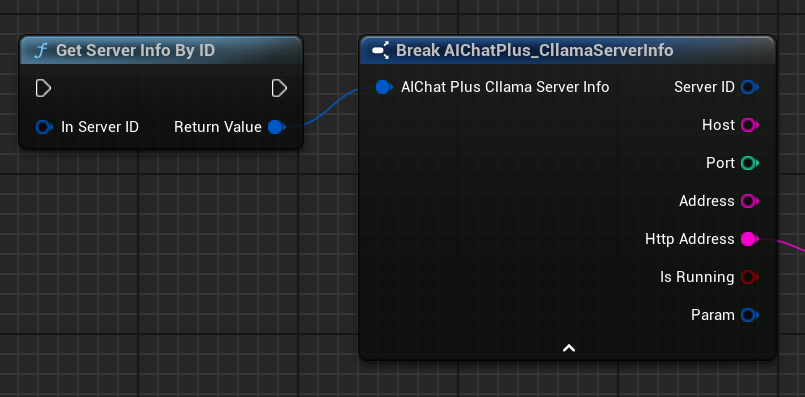
Les informations sur le serveur contiennent les éléments suivants : * ServerID : ID unique du serveur * Hôte : Adresse d'écoute * Port: Port d'écoute * Adresse : Adresse complète (hôte:port) * HttpAddress: Adresse HTTP (http://host:port) * bIsRunning: Est-ce en cours d'exécution * Param: Paramètre du serveur
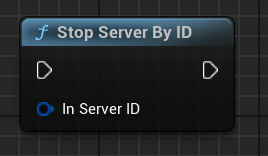
Arrêter le serveur
Utilisez le nœud Stop Server By ID pour arrêter le serveur actuel.
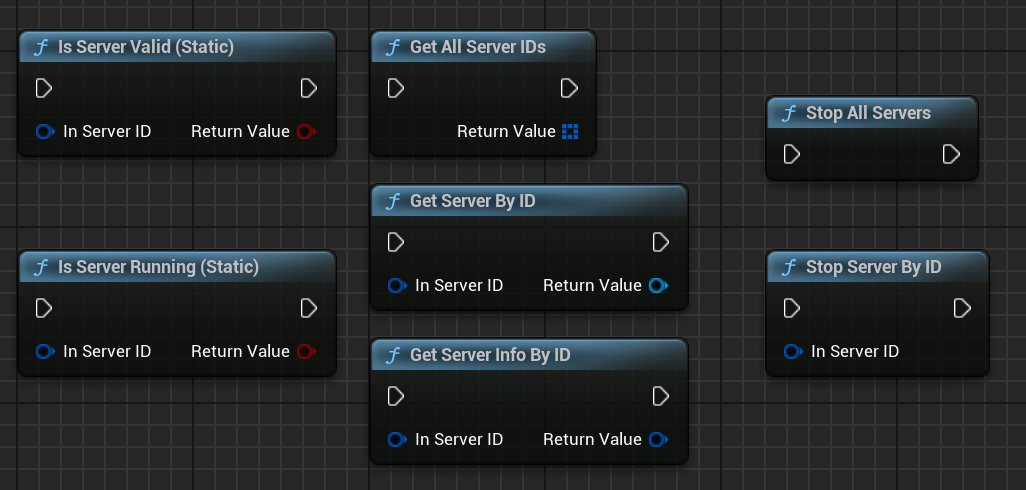
Fonctions de gestion statique
AIChatPlus offre une série de fonctions statiques pour gérer tous les serveurs :
| Fonction | Description |
|---|---|
Is Server Valid (Static) |
Vérifie si le serveur est valide |
Is Server Running (Statique) |
Vérifie si le Serveur est en cours d'exécution |
Arrêter le Serveur Par ID |
Arrête le serveur spécifié par ID |
Stop All Servers |
Arrêter tous les serveurs |
Get Server Info By ID |
Obtenir les informations du serveur par ID |
Obtenir tous les ID des serveurs |
Récupérer tous les ID des serveurs |
Get Server By ID |
Obtenir une instance de Serveur par ID |
Support multilingue
CllamaServer prend en charge les modèles multimodaux (comme Moondream, Qwen2-VL, etc.).
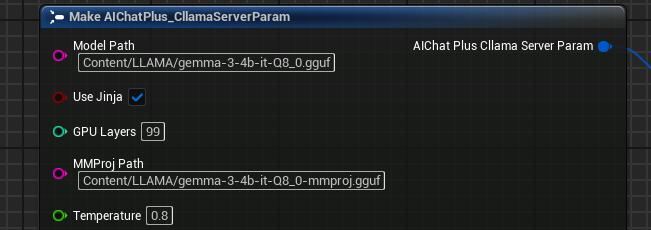
Configurer les paramètres multimodaux
Dans le paramètre Server, définissez MMProj (chemin du fichier de projection multimodale) :
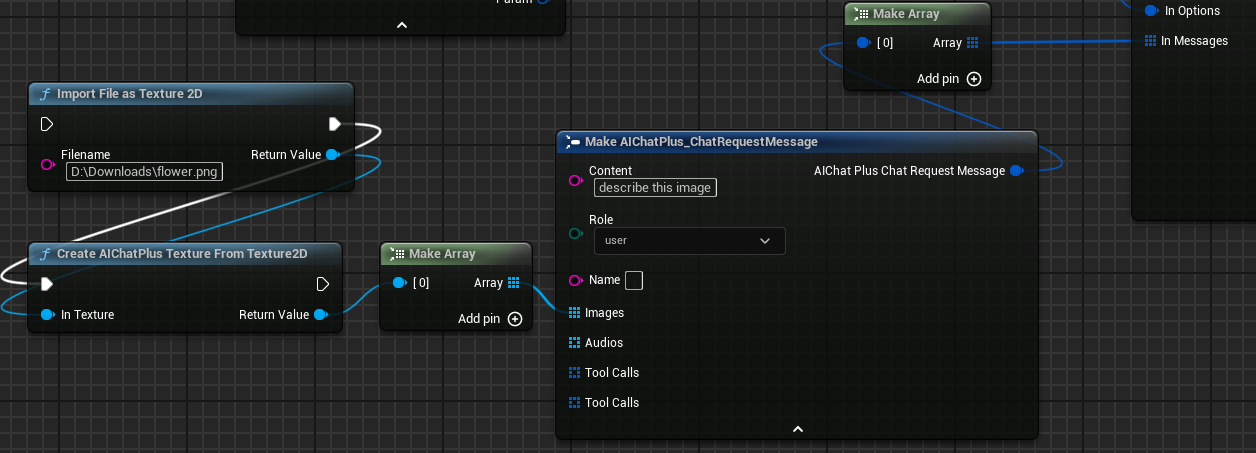
Envoyer un message avec une image
Ajouter des images dans Messages :
Tool Calling
CllamaServer prend en charge la fonction Tool Calling (appel de fonction), dont l'utilisation est similaire à celle d'OpenAI.
Pour une utilisation détaillée, veuillez consulter Tool CallDocument.
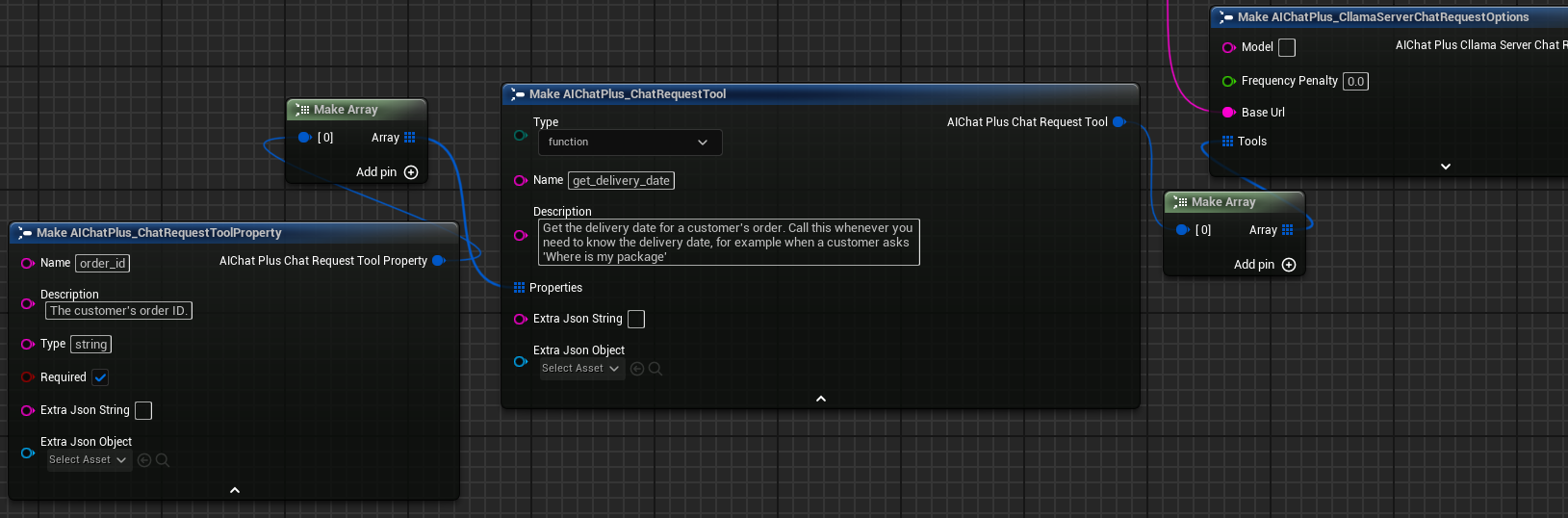
Pour utiliser CllamaServer pour les appels d'outil (Tool Call), il est nécessaire de :
1. Dans les paramètres du Serveur, définissez bUseJinja = true
2. Définir les outils dans le champ Tools des Chat Options
Éditeur Gestion du Serveur
AIChatPlus propose dans ses outils d'édition une interface visuelle de gestion pour CllamaServer, facilitant ainsi la création, la surveillance et la gestion de plusieurs serveurs.
Ouvrez l'outil d'édition : Outils -> AIChatPlus -> AIChat, puis ouvrez l'onglet Cllama Server Manager.
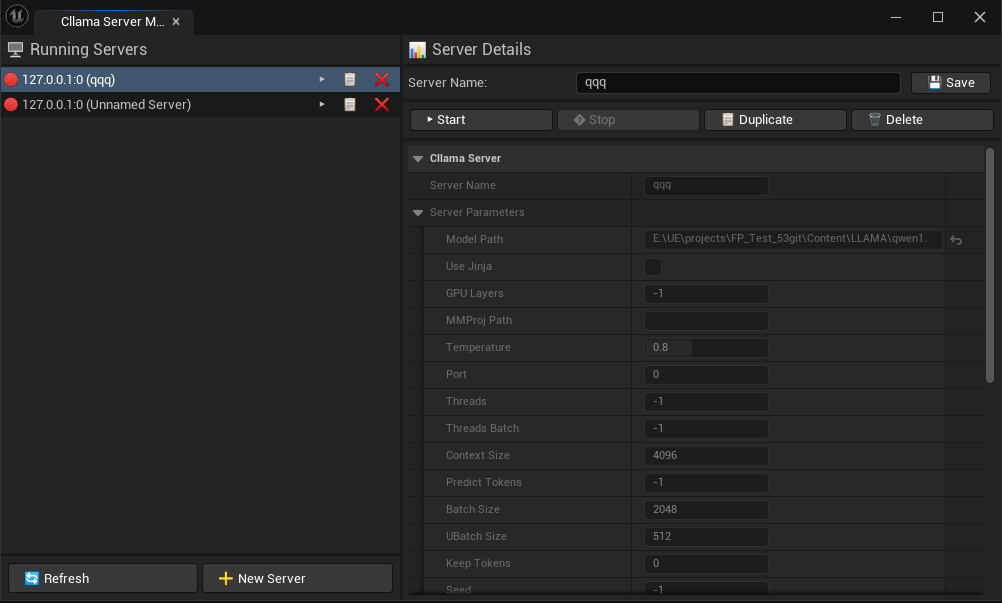
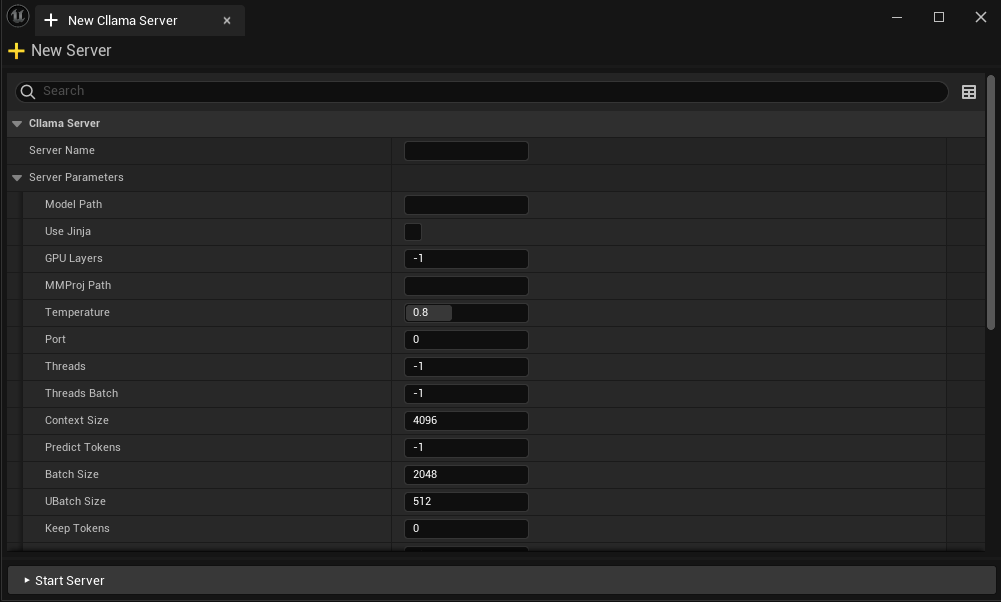
Dans l'éditeur, vous pouvez : * Créer un nouveau serveur * Vérifier l'état du serveur en cours d'exécution * Arrêter le serveur spécifié * Configuration des paramètres du serveur * La configuration du serveur est automatiquement sauvegardée.
Relations avec les autres API
Puisque CllamaServer est compatible avec le format API d'OpenAI, vous pouvez également utiliser le nœud Chat Request d'OpenAI pour communiquer avec CllamaServer. Il suffit de définir le BaseUrl sur l'adresse de CllamaServer.
Original: https://wiki.disenone.site/fr
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
Ce message a été traduit en utilisant ChatGPT, merci de nous faire part de vos retoursSignaler toute omission.