블루프린트 편 - Cllama (llama.cpp)(폐기됨)
폐기됨
Cllama는 폐기로 표시되어 더 이상 유지되지 않습니다.
Cllama의 기존 기능은 CllamaServer담아줄게.
오프라인 모델
Cllama는 llama.cpp를 기반으로 구현되었으며, AI 추론 모델을 오프라인에서 사용할 수 있도록 지원합니다.
오프라인 상태이므로 모델 파일을 미리 준비해야 합니다. 예를 들어, HuggingFace 웹사이트에서 오프라인 모델을 다운로드할 수 있습니다: Qwen1.5-1.8B-Chat-Q8_0.gguf
모델을 특정 폴더 아래에 배치합니다. 예를 들어, 게임 프로젝트의 디렉토리인 Content/LLAMA에 둡니다.
오프라인 모델 파일을 확보한 후에는 Cllama를 통해 AI 채팅을 할 수 있습니다
텍스트 채팅
Cllama를 사용하여 텍스트 채팅하기
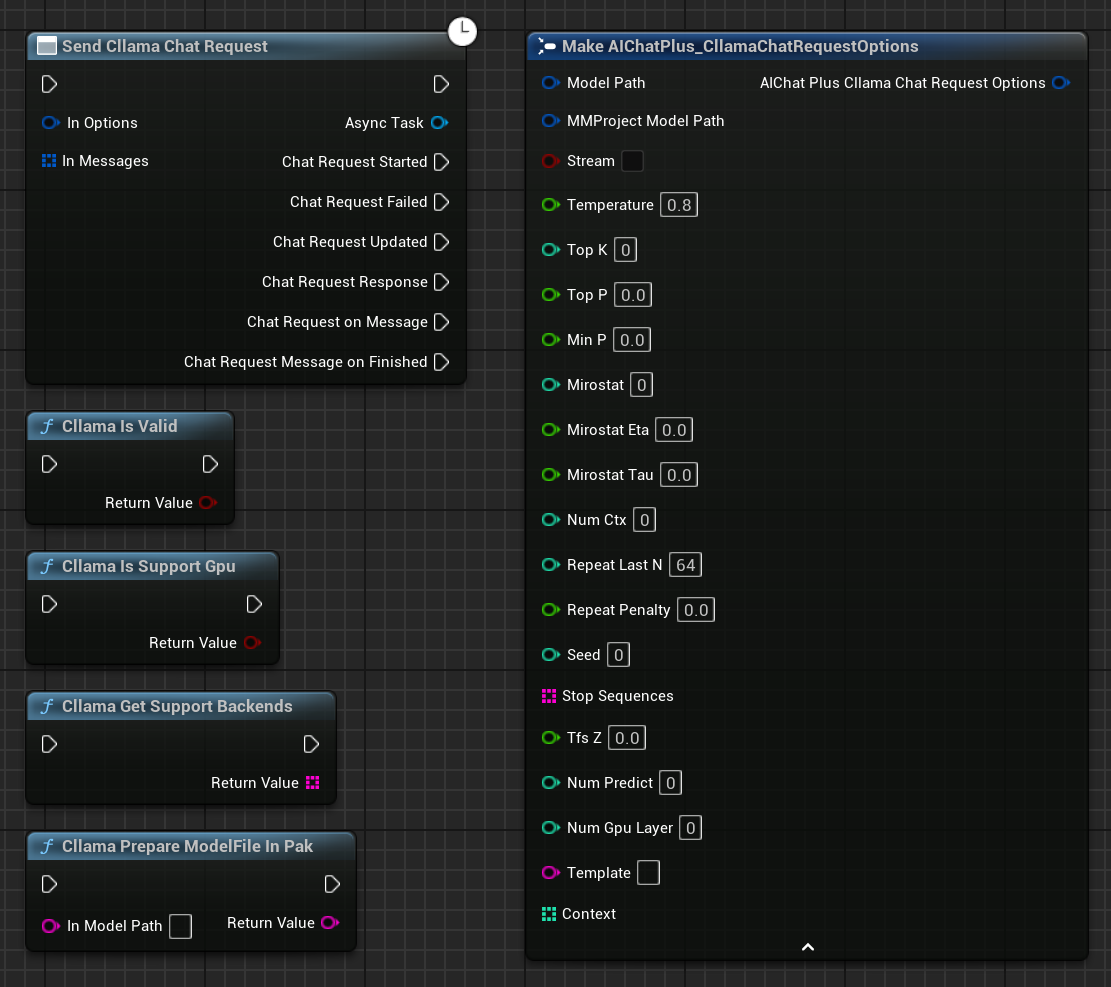
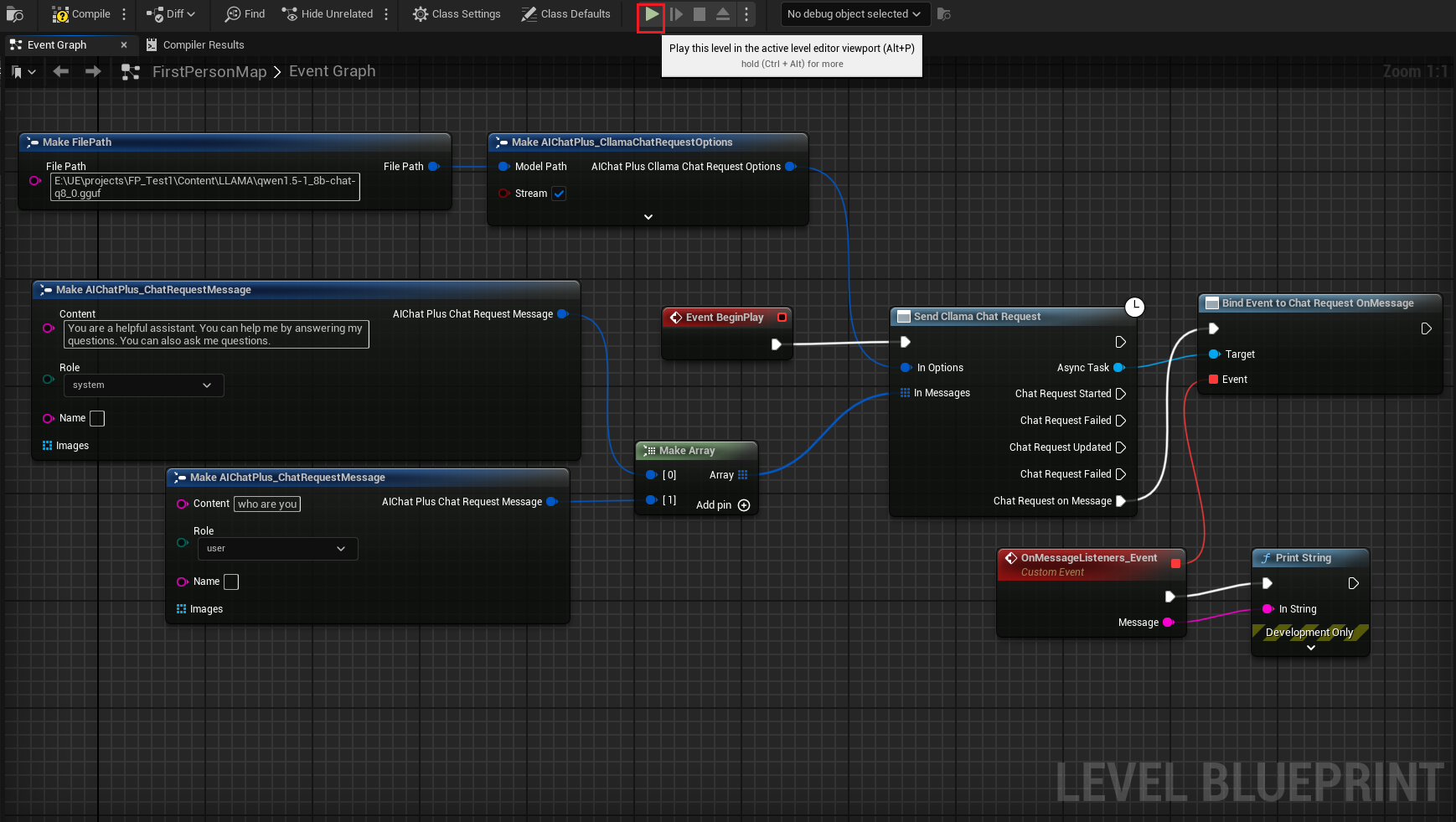
블루프린트에서 우클릭하여 노드 생성하기 Send Cllama Chat Request
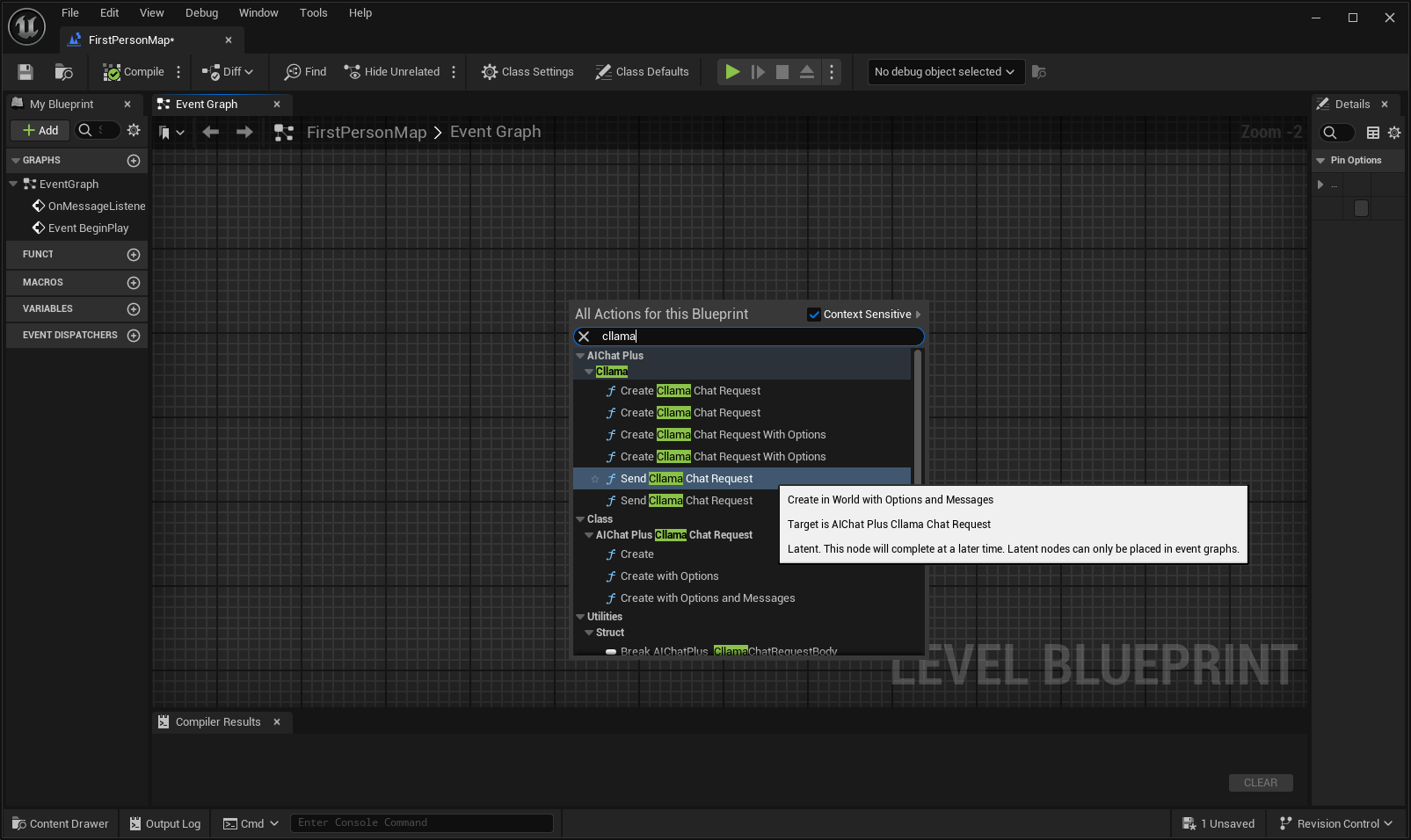
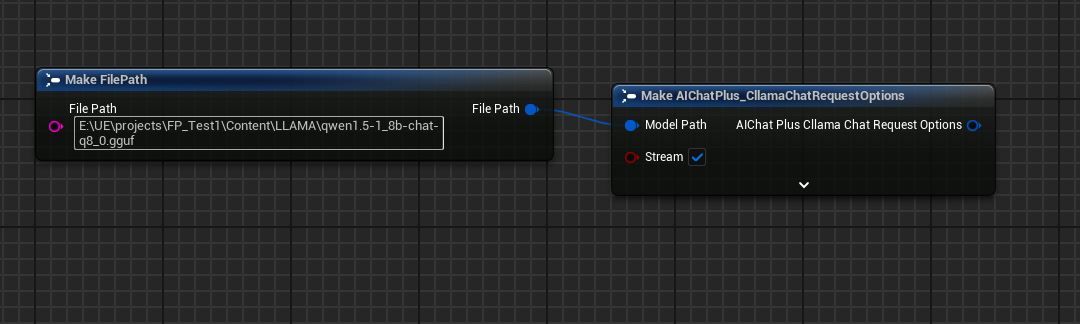
Options 노드를 생성하고 Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"로 설정합니다.
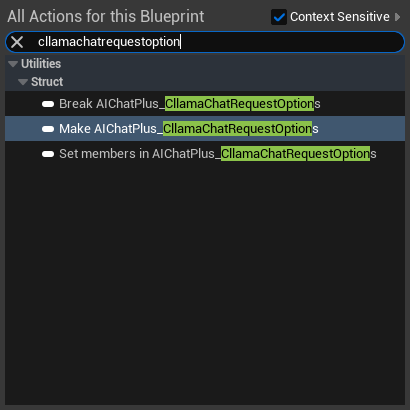
메시지를 생성하고, 각각 하나의 시스템 메시지와 사용자 메시지를 추가합니다.
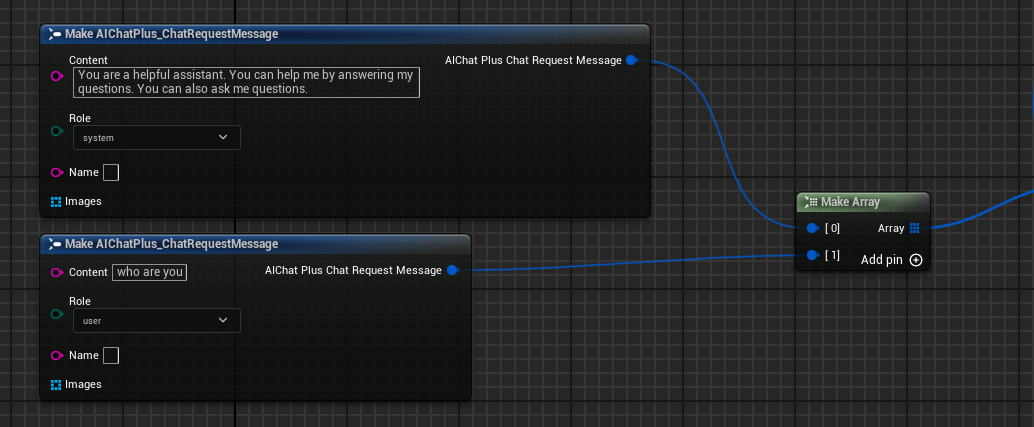
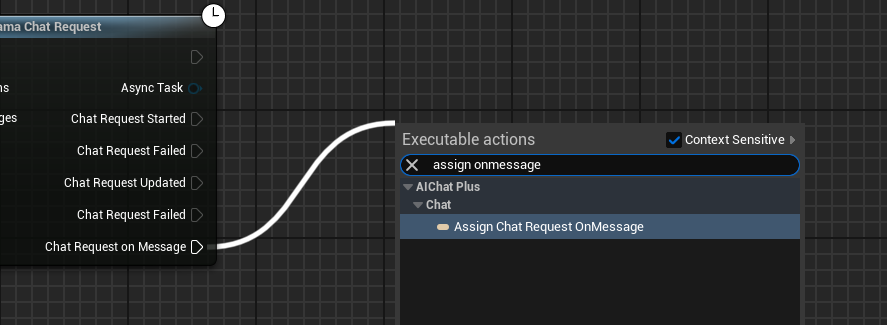
델리게이트를 생성하여 모델 출력 정보를 수신하고 화면에 출력하기
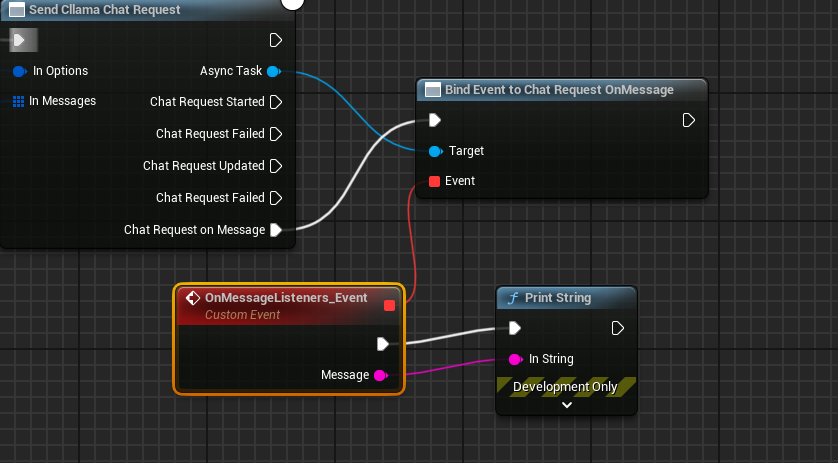
완성된 블루프린트는 다음과 같으며, 블루프린트를 실행하면 게임 화면에서 대형 모델이 반환한 메시지가 출력되는 것을 볼 수 있습니다.
이미지 생성 텍스트 llava
Cllama는 또한 llava 라이브러리를 실험적으로 지원하여 Vision 기능을 제공합니다.
먼저 멀티모달 오프라인 모델 파일을 준비합니다. 예를 들면 Moondream(moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf)또는 Qwen2-VL(Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf)혹은 다른 llama.cpp에서 지원하는 멀티모달 모델.
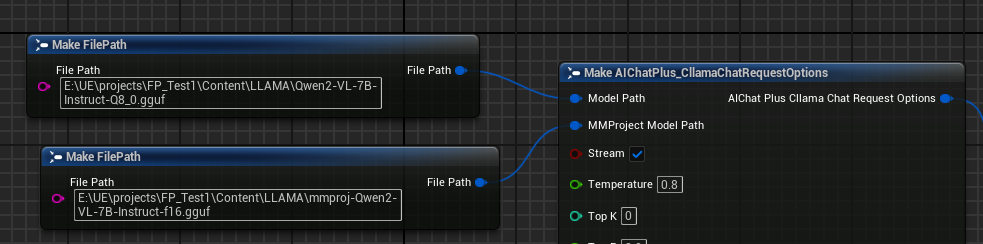
Options 노드를 생성하고, 각각 "Model Path"와 "MMProject Model Path" 파라미터를 해당 Multimodal 모델 파일로 설정하세요.
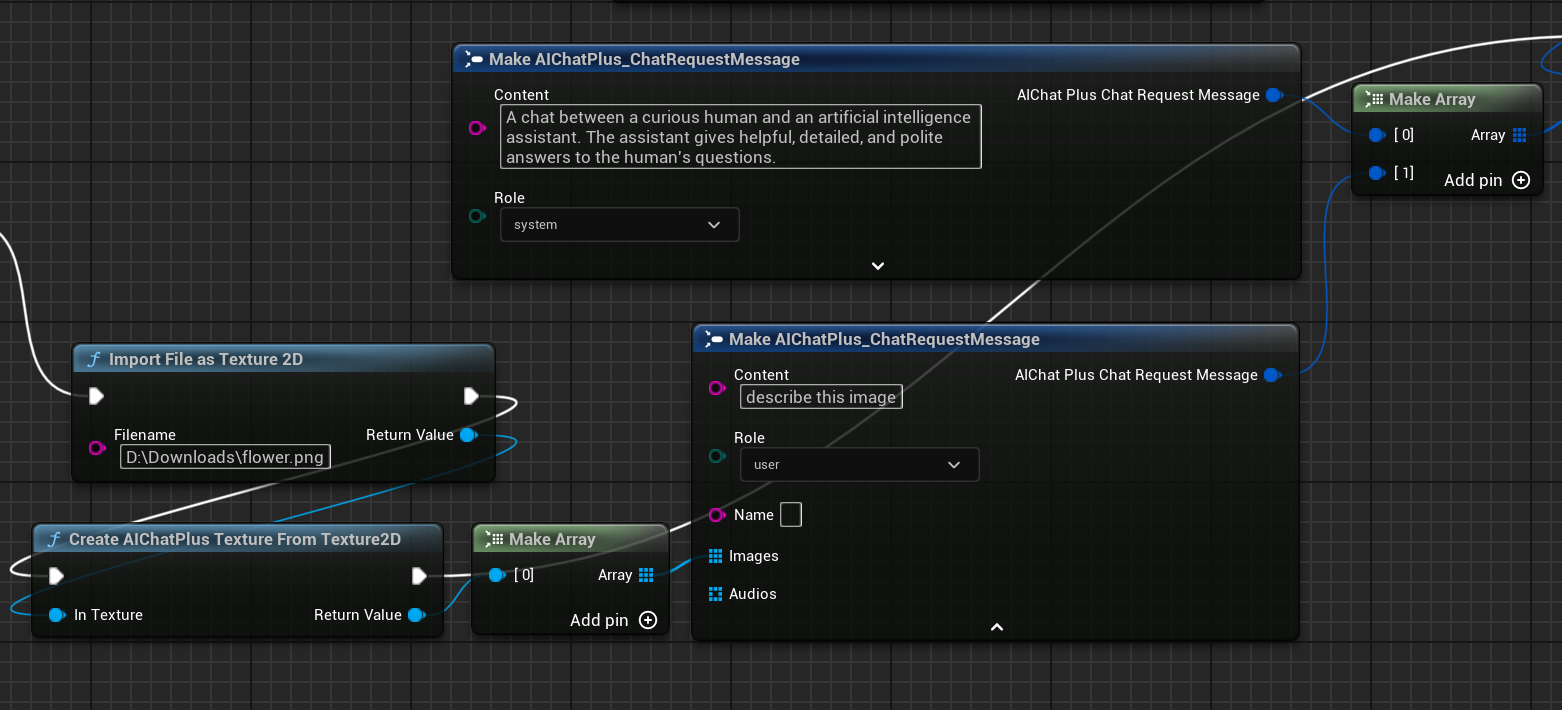
노드를 생성하여 이미지 파일 flower.png를 읽고 Messages를 설정합니다.

마지막으로 생성된 노드는 반환된 정보를 수락하고 화면에 출력되며, 완성된 청사진은 다음과 같아 보입니다.
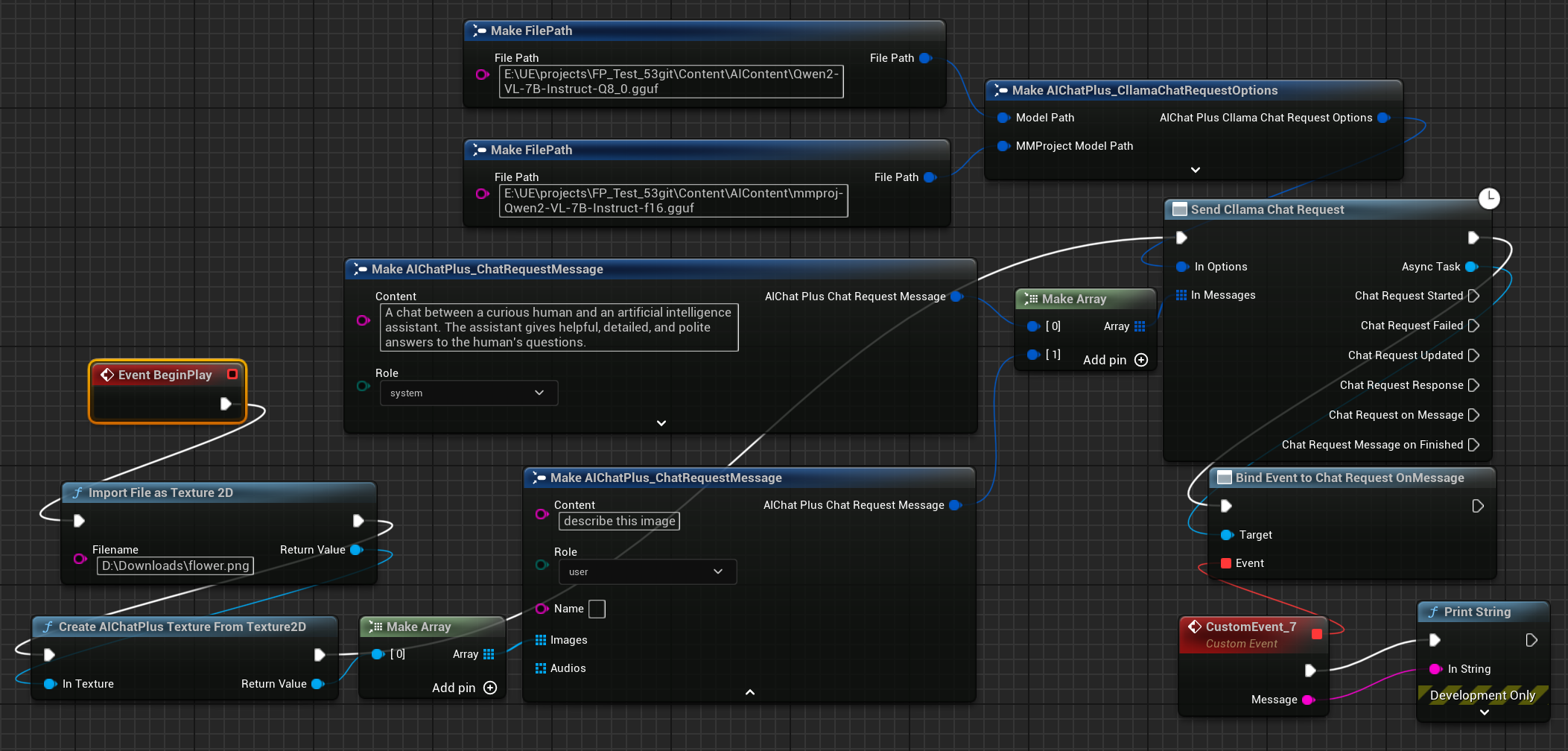
실행 청사진을 통해 반환된 텍스트를 확인할 수 있습니다

llama.cpp GPU 사용하기
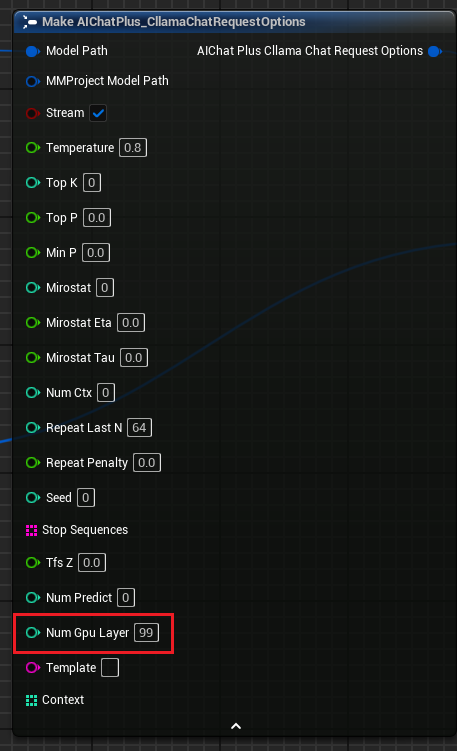
"Cllama Chat Request Options"에 매개변수 "Num Gpu Layer"를 추가했습니다. 이는 llama.cpp의 GPU 페이로드를 설정하여 GPU에서 계산되어야 할 레이어 수를 제어할 수 있습니다. 그림과 같습니다.
KeepAlive
"Cllama 채팅 요청 옵션"에 "KeepAlive" 매개변수를 추가하면, 읽어들인 모델 파일이 메모리에 유지되어 다음에 바로 사용할 수 있게 되어 모델을 반복적으로 읽어들이는 횟수를 줄일 수 있습니다. KeepAlive는 모델이 유지되는 시간을 의미하며, 0은 유지하지 않고 사용 후 바로 해제함을 나타내고, -1은 영구적으로 유지함을 나타냅니다. 각 요청에서 설정하는 Options마다 다른 KeepAlive 값을 설정할 수 있으며, 새로운 KeepAlive 값은 이전 값을 대체합니다. 예를 들어, 초기 몇 차례의 요청에서는 KeepAlive=-1로 설정하여 모델이 메모리에 계속 유지되도록 하고, 마지막 요청에서는 KeepAlive=0으로 설정하여 모델 파일을 해제할 수 있습니다.
.Pak으로 패키징된 모델 파일 처리하기
Pak 패키징을 활성화하면 프로젝트의 모든 리소스 파일이 .Pak 파일 안에 포함되며, 여기에는 오프라인 모델 gguf 파일도 포함됩니다.
llama.cpp가 .Pak 파일을 직접 읽는 것을 지원하지 않기 때문에, .Pak 파일 안의 오프라인 모델 파일을 파일 시스템으로 복사해 내야 합니다.
AIChatPlus는 .Pak 파일 내의 모델 파일을 자동으로 복사 처리하여 Saved 폴더에 배치하는 기능 함수를 제공합니다:
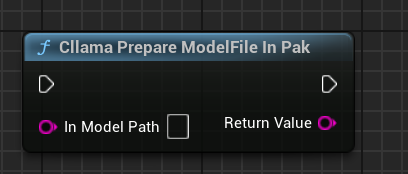
또는 당신이 직접 .Pak 파일 내의 모델을 처리할 수도 있습니다. 핵심은 파일을 복사해내는 것인데, 왜냐하면 llama.cpp가 .Pak 파일을 올바르게 읽어낼 수 없기 때문입니다.
기능 노드
Cllama는 현재 환경의 상태를 쉽게 확인할 수 있는 몇 가지 기능 노드를 제공합니다.
"클라마 유효함": Cllama llama.cpp가 정상적으로 초기화되었는지 확인

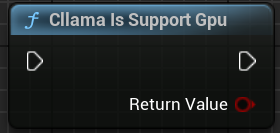
"Cllama Is Support Gpu": 현재 환경에서 llama.cpp가 GPU 백엔드를 지원하는지 확인합니다
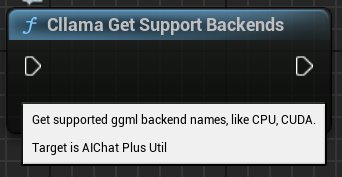
"Cllama Get Support Backends": 현재 llama.cpp가 지원하는 모든 백엔드 목록 가져오기
"클라마 모델 파일 준비(PAK 내)": PAK에 있는 모델 파일을 자동으로 파일 시스템에 복사합니다

Original: https://wiki.disenone.site/ko
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
이 게시물은 ChatGPT를 사용하여 번역되었습니다. 피드백누락된 부분을 지적합니다.