ブループリント編 - Cllama (llama.cpp) (廃止済み)
廃止済み
Cllama は廃止としてマークされ、もはやメンテナンスされません。
Cllamaの既存機能はCllamaServer来るべきものを受け入れるために。
オフラインモデル
Cllamaはllama.cppをベースに実装されており、オフラインでのAI推論モデルの使用をサポートしています。
オフラインであるため、あらかじめモデルファイルを準備する必要があります。例えば、HuggingFaceのウェブサイトからオフラインモデルをダウンロードします:Qwen1.5-1.8B-Chat-Q8_0.gguf
モデルを特定のフォルダに配置します。例えば、ゲームプロジェクトのディレクトリ Content/LLAMA の下に置いてください。
オフラインモデルファイルを手に入れたら、Cllamaを使ってAIとチャットできるようになります。
テキストチャット
Cllamaを使用してテキストチャットを行う
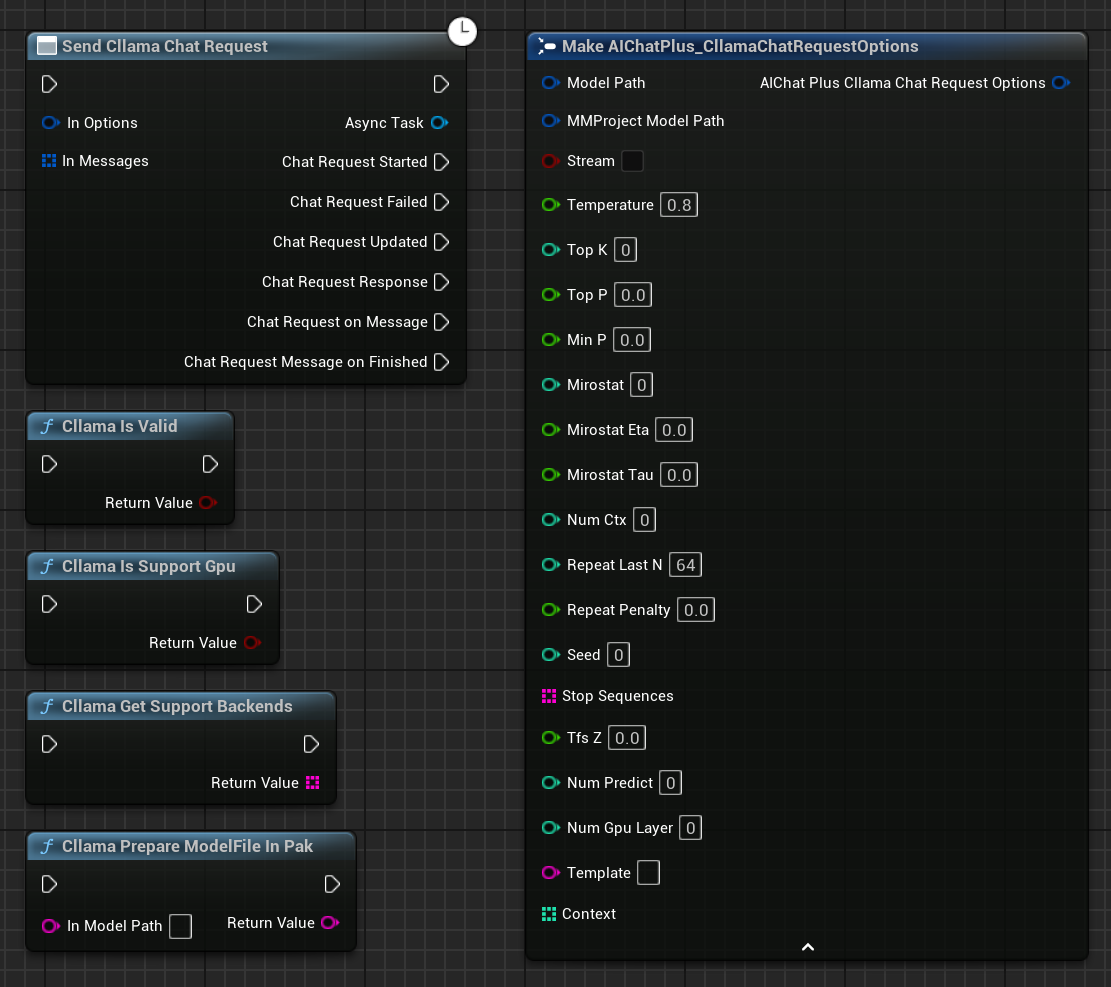
ブループリントで右クリックしてノード「Send Cllama Chat Request」を作成する
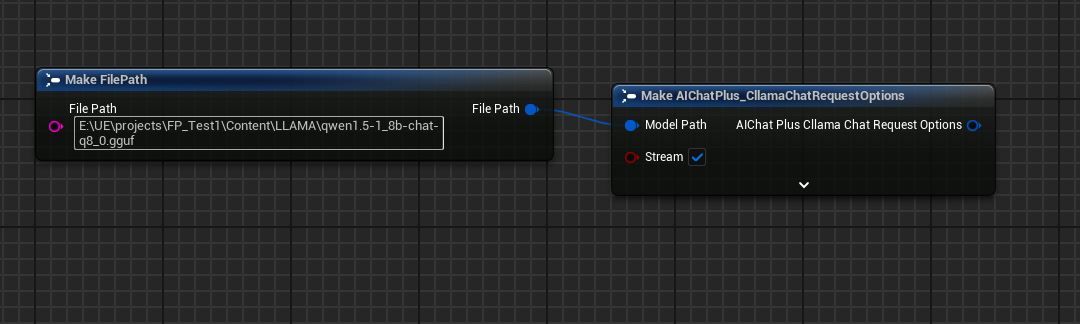
Optionsノードを作成し、以下の設定を行います: Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
Messagesを作成し、それぞれSystem MessageとUser Messageを1つずつ追加する
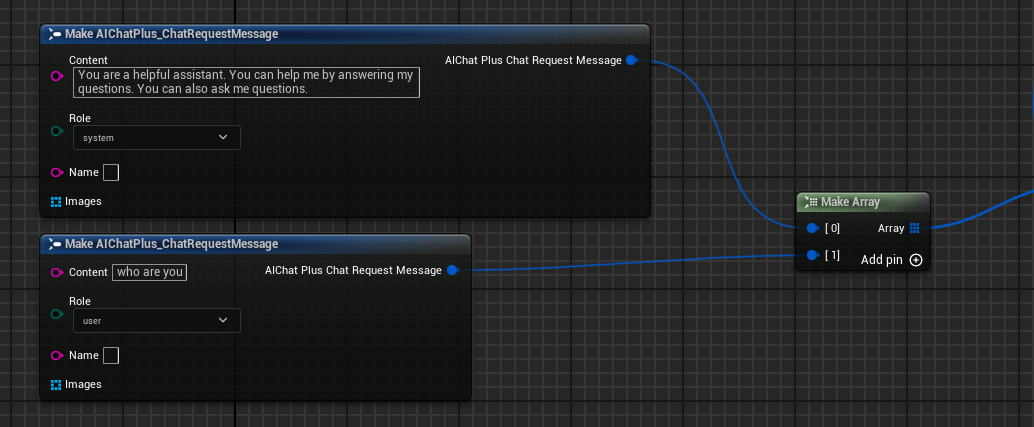
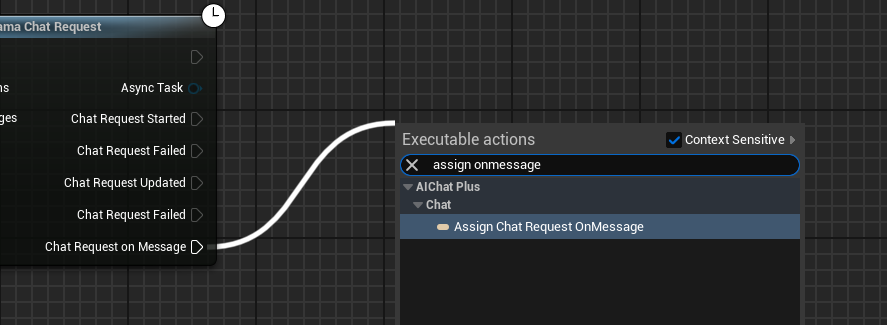
Delegate を作成し、モデルの出力情報を受け取り、画面に表示します
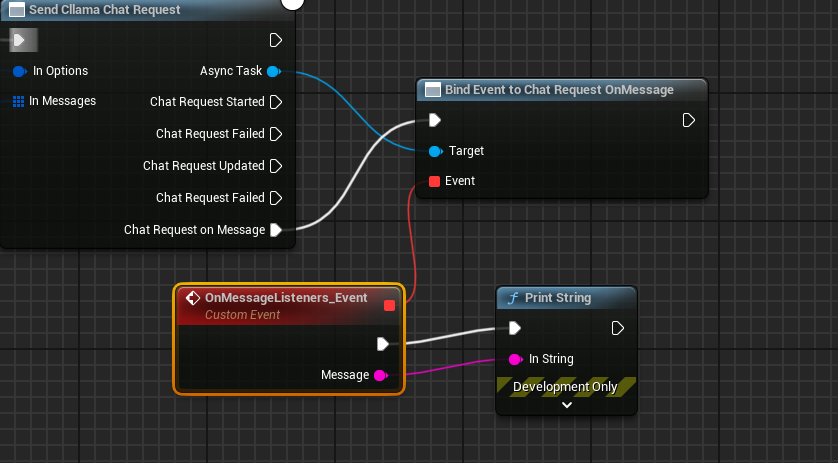
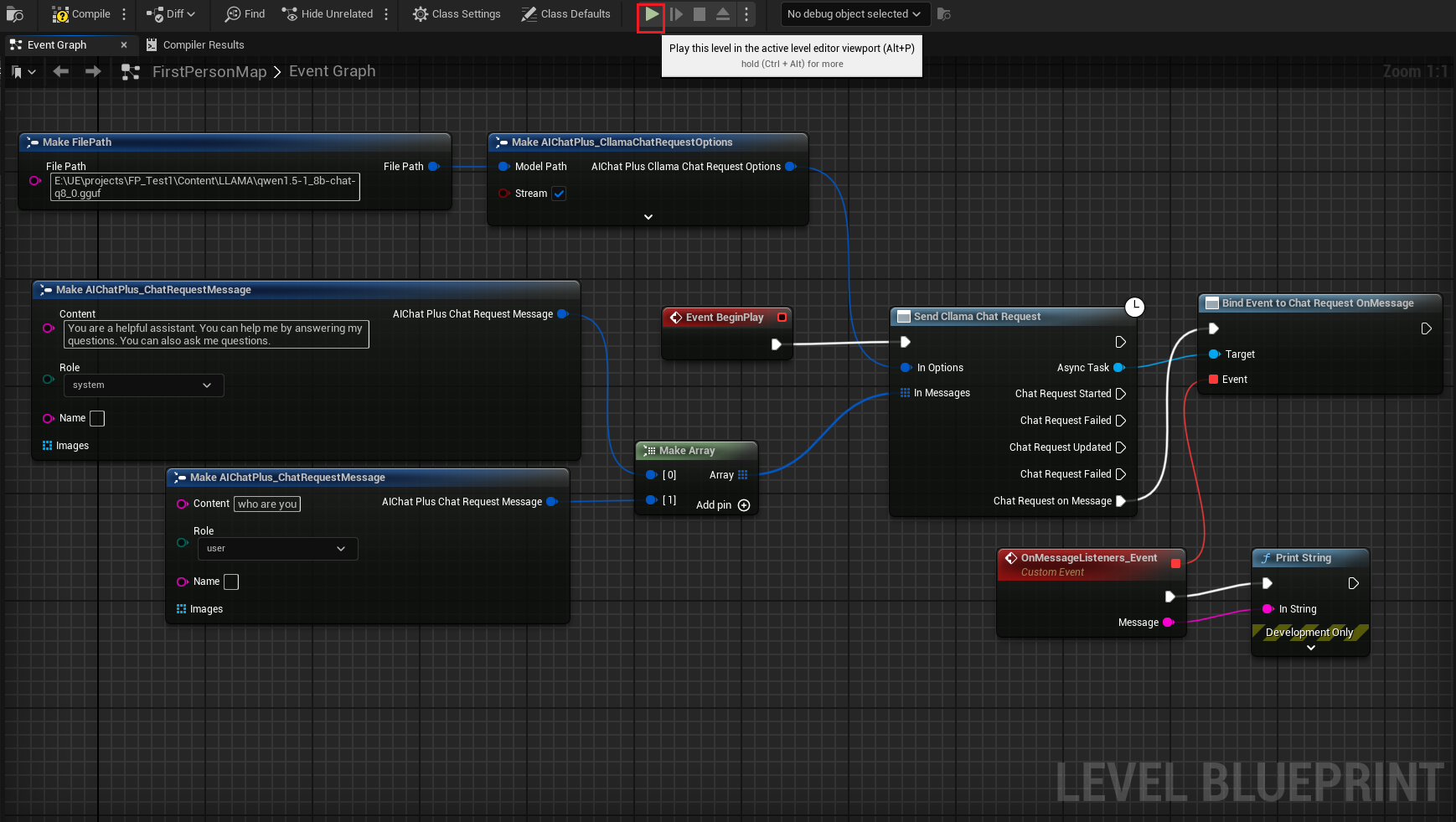
完成された設計図は次のようになります。設計図を実行すると、ゲーム画面で大規模モデルから返されたメッセージが表示されるのが確認できます。
画像からテキストを生成 llava
Cllamaは実験的にllavaライブラリをサポートしており、Vision機能を提供しています。
まずはMultimodalオフラインモデルファイルを準備します。例えばMoondream(moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf)または Qwen2-VL(Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf)またはその他の llama.cpp がサポートするマルチモーダルモデル。
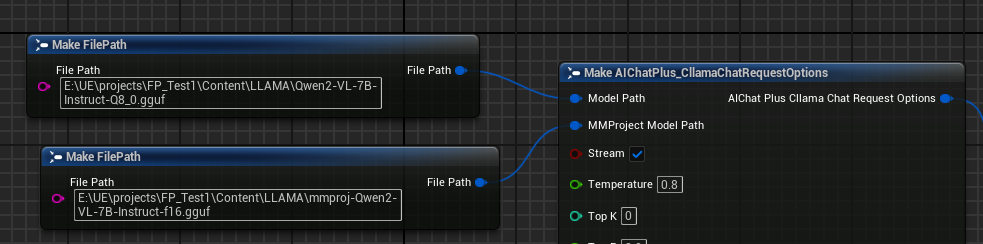
Optionsノードを作成し、"Model Path"と"MMProject Model Path"のパラメータをそれぞれ対応するマルチモーダルモデルファイルに設定します。
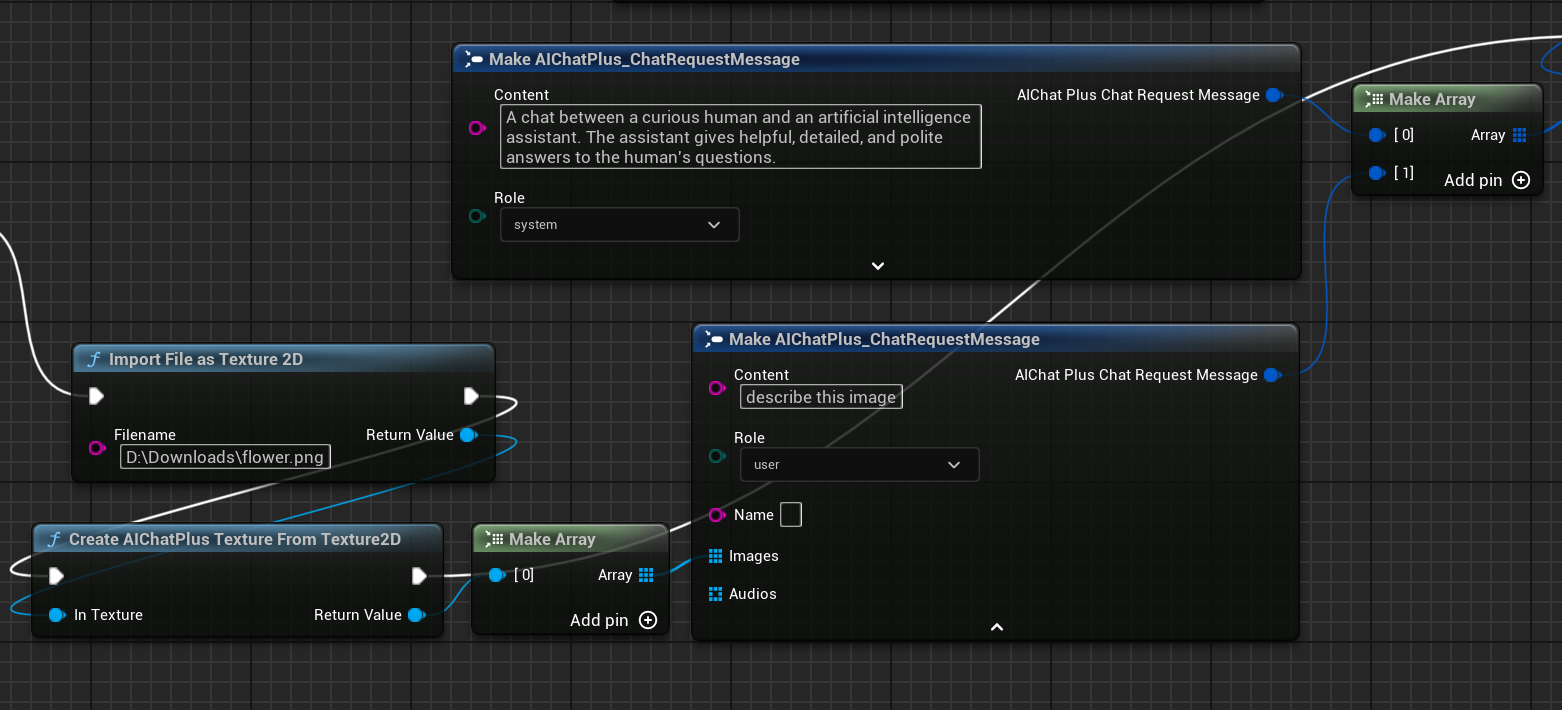
ノードを作成して画像ファイル flower.png を読み取り、Messages を設定します

最後に作成されたノードは返された情報を受け取り、画面に表示します。完全なブループリントはこのようになります
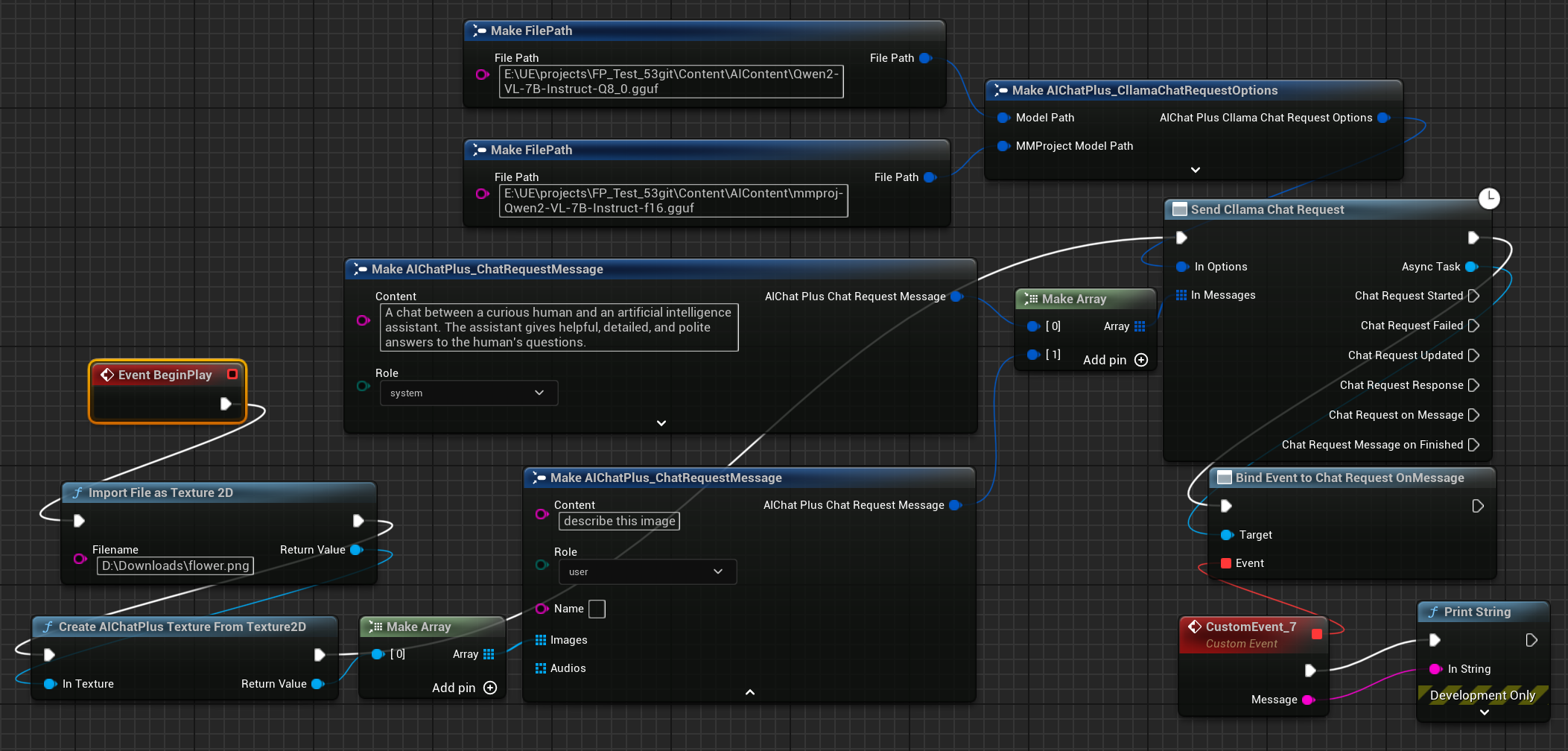
実行中のブループリントにより返されるテキストが表示されます

llama.cppでのGPU活用
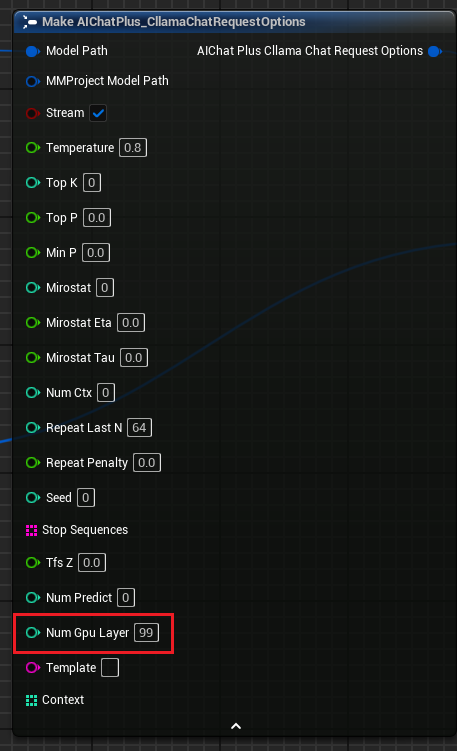
「Cllama Chat Request Options」にパラメータ「Num Gpu Layer」を追加しました。これにより、llama.cppのGPUペイロードを設定でき、GPU上で計算する必要のある層数を制御できます。図の通りです。
KeepAlive
「Cllama Chat Request Options」にパラメータ「KeepAlive」を追加すると、読み込んだモデルファイルをメモリに保持し、次回の使用時にすぐに再利用できるようになります。これにより、モデルの読み込み回数を減らすことができます。KeepAliveはモデルを保持する時間を表し、0は保持せず使用後すぐに解放することを意味し、-1は永続的に保持することを意味します。各リクエストで設定するOptionsごとに異なるKeepAliveを設定でき、新しいKeepAlive値は古い値を上書きします。たとえば、最初の数回のリクエストでKeepAlive=-1と設定してモデルをメモリに保持し、最後のリクエストでKeepAlive=0と設定することでモデルファイルを解放することができます。
.Pak 内のモデルファイルを処理する
Pak パッケージングを有効にすると、プロジェクトのすべてのリソースファイルが .Pak ファイル内に格納されます。これには、オフラインモデルの gguf ファイルも当然含まれます。
llama.cpp は直接 .Pak ファイルを読み込むことができないため、.Pak ファイル内のオフラインモデルファイルをファイルシステムにコピーする必要があります。
AIChatPlusは、自動的に.Pakファイル内のモデルファイルをコピーして処理し、Savedフォルダに配置する機能を提供しています:
あるいは、.pakファイル中のモデルファイルを自分で処理することもできます。重要なのは、ファイルをコピーして取り出すことです。なぜなら、llama.cppは.pakを正しく読み込むことができないからです。
機能ノード
Cllamaは、現在の環境状態を簡単に取得するためのいくつかの機能ノードを提供しています。
「CllamaはValidです」:Cllama llama.cppが正常に初期化されているかどうかを判断します

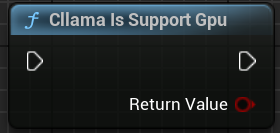
「Cllama Is Support Gpu」:llama.cppが現在の環境でGPUバックエンドをサポートしているかどうかを確認する
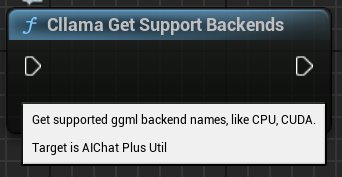
「Cllama Get Support Backends」: 現在の llama.cpp でサポートされている全てのバックエンドを取得する
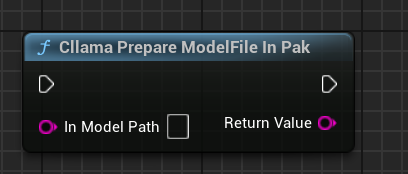
「Cllama Prepare ModelFile In Pak」: Pak内のモデルファイルを自動的にファイルシステムにコピーする

Original: https://wiki.disenone.site/ja
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
この投稿はChatGPTを使用して翻訳されています。不備がありましたら、フィードバックいずれかの見落としを指摘してください。