蓝图篇 - Cllama (llama.cpp)(已废弃)
已废弃
Cllama 已经标记为废弃,不再维护。
Cllama 原有功能由 CllamaServer 来承载。
离线模型
Cllama 是基于 llama.cpp 来实现的,支持离线使用 AI 推理模型。
由于是离线,因为我们需要先准备好模型文件,譬如从 HuggingFace 网站下载离线模型:Qwen1.5-1.8B-Chat-Q8_0.gguf
把模型放在某个文件夹下面,譬如放在游戏项目的目录 Content/LLAMA 下
有了离线模型文件之后,我们就可以通过 Cllama 来进行 AI 聊天
文本聊天
使用 Cllama 进行文本聊天
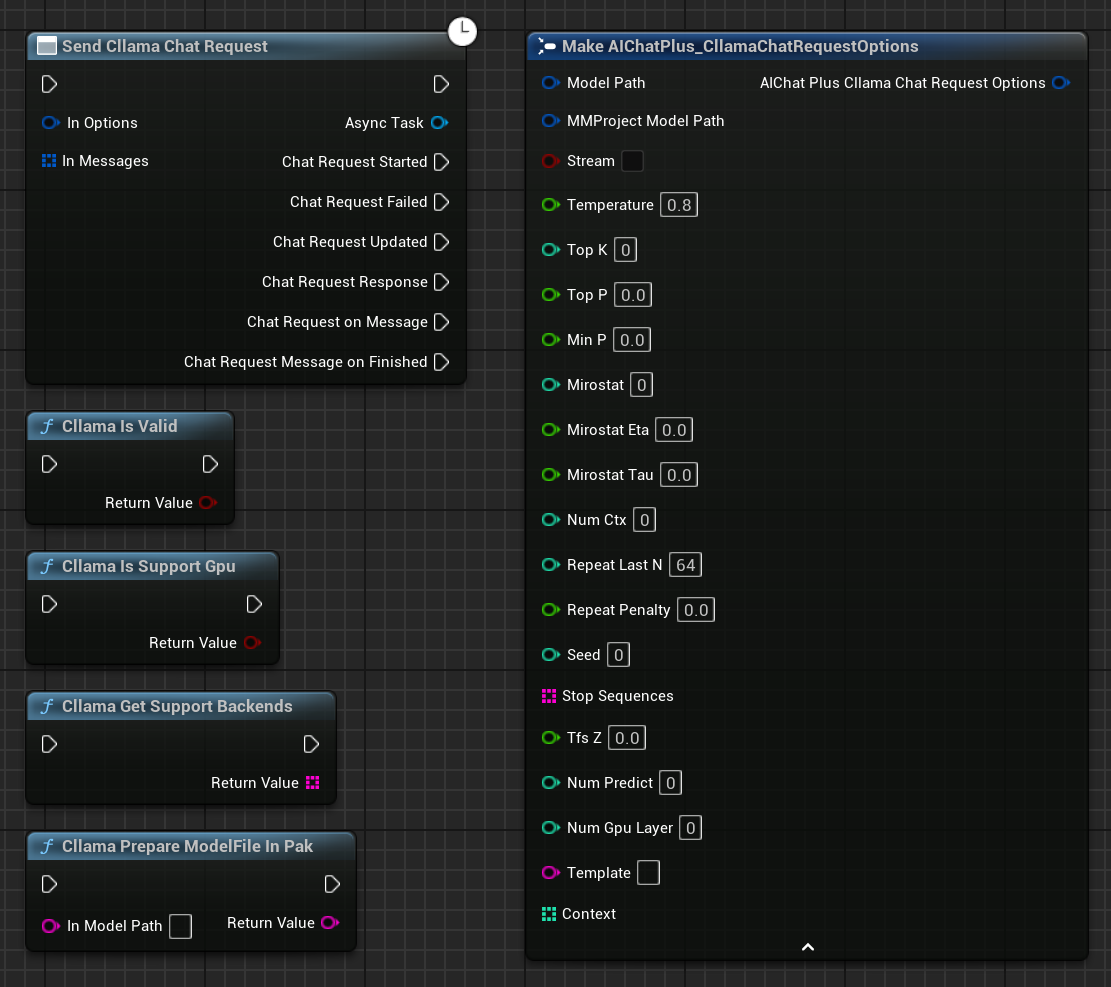
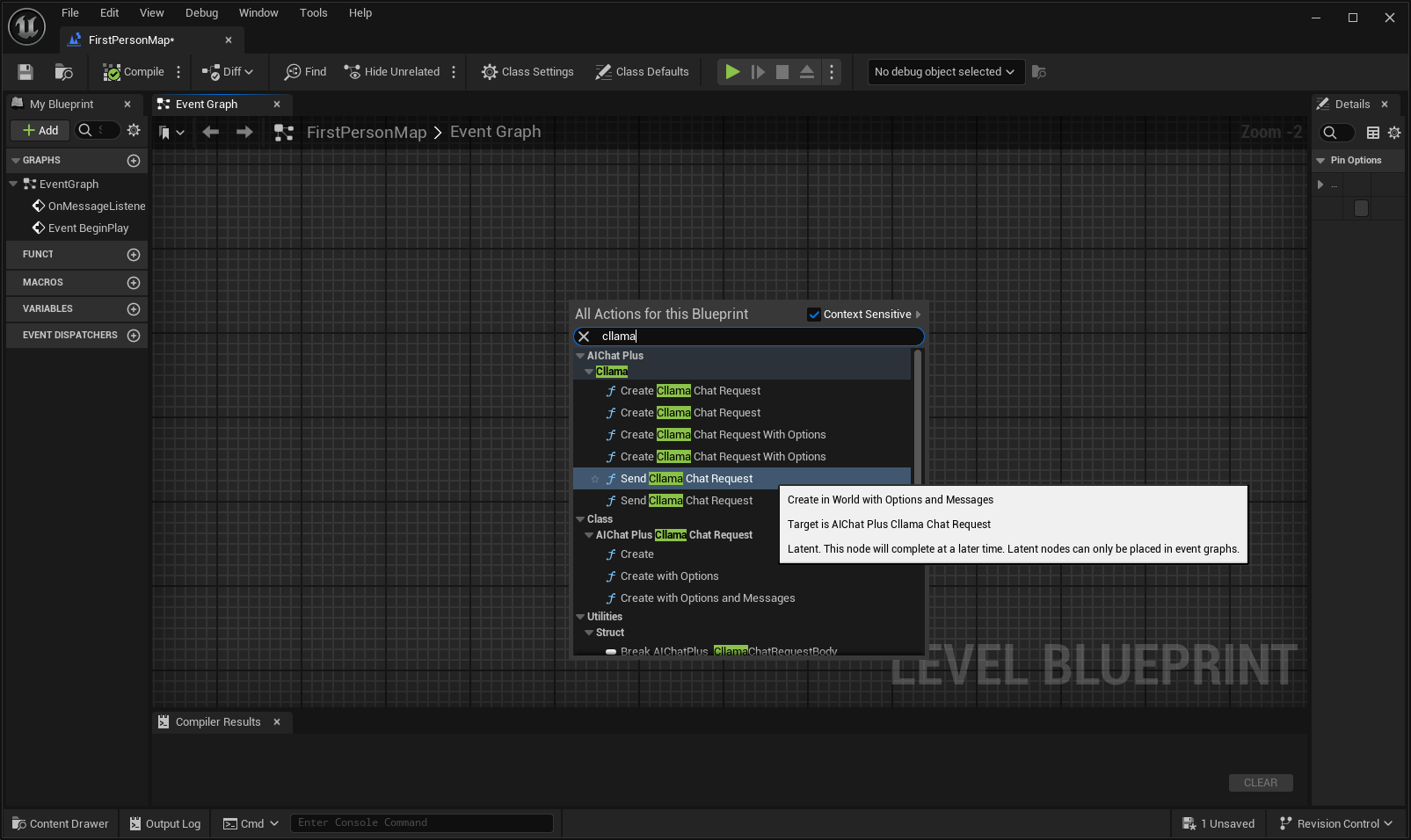
在蓝图中右键创建一个节点 Send Cllama Chat Request
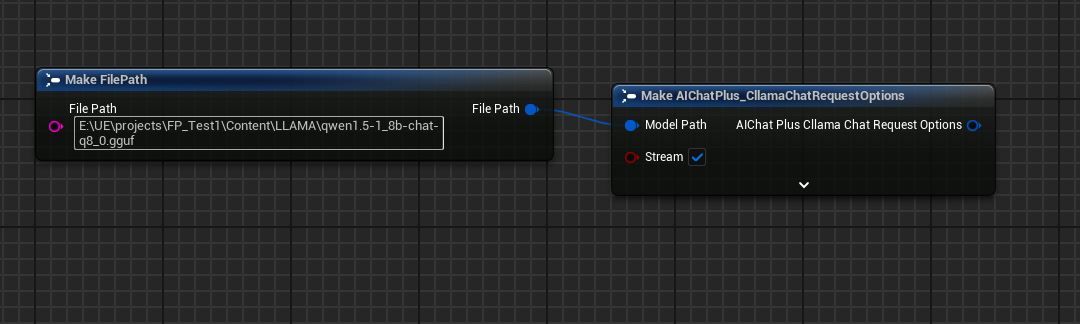
创建 Options 节点,并设置 Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
创建 Messages,分别添加一条 System Message 和 User Message
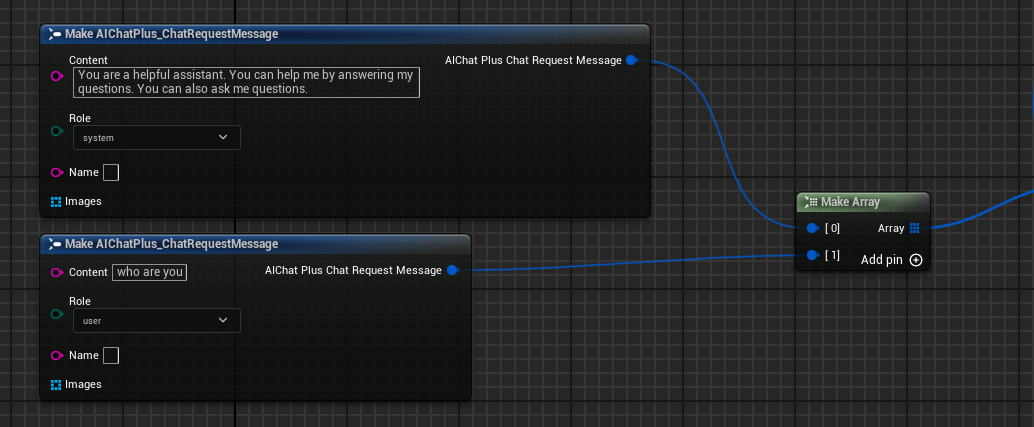
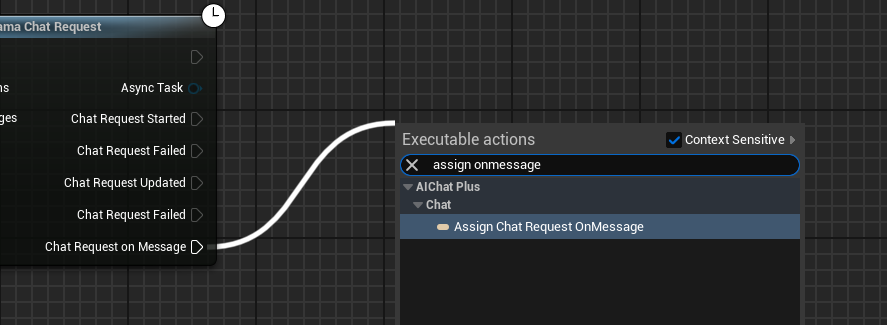
创建 Delegate 接受模型输出的信息,并打印在屏幕上
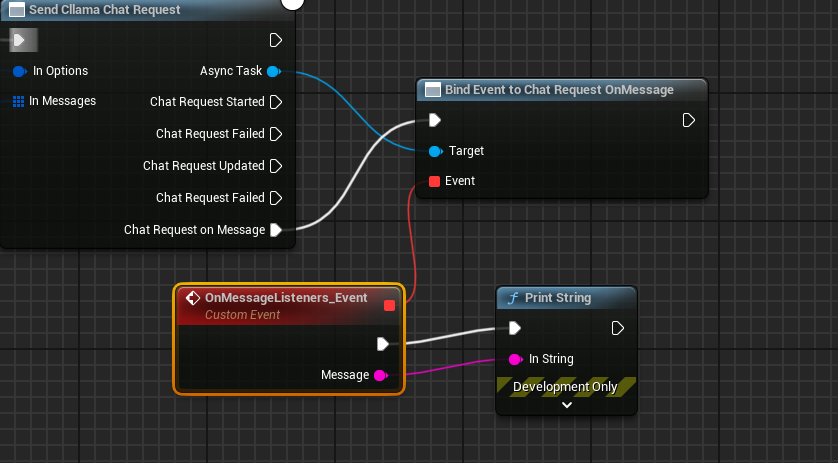
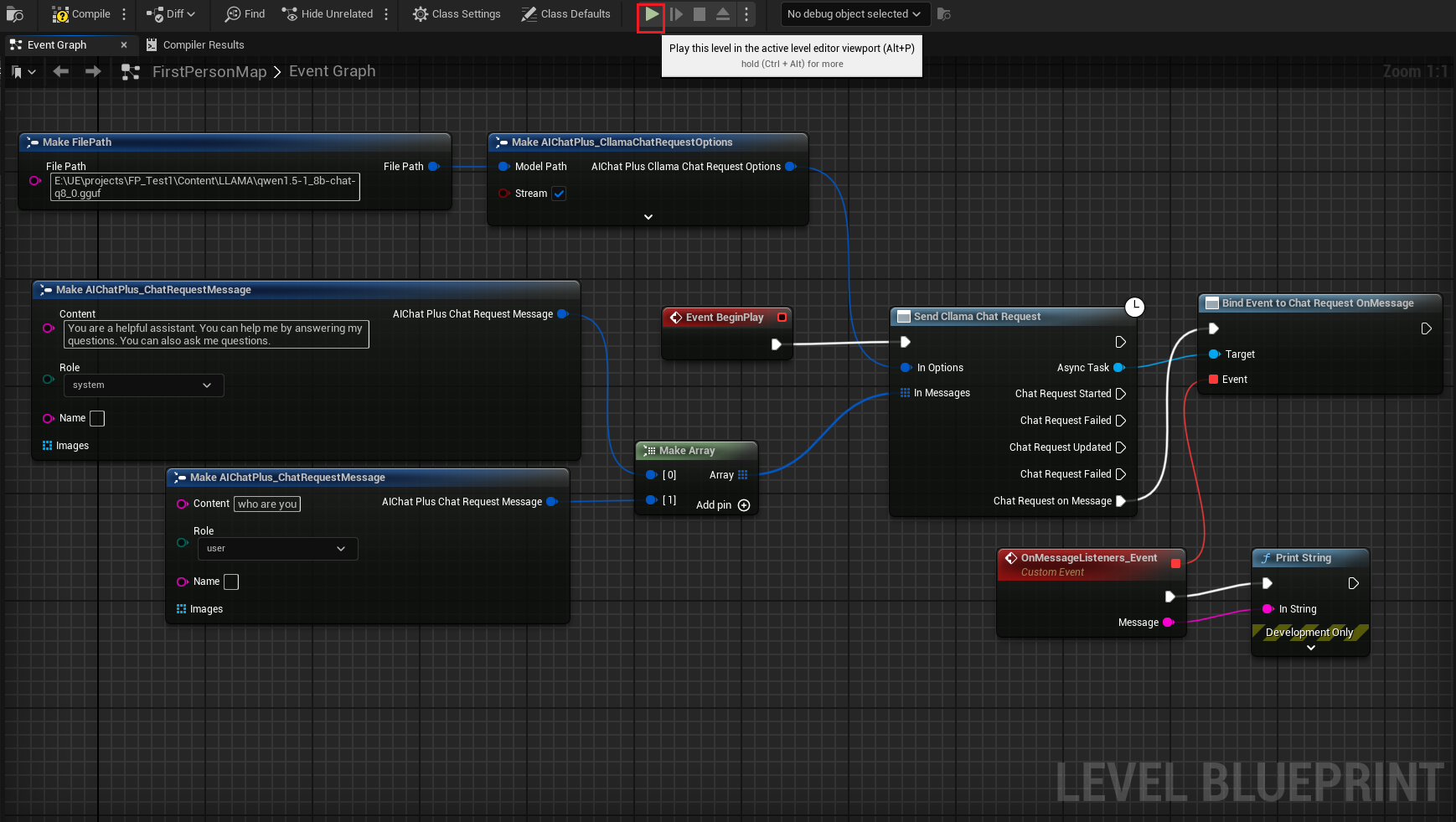
完整的蓝图看起来是这样的,运行蓝图,即可看到游戏屏幕在打印大模型返回的消息
图片生成文字 llava
Cllama 还实验性支持了 llava 库,提供了 Vision 的能力
首先准备好 Multimodal 离线模型文件,例如 Moondream (moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf)或者 Qwen2-VL(Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf)或者其他 llama.cpp 支持的 Multimodal 模型。
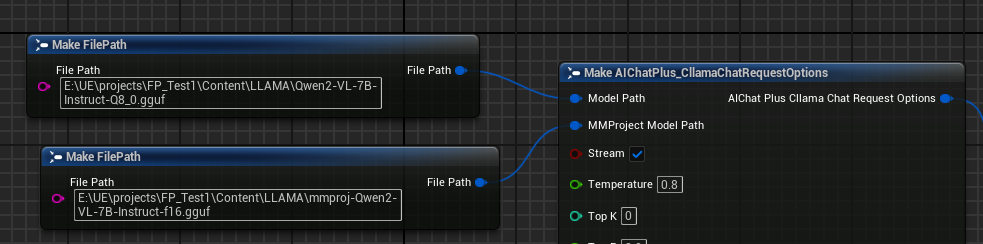
创建 Options 节点,分别设置参数 "Model Path" 和 "MMProject Model Path" 为对应的 Multimodal 模型文件。
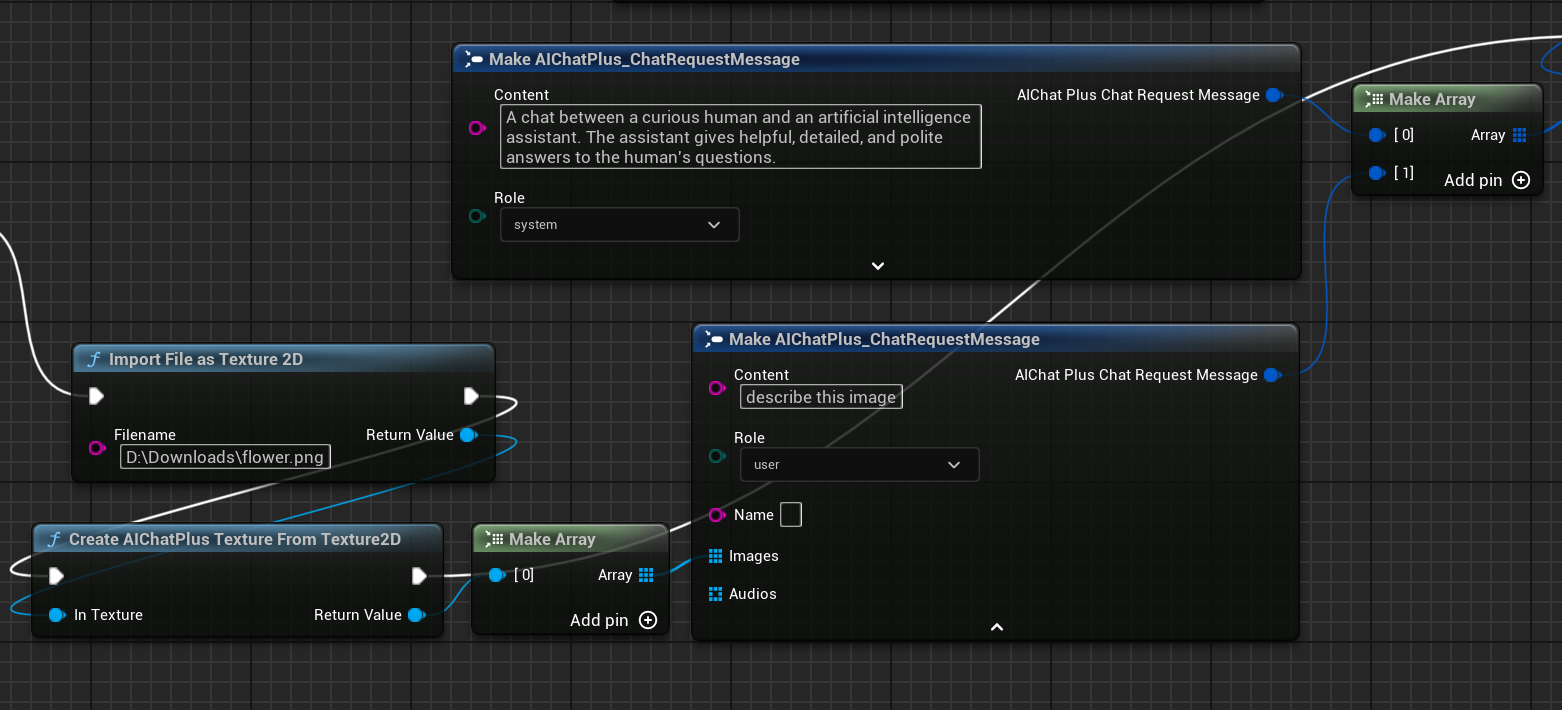
创建节点读取图片文件 flower.png,并设置 Messages

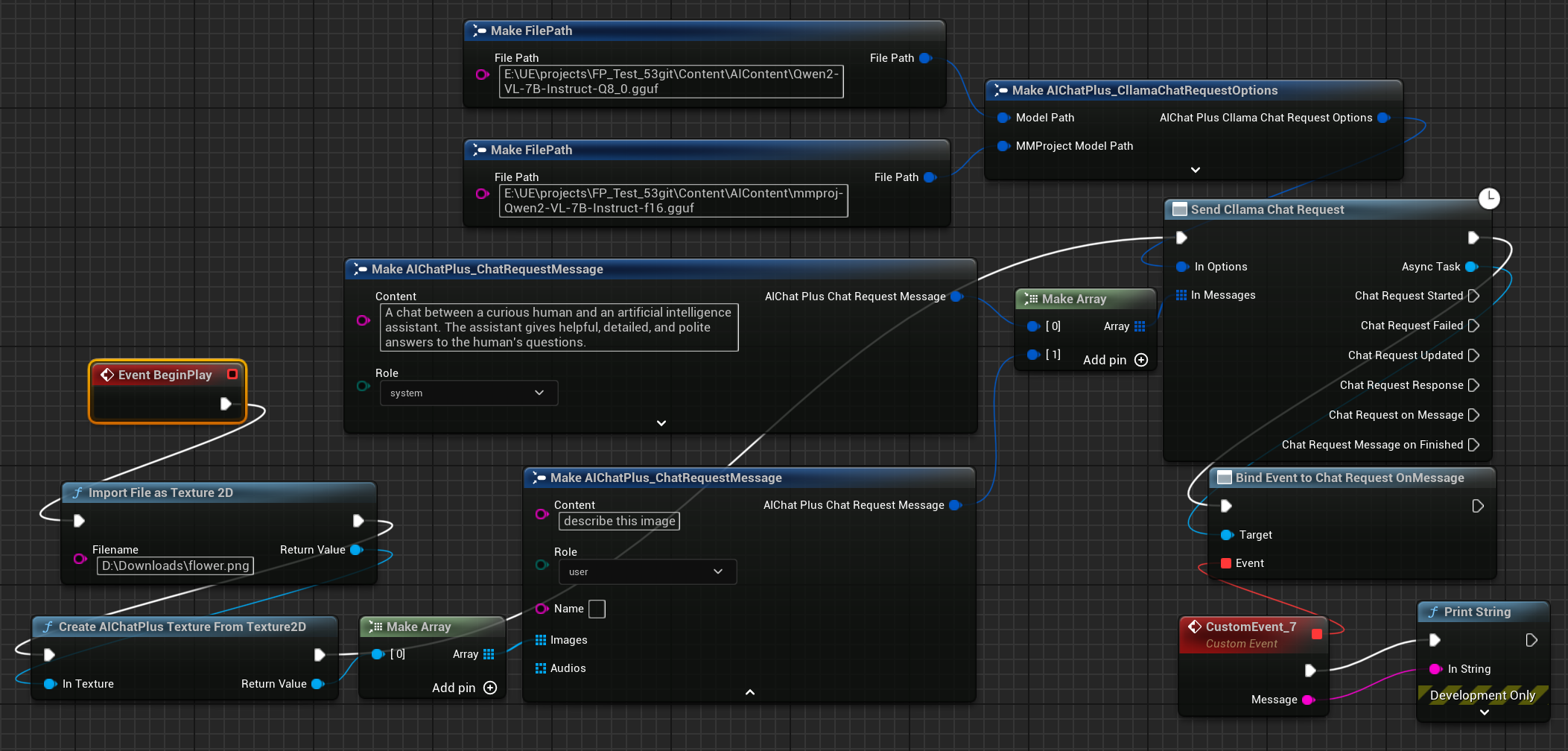
最后创建节点接受返回的信息,并打印到屏幕上,完整的蓝图看起来是这样的
运行蓝图可看到返回的文字

llama.cpp 使用 GPU
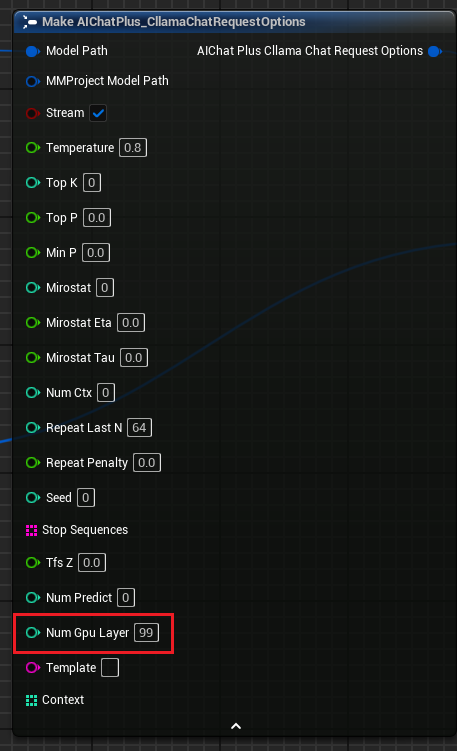
"Cllama Chat Request Options" 增加参数 "Num Gpu Layer" ,可以设置 llama.cpp 的 gpu payload,可以控制需要在 GPU 上计算的层数。如图
KeepAlive
"Cllama Chat Request Options" 增加参数 "KeepAlive",可以让读取后的模型文件保留在内存中,方便下次直接使用,减少读取模型的次数。KeepAlive 是模型保留的时间,0 表示不保留,使用后立即释放;-1 表示永久保留。每次请求设置的 Options 都可以设置不同的 KeepAlive,新的 KeepAlive 会替代旧的数值,譬如前几次的请求可以设置 KeepAlive=-1,让模型保留在内存中,直到最后一次的请求设置 KeepAlive=0,释放模型文件。
处理打包后 .Pak 中的模型文件
开启 Pak 打包后,项目的所有资源文件都会放在 .Pak 文件中,当然也包含了离线模型 gguf 文件。
由于 llama.cpp 无法支持直接读取 .Pak 文件,因此需要把 .Pak 文件中的离线模型文件拷贝出来文件系统中。
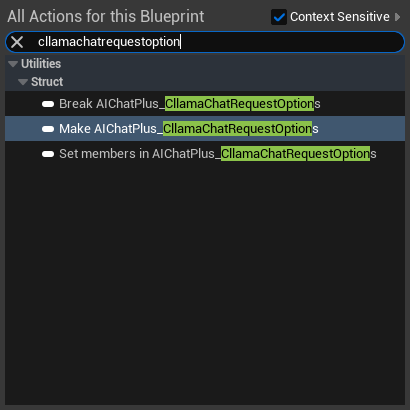
AIChatPlus 提供了一个功能函数可以自动把 .Pak 中的模型文件拷贝处理,并放在 Saved 文件夹中:
又或者你可以自己处理 .Pak 中的模型文件,关键就是需要把文件复制出来,因为 llama.cpp 无法正确读取 .Pak。
功能节点
Cllama 提供了一些功能节点方便获取当前环境下状态
"Cllama Is Valid":判断 Cllama llama.cpp 是否正常初始化

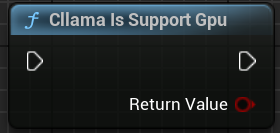
"Cllama Is Support Gpu":判断 llama.cpp 在当前环境下是否支持 GPU backend
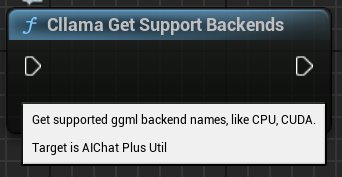
"Cllama Get Support Backends": 获取当前 llama.cpp 支持的所有 backends
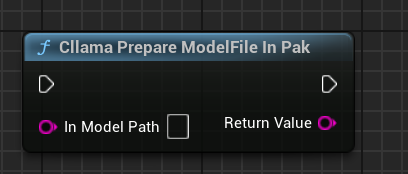
"Cllama Prepare ModelFile In Pak": 自动把 Pak 中的模型文件复制到文件系统中

原文地址:https://wiki.disenone.site
本篇文章受 CC BY-NC-SA 4.0 协议保护,转载请注明出处。
Visitors. Total Visits. Page Visits.