藍圖篇 - Cllama (llama.cpp)(已廢棄)
已廢棄
Cllama 已被標記為廢棄,不再維護。
Cllama 的原有功能由 CllamaServer來承載。
離線模型
Cllama 是基於 llama.cpp 來實現的,支援離線使用 AI 推理模型。
由於是離線狀態,我們需要預先準備好模型檔案,例如從HuggingFace網站下載離線模型:Qwen1.5-1.8B-Chat-Q8_0.gguf
將模型放置在特定資料夾內,例如遊戲專案的目錄 Content/LLAMA 下
有了離線模型檔案之後,我們就可以透過 Cllama 來進行 AI 聊天
文字聊天
使用 Cllama 進行文本聊天
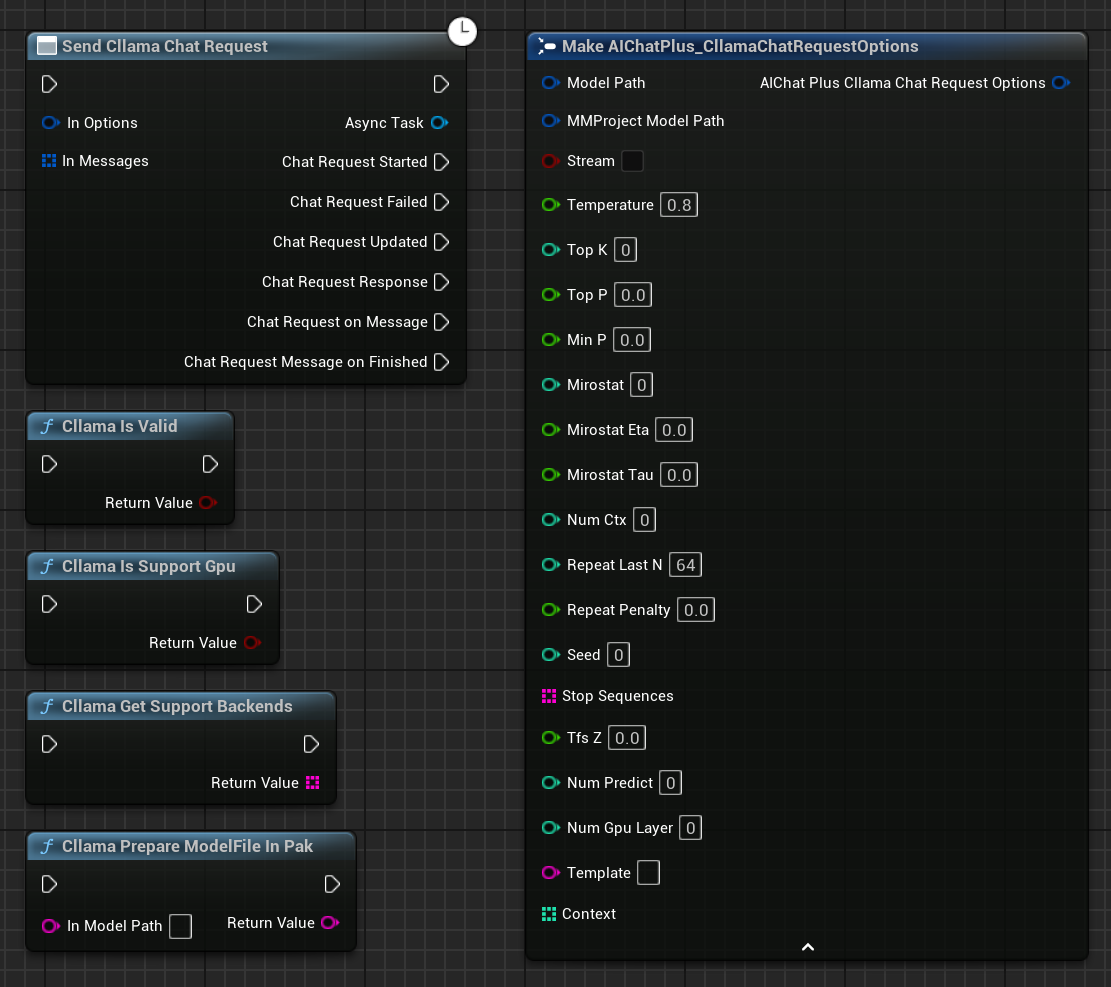
在藍圖中右鍵創建一個節點 Send Cllama Chat Request
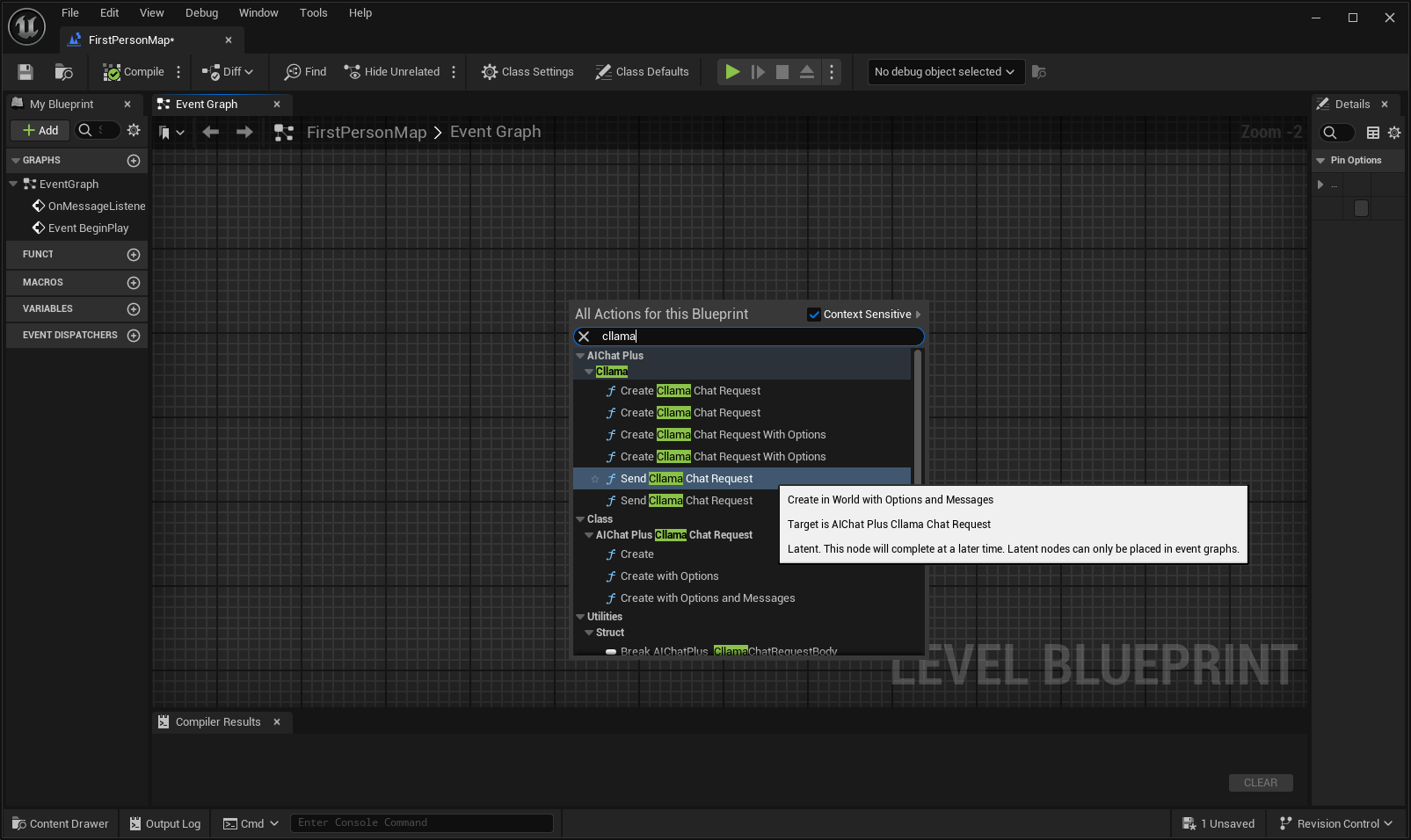
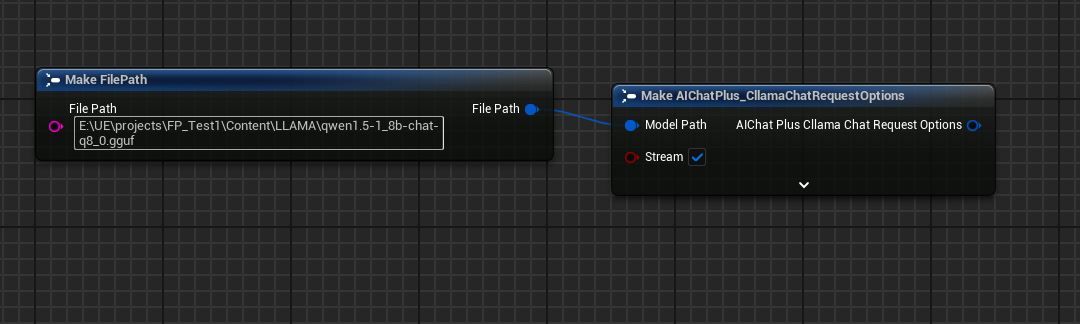
創建 Options 節點,並設定 Stream=true, ModelPath="E:\UE\projects\FP_Test1\Content\LLAMA\qwen1.5-1_8b-chat-q8_0.gguf"
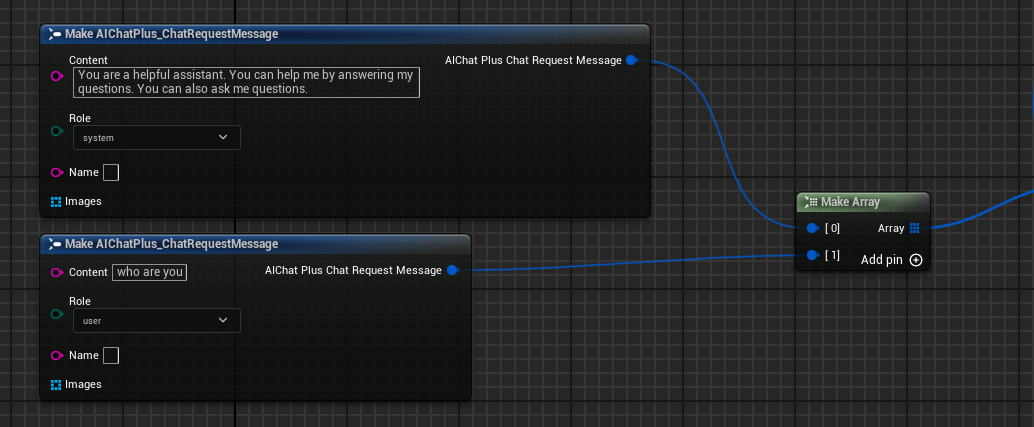
建立 Messages,分別新增一條 System Message 和一條 User Message
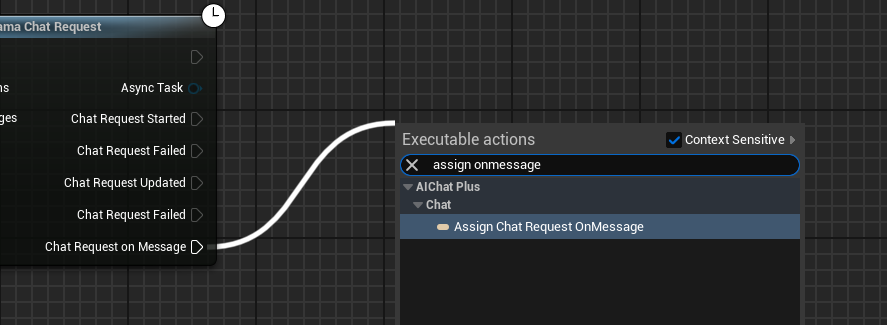
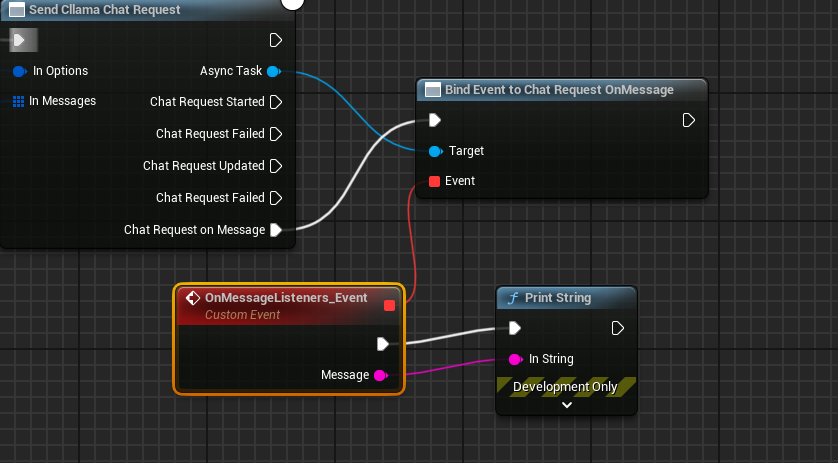
建立 Delegate 接收模型輸出的資訊,並顯示在畫面上
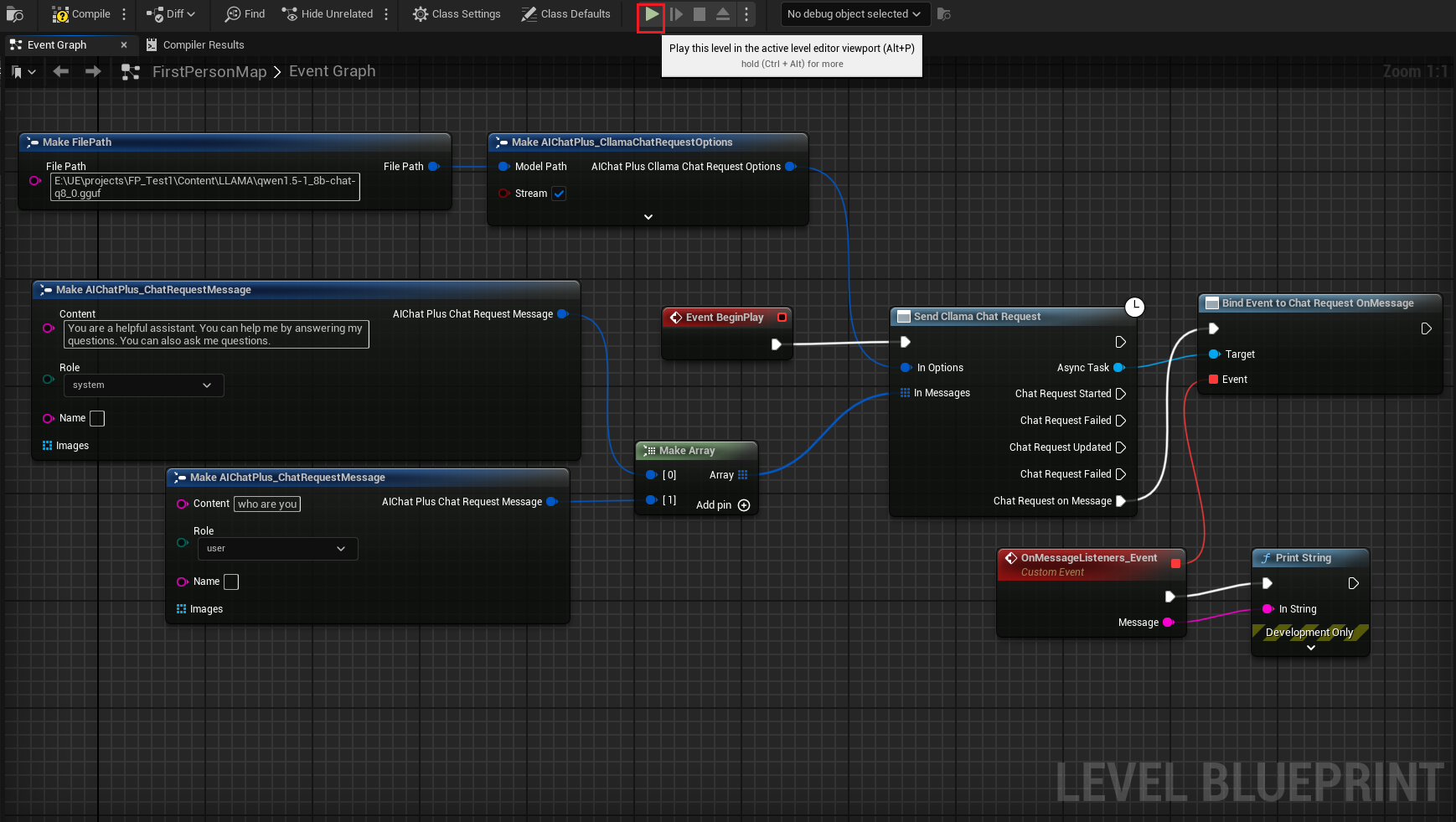
完整的藍圖看起來是這樣的,運行藍圖,即可看到遊戲螢幕在打印大模型返回的消息
圖片生成文字 llava
Cllama 還實驗性地支援了 llava 庫,提供了視覺化的能力
首先準備好Multimodal離線模型檔案,例如Moondream(moondream2-text-model-f16.gguf, moondream2-mmproj-f16.gguf)或者 Qwen2-VL(Qwen2-VL-7B-Instruct-Q8_0.gguf, mmproj-Qwen2-VL-7B-Instruct-f16.gguf或者其他 llama.cpp 支援的多模態模型。
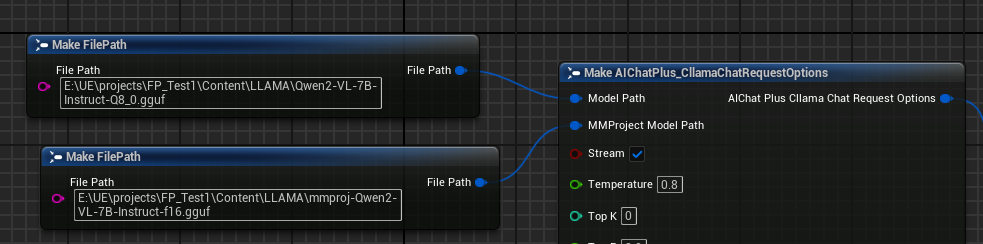
創建 Options 節點,分別設置參數 "Model Path" 和 "MMProject Model Path" 為對應的 Multimodal 模型檔案。
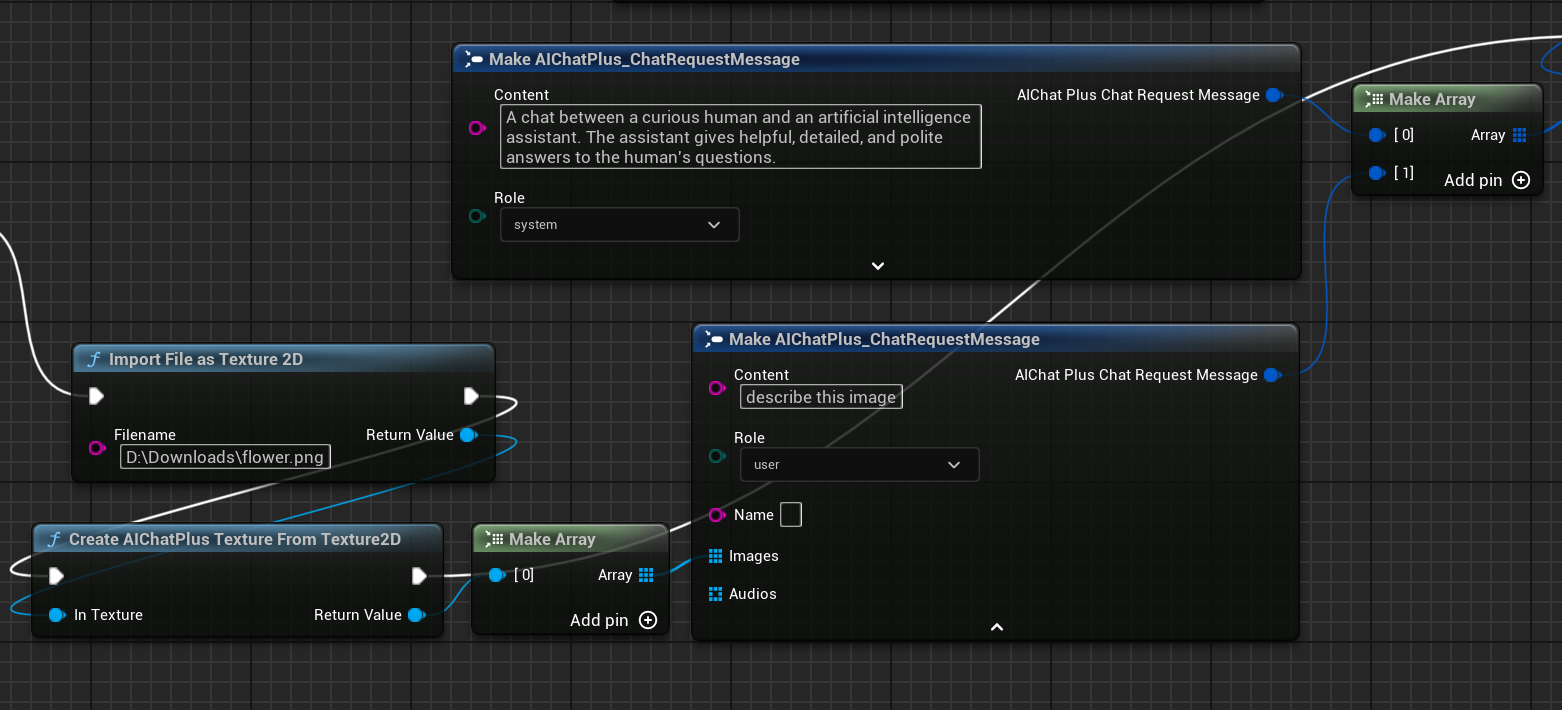
創建節點讀取圖片檔案 flower.png,並設定 Messages

最後創建節點接收返回的資訊,並列印到螢幕上,完整的藍圖看起來是這樣的
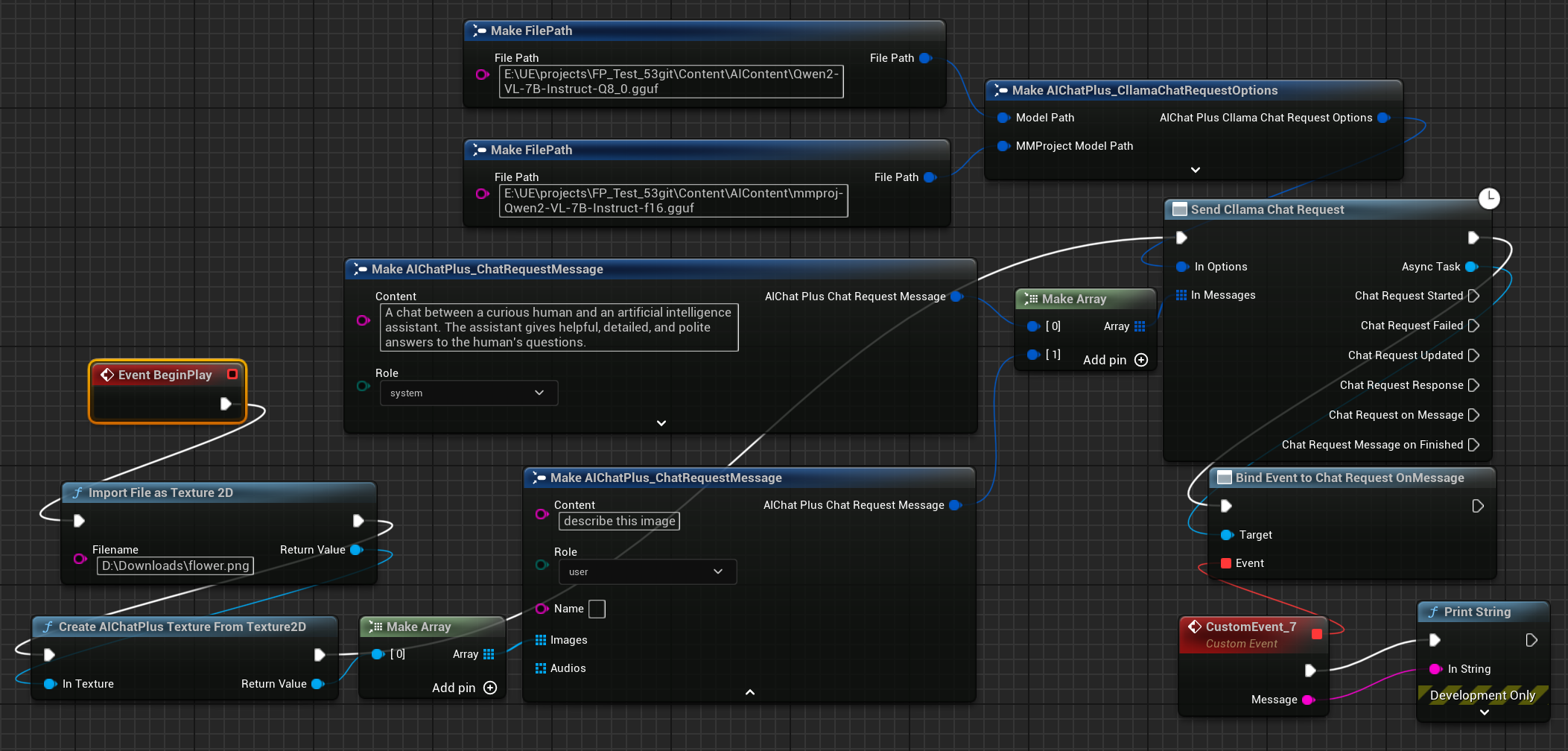
執行藍圖即可看到回傳的文字

llama.cpp 使用 GPU
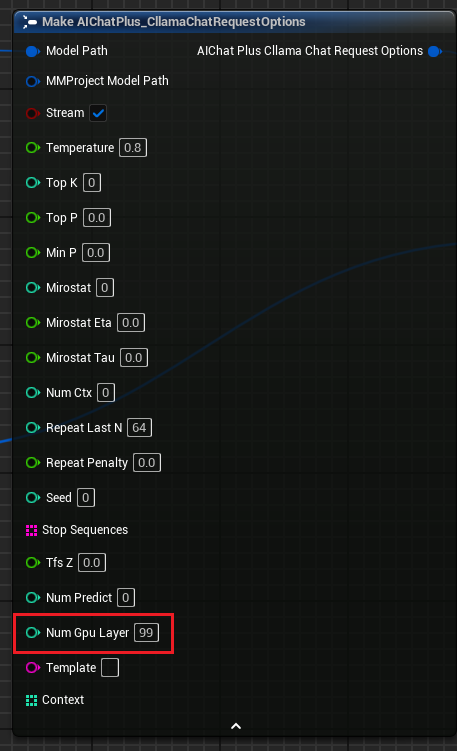
"Cllama Chat 請求選項" 新增參數 "Num Gpu Layer",可用於設定 llama.cpp 的 GPU 負載,控制需要在 GPU 上計算的層數。如圖
KeepAlive
"Cllama Chat 請求選項" 新增一個參數 "KeepAlive",能夠讓讀取後的模型檔案保留在記憶體中,便於下次直接使用,減少重複讀取模型的次數。KeepAlive 代表模型保留的時間長度,設定為 0 表示不保留,使用後立即釋放;設定為 -1 則表示永久保留。每次請求所設定的 Options 都可以獨立調整 KeepAlive 值,新的 KeepAlive 設定會覆蓋先前的數值。舉例來說,前面的幾次請求可以設 KeepAlive=-1,使模型持續駐留於記憶體,直到最後一次請求時設定 KeepAlive=0,此時便會釋放模型檔案。
處理打包後的 .Pak 中的模型檔案
開啟 Pak 打包後,專案的所有資源檔案都會放在 .Pak 檔案中,當然也包含了離線模型 gguf 檔案。
由於 llama.cpp 無法直接讀取 .Pak 檔案,因此需將 .Pak 檔案中的離線模型檔案複製到檔案系統中。
AIChatPlus 提供了一個功能函數,能夠自動將 .Pak 中的模型文件複製並處理,然後存放在 Saved 資料夾中:
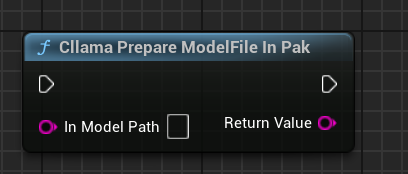
或者你也可以自行處理.Pak中的模型文件,關鍵在於將文件複製出來,因為llama.cpp無法正確讀取.Pak。
功能節點
Cllama 提供了一些功能節點,方便獲取當前環境下的狀態。
「Cllama 是否有效」:檢測 Cllama llama.cpp 是否正確初始化

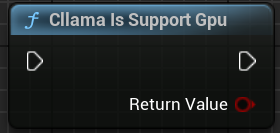
"Cllama 是否支援 GPU":檢查 llama.cpp 在當前環境下是否支援 GPU 後端
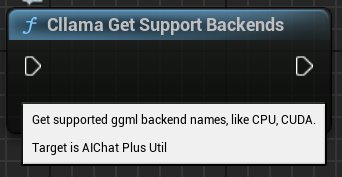
「Cllama 取得支援後端」:獲取當前 llama.cpp 支援的所有後端
「Cllama準備模型檔案於Pak中」:自動將Pak裡的模型檔案複製到檔案系統內

Original: https://wiki.disenone.site/tc
This post is protected by CC BY-NC-SA 4.0 agreement, should be reproduced with attribution.
Visitors. Total Visits. Page Visits.
此貼文是使用 ChatGPT 翻譯的,請在意見回饋指出任何遺漏之處。